Introducing Modal Auto Endpoints: Optimized inference you actually own
Modal allows leading teams like Cognition, Decagon, Fathom, and DoorDash to own their inference without compromising on cost-performance or developer velocity.
Now you can do the same with a single command:
modal endpoint create --name agent --model zai-org/GLM-5.2-FP8Introducing Modal Auto Endpoints: a smooth, self-serve on-ramp to production-grade LLM inference.
Take it for a spin right now, or read on to learn more about how we built it and why.
Built for the era of actually owning your inference
Proprietary model providers can silently degrade models or suddenly retract access. If you don't own your inference, you don't own your destiny.
If you work with open models served by an inference provider, you gain some control. But we think ownership runs deeper than the API. To actually own your inference, you need to own, understand, and optimize the code that runs the inference.
Managed inference providers make it easy to get an API, but the serving stack is a black box. So until now, teams that wanted proper ownership of their inference have had only one option: roll an inference service yourself. That gives you control, but now you own a lot more than just inference: engine tuning, endpoint benchmarking, container deployment, replica autoscaling & routing, and inference metrics.
That's why we built Modal Auto Endpoints, and why they look very different from what's offered by traditional inference providers.
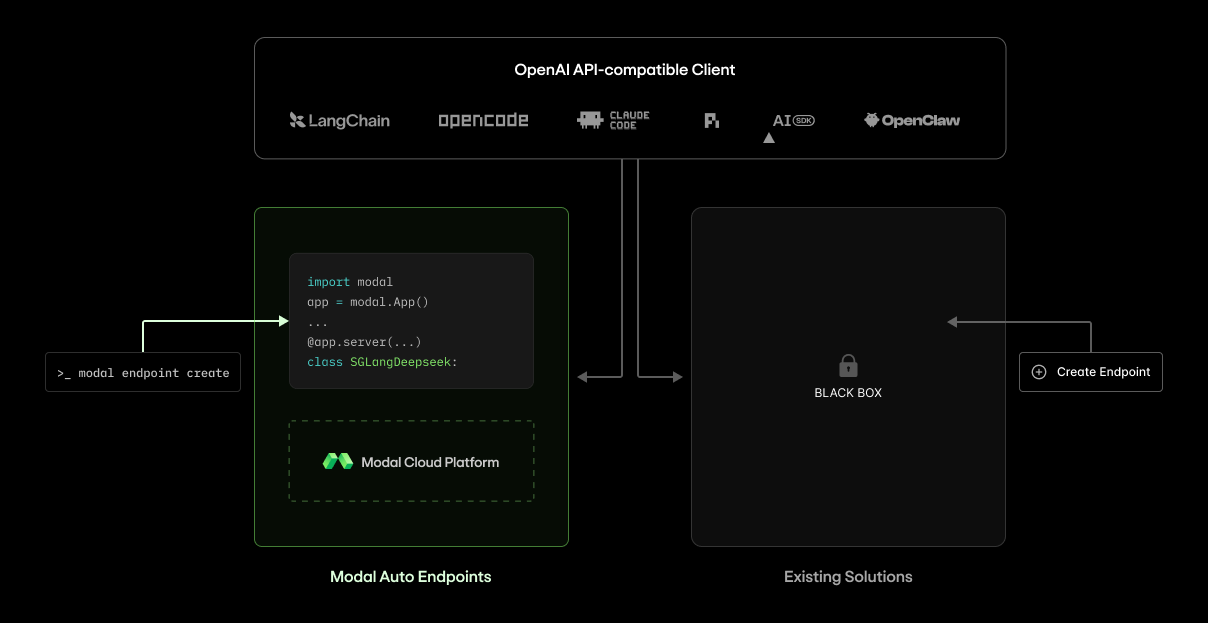
A Modal Endpoint is an OpenAI API-compatible, production-ready service, backed by a Modal App that you can see and control.
There are three key differences in this approach:
- We don't hide the code. Everything from GPU selection and regionalization to inference engine flags and the occasional cutty engine patch is shared with you.
- We don't hide the metrics. The metrics you actually need to debug inference issues, like speculative decoding acceptance length and per-replica, engine-side token latency quantiles, are automatically provided in a dashboard. Low bar, but we didn't put it there!
- We don't hide behind a "talk to sales" button. You can deploy frontier open models like GLM 5.2 with a CLI command or clickops, not a Zoom call. Our line is always open if you want additional expertise.
Infrastructure built for inference
We can deliver all of this because we are building on a rock-solid foundation: Modal's AI infrastructure platform.
Our users build on this platform to fold proteins, drive robots, and make music. The same fundamental components that work there also work for LLM inference, hand-rolled or via Auto Endpoints.
With Modal, you don’t need to reserve months of expensive GPU capacity to handle load you can’t estimate. Instead, you pay for what you use, as you use it, and scale to meet demand with our high-performance autoscaling system and custom container runtime. You can use GPUs around the world, or close to your users, without worrying about capacity management. That’s our calling card, and that’s not changing.
We’ve also added and released from beta a new fundamental component to our system to support the demands of low latency inference: Modal Servers for ultra-low-latency routing.
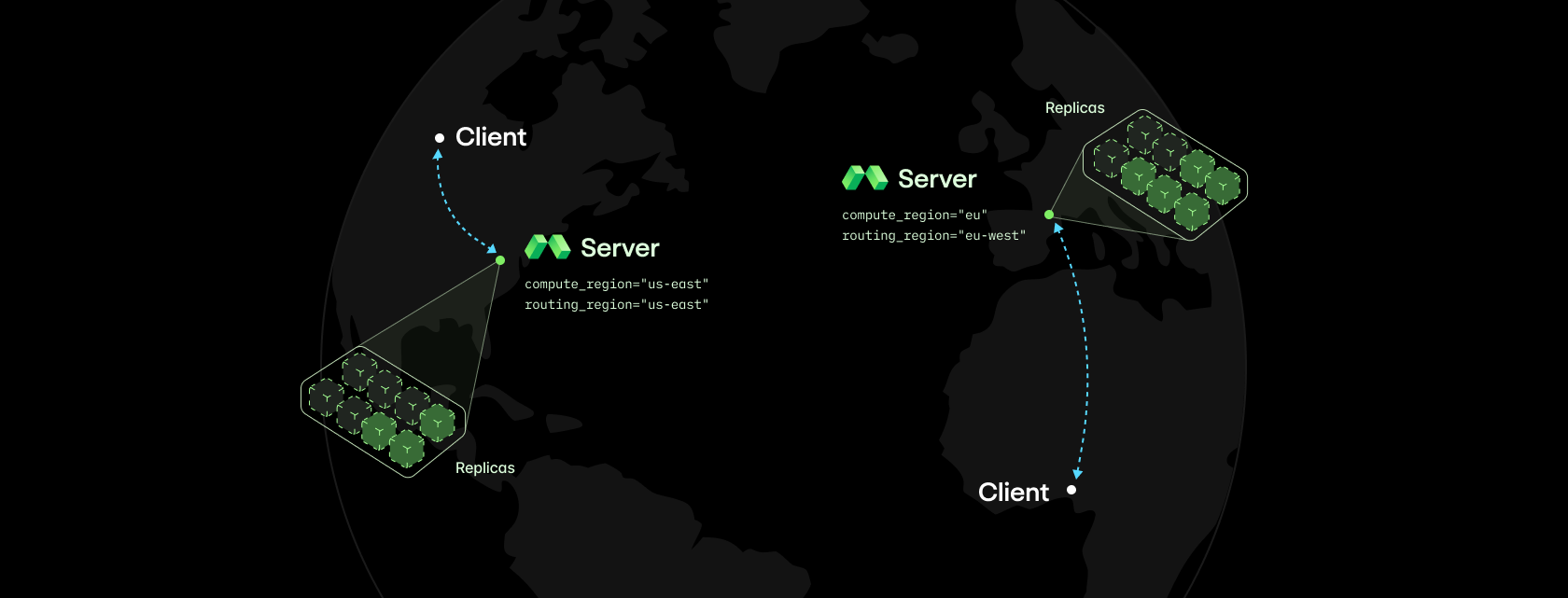
Modal Servers keep the elastic scaling and deep compute capacity of Modal Web Functions. But they remove queueing and are regionalized by default so that you can serve HTTP requests on Modal with only 5ms overhead -- without compromising on reliability and autoscaling. More on how we built that later this week.
High performance inference code with a click, not a grind
Inference engines are akin to database management systems like PostgreSQL: complex, mission-critical software that must perform at the limits of the hardware. As with databases, this software has complex internals exposed by multitudinous knobs, and achieving the best performance possible requires learning to tune those knobs.
That’s a tough grind. When a team is looking to own inference but used to building on proprietary model APIs, it is tempting to keep the API layer abstraction and outsource inference performance concerns to proprietary wrappers of open-weights models.
Auto Endpoints give you the best of both worlds: performance, effortlessly. For each supported model, we provide a starting deployment informed by our experience with teams building some of the most demanding AI products in the world. You don't need to specify GPU types or monkey around with engine flags like --mamba-scheduler-strategy or --flashinfer-mxfp4-moe-precision until you're ready, making bespoke optimizations for your workload.
We developed these recipes in direct competition with proprietary inference providers. We won by betting on open source — patching and upstreaming improvements to underlying inference engines like SGLang and kernels like FlashAttention-4 as necessary — and by going all-in on speculative decoding.
In particular, we like the DFlash block-diffusion drafter architecture from Z Lab, and we use it with every compatible model. We’ve worked closely with Z Lab and the SGLang team to make DFlash fast and reliable in real serving systems, and we trained and released our own DFlash drafter models to expand support and to make sure they deliver optimal performance.
We expose our benchmarking results to you as you set up your Endpoint:
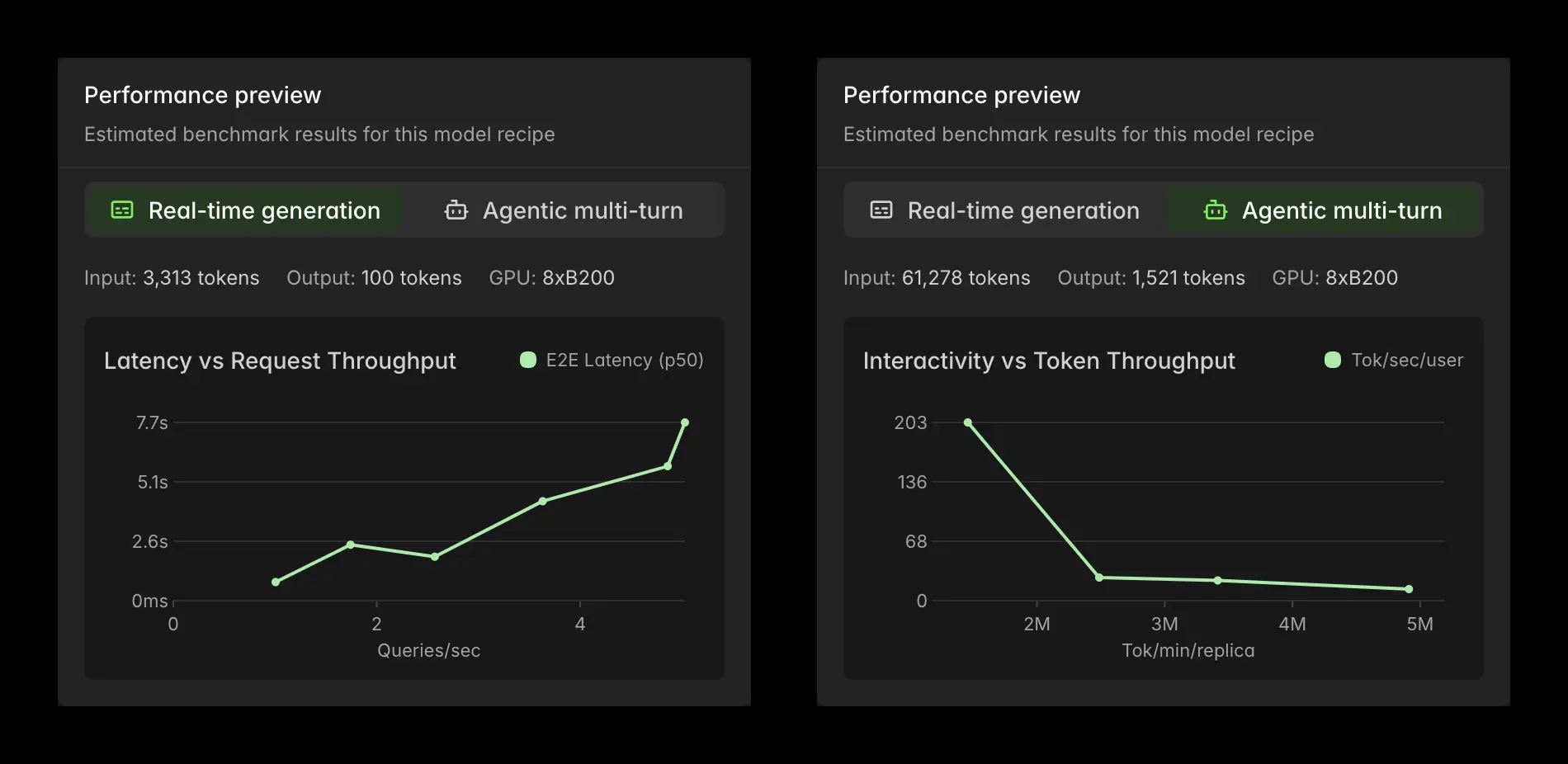
Once the Endpoint is deployed, you can test it with a click, review latency and throughput tradeoffs, and see how the entire autoscaling, multi-replica service behaves under load.
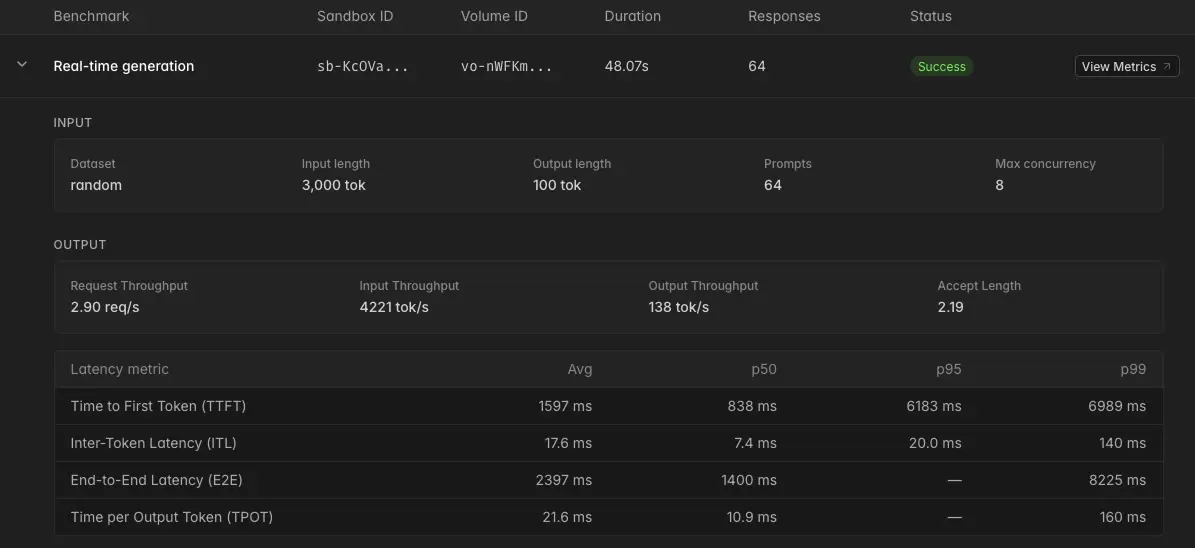
Of course, there is no universal configuration for inference. A low-latency classification endpoint and a multi-turn agentic loop do not want the same serving setup. Modal Auto Endpoints start you at the configuration we’d start from before pulling traces: clean, inspectable, benchmarked, and ready to tune against a workload.
Engine-level observability
Performance on a benchmark is not enough. Performance in production needs to be observable. Owning your inference means being able to see all the way down into the engines so that you can improve performance and root-cause application issues.
Modal provides metrics (in-Dashboard and via OTEL export) to understand endpoint performance, broken into two groups:
- Server Metrics: the traditional Modal App metrics, including GPU temperature, power, and utilization
- Inference Metrics: standard metrics exported by the inference engines, like time-to-first-token (TTFT), inter-token latency (ITL), queueing, and speculative decoding acceptance length
Server metrics go far deeper than any inference service provider will expose. But even for inference metrics, we offer much more detail. Here’s a sample dashboard showing a vision-language model Endpoint handling a large (relative to baseline) traffic spike.
Let’s walk through what it shows.
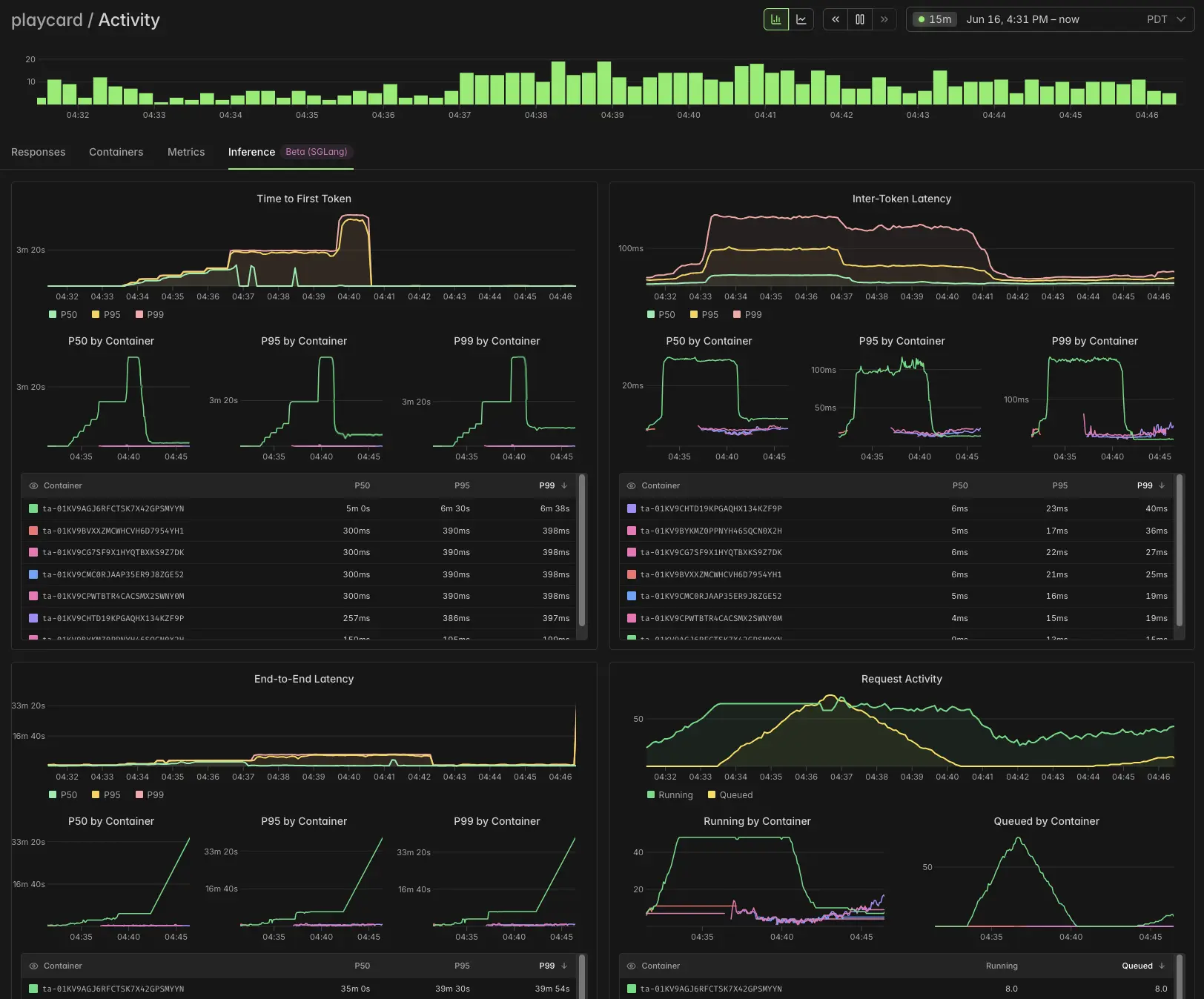
As load increases, the single container handling the baseline load (green in container charts) evinces ever-increasing TTFT (top-left; caused by prefills queueing) followed by elevated ITLs (top-right; caused by decodes queueing). The result is increased end-to-end latency (bottom left).
Two additional replicas are automatically spun up by Modal’s autoscaling system. The queue shrinks (bottom-right) and latencies return to acceptable levels — no PagerDuty ping, just infrastructure and automation.
Going "Full Auto": start great and continually improve
We designed Auto Endpoints with a declarative interface, based on workloads and SLOs. That interface is derived from how we think about benchmarking and optimizing inference services with and for our customers. We’ve learned this from years of working with top teams on inference deployments.
But we didn’t design it looking backwards. We designed it looking forwards, towards a future where the engineering of inference endpoints is fully automated.
We started off writing the code for Endpoints deployments by hand — or as “by hand” as software engineering is done these days. We now produce them with an internal autoresearch-style agentic system that knows how to configure inference engines and hill-climb on performance while maintaining correctness and quality. More on that later this week.
For now, that agentic system is still monitored by human engineers to ensure that we deliver only production-grade inference code to power your Endpoints. But the trajectory of improvement for software engineering by artificial intelligences is clear, and we’re skating where that puck is going.
For instance, our speculator models are good (eg >4x faster than baseline and >1.5x faster than other speculators on multiple benchmarks). But they are also generic — trained to guess outputs from the target model handling a broad suite of tasks. Speculators become much, much better when trained on the data they (and the target model) will see in production.
We train custom speculators with some of our most sophisticated and latency-sensitive users. More on that later this week as well. But we don’t want to bottleneck inference performance improvement on human engineers kicking off and babysitting training runs. We’re also developing automated detection of opportunities to retrain speculators and automated training pipelines to take advantage of them.
The terminal state we see for Auto Endpoints — as for other optimization-amenable software engineering tasks — includes all these levels of automation:
autoinference: configure, patch, and benchmark inference serversautospec: create and update speculator models based on synthetic and production dataautodistill: distill capabilities from deployed models into smaller, faster modelsautoresearch: develop performance features, inference engines, and even models
All built on what we built first: autoscaling infrastructure. That’s what compounding looks like.
Try it now
Click here to take ownership of your inference with Modal Auto Endpoints.