
Build your own data warehouse with DuckDB, DBT, and Modal
This example contains a minimal but capable data warehouse. It’s comprised of the following:
Meet your new serverless cloud data warehouse, powered by Modal!
Configure Modal, S3, and DBT
The only thing in the source code that you must update is the S3 bucket name. AWS S3 bucket names are globally unique, and the one in this source is used by us to host this example.
Update the BUCKET_NAME variable below and also any references to the original value
within sample_proj_duckdb_s3/models/. The AWS IAM policy below also includes the bucket
name and that must be updated.
from pathlib import Path
import modal
BUCKET_NAME = "modal-example-dbt-duckdb-s3"
LOCAL_DBT_PROJECT = ( # local path
Path(__file__).parent / "sample_proj_duckdb_s3"
)
PROJ_PATH = "/root/dbt" # remote paths
PROFILES_PATH = "/root/dbt_profile"
TARGET_PATH = "/root/target"Most of the DBT code and configuration is taken directly from the classic Jaffle Shop demo and modified to support
using dbt-duckdb with an S3 bucket.
The DBT profiles.yml configuration is taken from the dbt-duckdb docs.
We also define the environment our application will run in — a container image, as in Docker. See this guide for details.
dbt_image = ( # start from a slim Linux image
modal.Image.debian_slim(python_version="3.11")
.uv_pip_install( # install python packages
"boto3~=1.34", # aws client sdk
"dbt-duckdb~=1.8.1", # dbt and duckdb and a connector
"pandas~=2.2.2", # dataframes
"pyarrow~=16.1.0", # columnar data lib
"fastapi[standard]~=0.115.4", # web app
)
.env( # configure DBT environment variables
{
"DBT_PROJECT_DIR": PROJ_PATH,
"DBT_PROFILES_DIR": PROFILES_PATH,
"DBT_TARGET_PATH": TARGET_PATH,
}
)
# Here we add all local code and configuration into the Modal Image
# so that it will be available when we run DBT on Modal.
.add_local_dir(LOCAL_DBT_PROJECT, remote_path=PROJ_PATH)
.add_local_file(
LOCAL_DBT_PROJECT / "profiles.yml",
remote_path=f"{PROFILES_PATH}/profiles.yml",
)
)
app = modal.App(name="example-dbt-duckdb", image=dbt_image)
dbt_target = modal.Volume.from_name("dbt-target-vol", create_if_missing=True)We’ll also need to authenticate with AWS to store data in S3.
s3_secret = modal.Secret.from_name(
"modal-examples-aws-user",
required_keys=["AWS_ACCESS_KEY_ID", "AWS_SECRET_ACCESS_KEY", "AWS_REGION"],
)Create this Secret using the “AWS” template from the Secrets dashboard.
Below we will use the provided credentials in a Modal Function to create an S3 bucket and
populate it with .parquet data, so be sure to provide credentials for a user
with permission to create S3 buckets and read & write data from them.
The policy required for this example is the following. Not that you must update the bucket name listed in the policy to your own bucket name.
{
"Statement": [
{
"Action": "s3:*",
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::modal-example-dbt-duckdb-s3/*",
"arn:aws:s3:::modal-example-dbt-duckdb-s3"
],
"Sid": "duckdbs3access"
}
],
"Version": "2012-10-17"
}Upload seed data
In order to provide source data for DBT to ingest and transform,
we have the below create_source_data function which creates an AWS S3 bucket and
populates it with Parquet files based off the CSV data in the seeds/ directory.
You can kick it off by running this script on Modal:
modal run dbt_duckdb.pyThis script also runs the full data warehouse setup, and the whole process takes a minute or two.
We’ll walk through the rest of the steps below. See the app.local_entrypoint below for details.
Note that this is not the typical way that seeds/ data is used, but it’s useful for this
demonstration. See the DBT docs for more info.
@app.function(
secrets=[s3_secret],
)
def create_source_data():
import boto3
import pandas as pd
from botocore.exceptions import ClientError
s3_client = boto3.client("s3")
s3_client.create_bucket(Bucket=BUCKET_NAME)
for seed_csv_path in Path(PROJ_PATH, "seeds").glob("*.csv"):
print(f"Found seed file {seed_csv_path}")
name = seed_csv_path.stem
parquet_filename = f"{name}.parquet"
object_key = f"sources/{parquet_filename}"
try:
s3_client.head_object(Bucket=BUCKET_NAME, Key=object_key)
print(
f"File '{object_key}' already exists in bucket '{BUCKET_NAME}'. Skipping."
)
except ClientError:
df = pd.read_csv(seed_csv_path)
df.to_parquet(parquet_filename)
print(f"Uploading '{object_key}' to S3 bucket '{BUCKET_NAME}'")
s3_client.upload_file(parquet_filename, BUCKET_NAME, object_key)
print(f"File '{object_key}' uploaded successfully.")Run DBT on the cloud with Modal
Modal makes it easy to run Python code in the cloud.
And DBT is a Python tool, so it’s easy to run DBT with Modal:
below, we import the dbt library’s dbtRunner to pass commands from our
Python code, running on Modal, the same way we’d pass commands on a command line.
Note that this Modal Function has access to our AWS S3 Secret, the local files associated with our DBT project and profiles, and a remote Modal Volume that acts as a distributed file system.
@app.function(
secrets=[s3_secret],
volumes={TARGET_PATH: dbt_target},
)
def run(command: str) -> None:
from dbt.cli.main import dbtRunner
res = dbtRunner().invoke(command.split(" "))
if res.exception:
print(res.exception)You can run this Modal Function from the command line with
modal run dbt_duckdb.py::run --command run
A successful run will log something like the following:
03:41:04 Running with dbt=1.5.0
03:41:05 Found 5 models, 8 tests, 0 snapshots, 0 analyses, 313 macros, 0 operations, 3 seed files, 3 sources, 0 exposures, 0 metrics, 0 groups
03:41:05
03:41:06 Concurrency: 1 threads (target='modal')
03:41:06
03:41:06 1 of 5 START sql table model main.stg_customers ................................ [RUN]
03:41:06 1 of 5 OK created sql table model main.stg_customers ........................... [OK in 0.45s]
03:41:06 2 of 5 START sql table model main.stg_orders ................................... [RUN]
03:41:06 2 of 5 OK created sql table model main.stg_orders .............................. [OK in 0.34s]
03:41:06 3 of 5 START sql table model main.stg_payments ................................. [RUN]
03:41:07 3 of 5 OK created sql table model main.stg_payments ............................ [OK in 0.36s]
03:41:07 4 of 5 START sql external model main.customers ................................. [RUN]
03:41:07 4 of 5 OK created sql external model main.customers ............................ [OK in 0.72s]
03:41:07 5 of 5 START sql table model main.orders ....................................... [RUN]
03:41:08 5 of 5 OK created sql table model main.orders .................................. [OK in 0.22s]
03:41:08
03:41:08 Finished running 4 table models, 1 external model in 0 hours 0 minutes and 3.15 seconds (3.15s).
03:41:08 Completed successfully
03:41:08
03:41:08 Done. PASS=5 WARN=0 ERROR=0 SKIP=0 TOTAL=5Look for the 'materialized='external' DBT config in the SQL templates
to see how dbt-duckdb is able to write back the transformed data to AWS S3!
After running the run command and seeing it succeed, check what’s contained
under the bucket’s out/ key prefix. You’ll see that DBT has run the transformations
defined in sample_proj_duckdb_s3/models/ and produced output .parquet files.
Serve fresh data documentation with FastAPI and Modal
DBT also automatically generates rich, interactive data docs. You can serve these docs on Modal. Just define a simple FastAPI app:
@app.function(volumes={TARGET_PATH: dbt_target})
@modal.concurrent(max_inputs=100)
@modal.asgi_app() # wrap a function that returns a FastAPI app in this decorator to host on Modal
def serve_dbt_docs():
import fastapi
from fastapi.staticfiles import StaticFiles
web_app = fastapi.FastAPI()
web_app.mount(
"/",
StaticFiles( # dbt docs are automatically generated and sitting in the Volume
directory=TARGET_PATH, html=True
),
name="static",
)
return web_appAnd deploy that app to Modal with
modal deploy dbt_duckdb.py
# ...
# Created web function serve_dbt_docs => <output-url>If you navigate to the output URL, you should see something like 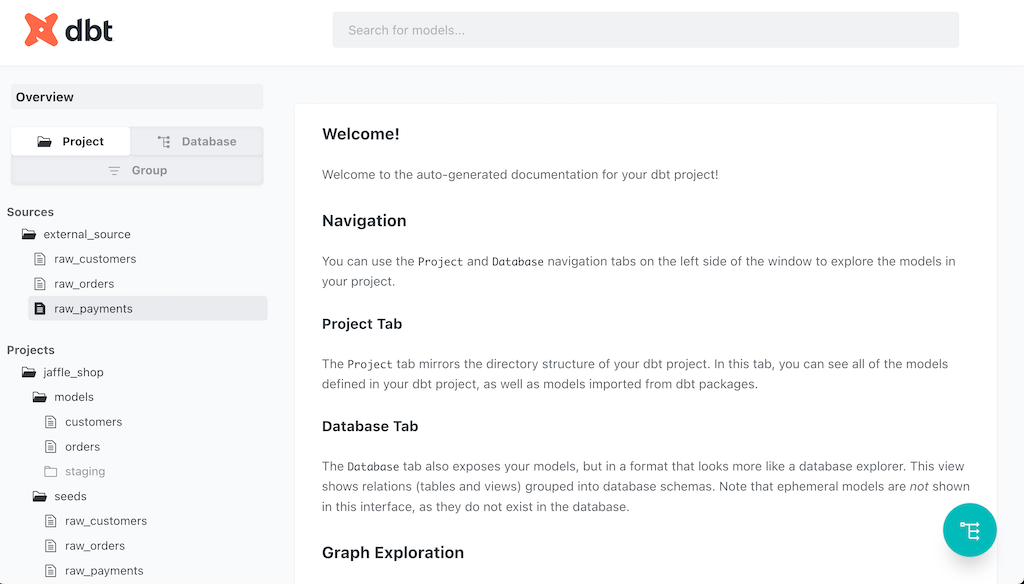
You can also check out our instance of the docs here. The app will be served “serverlessly” — it will automatically scale up or down during periods of increased or decreased usage, and you won’t be charged at all when it has scaled to zero.
Schedule daily updates
The following daily_build function runs on a schedule to keep the DuckDB data warehouse up-to-date. It is also deployed by the same modal deploy command for the docs app.
The source data for this warehouse is static, so the daily executions don’t really “update” anything, just re-build. But this example could be extended to have sources which continually provide new data across time. It will also generate the DBT docs daily to keep them fresh.
@app.function(
schedule=modal.Period(days=1),
secrets=[s3_secret],
volumes={TARGET_PATH: dbt_target},
)
def daily_build() -> None:
run.remote("build")
run.remote("docs generate")
@app.local_entrypoint()
def main():
create_source_data.remote()
run.remote("run")
daily_build.remote()