Kimi K3 is live. Try the new Shared API with token-based pricing Learn more
Modal Core Platform
Cloud infrastructure designed for AI workloads
Every layer of Modal’s platform is engineered to give you the tools to build robust, scalable data applications.
Fast cold starts. Faster feedback loops.
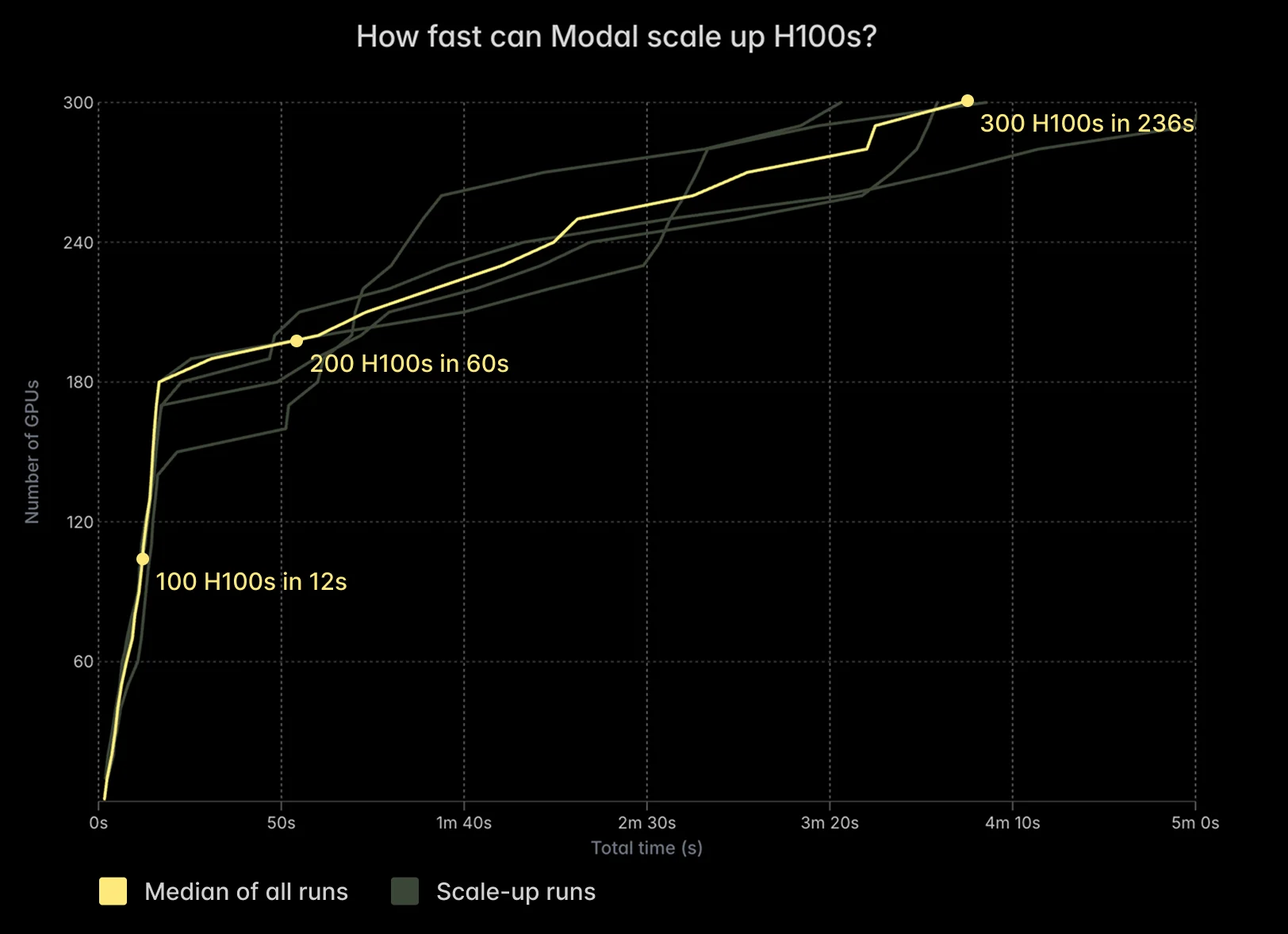
Scale to 1000+ GPUs in minutes. Then back down to zero.

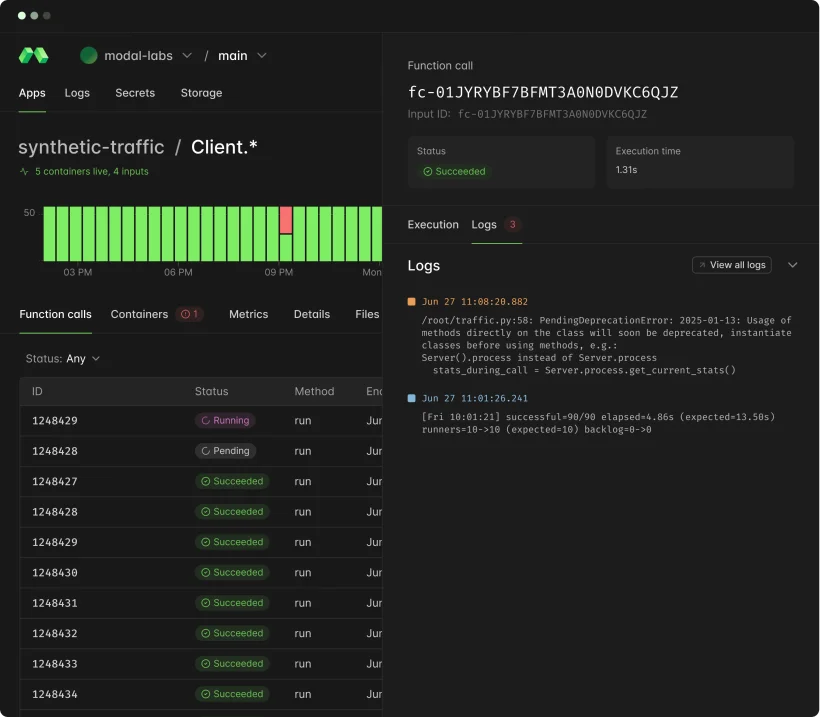
Observability as a first-class feature.