Autoscaling Autoresearch: Give your agents elastic GPUs on Modal
Following Karpathy-san’s banger release of autoresearch, many are embracing the use of AI to accelerate AI research.
But autoresearch introduces a new version of a familiar problem: how do you give research the compute it needs without wasting money on compute it doesn’t?
Modal fixes this. To demonstrate, Tony handed Claude Code some relevant Modal Skills, pointed it at OpenAI's Parameter Golf challenge, and went to sleep.
When he woke up 15 hours later, it had run 113 experiments across 238 GPU-hours, finishing the core training runs 5x faster than a single workstation would while using a fraction of the resources of a dedicated cluster.
Autoresearch 💚 Autoscaling
Research is unpredictable, and so are research workloads. A researcher, or their agent, might need dozens or hundreds of GPUs in parallel for a hyperparameter sweep, then drop to one GPU to debug an issue, then scale back up to several 8-GPU clusters for validation — all within the same work session.
A big always-on reservation gives you that burst capacity, but it's expensive: you're paying for a cluster even while the agent is “Thinking…”, not using it. And most clusters are hard to use. A single instance or workstation is cheap and easy to use, but it forces experiments to run serially, tanking your iteration speed.
What you really want is the best of both worlds: the ease-of-use and cost control of a single machine with the burst capacity of a thicc cluster.
And it's not just how much compute, it's also what kind. Debugging a CUDA error calls for an interactive sandbox where the agent can inspect state and iterate quickly. A 12-hour training run calls for a fault-tolerant batch job with retries and checkpointing. A hyperparameter sweep calls for dozens of independent jobs running in parallel.
Traditional cloud infrastructure forces you and your agent to pick one mode and stick with it. What you really want is for the agent itself to decide both how much compute and what kind of compute to use, moment to moment, and have the infrastructure follow.
That's what Modal provides: the development experience human researchers and agents need, made buttery-smooth and cost-efficient by our custom serverless runtime.
An agent can write a training script, decorate it with @app.function(gpu='H100:8'), then launch it with modal run. If there’s a bug, it can call modal.Sandbox.create(gpu='H100:8') to spin up an interactive Sandbox. Either way, GPUs spin up in seconds, and scaling from one GPU to dozens or hundreds is just a parameter change. When the work is done, they release automatically — no waking up to a surprise bill from an idle cluster left running overnight.
Agents, like humans, already find Modal’s CLI-maxxing, code-mode interface easy to use. But also like humans, they appreciate some docs and guidance. So we wrote a set of Skills that guide the agent on how to use Modal’s compute primitives, including launching interactive Sandboxes, writing and running training jobs with modal run, managing persistent storage with Volumes, and orchestrating parallel sub-agents. Instead of learning Modal’s API from scratch, the agent gets the patterns it needs to provision GPUs, run experiments, and clean up after itself.
Parameter golf
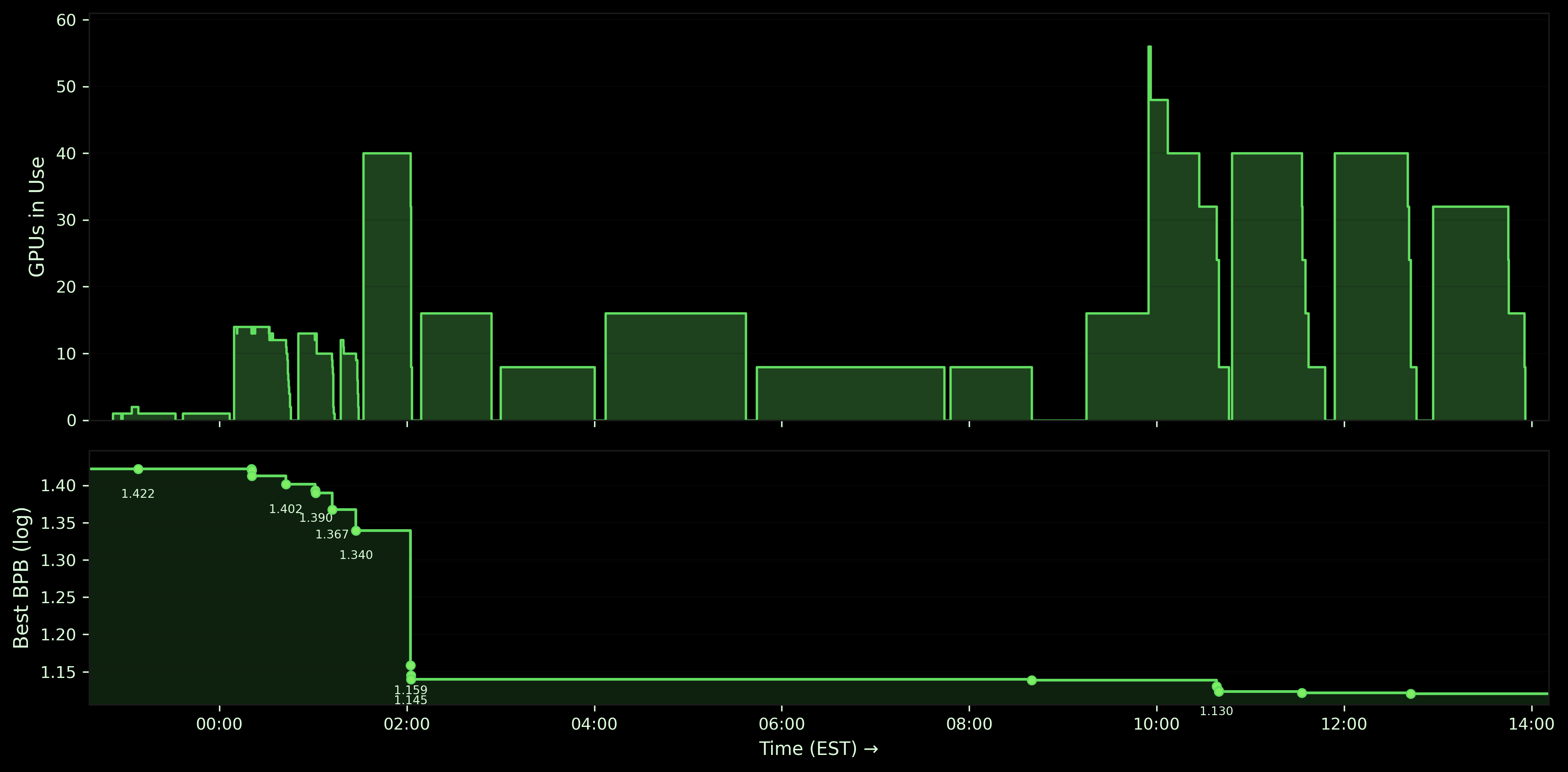
OpenAI's Parameter Golf challenge asks you to compress a language model into a ≤16 MB artifact that runs on 8×H100 in under 10 minutes, minimizing bits-per-byte. Because Modal let the agent provision and release GPUs through a simple API call, it could scale on its own — spinning up dozens of cheap single-GPU runs when exploring, running 5 parallel 8×H100 experiments when validating, dropping to serial execution when debugging, and scaling to zero when done. Below, we walk through the timeline in detail, along with the concrete speedup and efficiency benefits from its use of Modal.
Stage 1: Starting small for pipeline validation
The agent started the way any good research engineer would — with a smoke test. It spun up a single-GPU sandbox through Modal's API (modal.Sandbox.create()), trained a tiny 8M-parameter model for one epoch, quantized it, and ran evaluation. Four quick experiments over about an hour to make sure the whole pipeline worked end-to-end. Baseline BPB: 1.42.
We summarize the results by comparing both the speedup gains relative to an 8xH100 workstation (big enough to run each experiment individually) and the efficiency savings relative to a 40-GPU cluster (big enough to handle the sustained concurrent load). Speedups come from running more than the workstation’s max GPUs concurrently; efficiency gains come from running fewer than the cluster’s total GPUs.
| Speedup vs Workstation | Efficiency vs Cluster | BPB |
|---|---|---|
| 1x | 40x | 1.42 |
This validation step doesn’t gets a speedup, since it never uses more than 8 GPUs — mostly just one or two. But that means big cost savings compared to leaving the cluster ~98% idle!
Stage 2: Scaling out for broad exploration
With the pipeline working, the agent needed to explore the search space: model sizes, learning rates, sequence lengths, training durations. It spun up **~**40 independent single-GPU sandboxes in parallel — each a different hyperparameter combination, each provisioned with a single modal.Sandbox.create(gpu='H100') call. No job queue, no resource allocation config, just a function call per experiment. The entire broad sweep finished in 36 minutes of wall time.
From there it narrowed in: 23 more single-GPU experiments focused on the most promising model sizes and learning rates, then 4 ambitious runs pushing the best configurations further. BPB dropped steadily across the three sub-phases: 1.40, then 1.37, then 1.34. The exploration phase totaled about 14 GPU-hours across 68 experiments, all on single GPUs.
| Speedup vs Workstation | Efficiency vs Cluster | ∆BPB |
|---|---|---|
| 1.25x | 4x | 0.08 |
The aggregate speedup vs the workstation was modest here, but the peak speedup was actually substantial: finishing ~40 runs in ~40 minutes, rather than three hours. That’s the difference between getting results after lunch or a trip to Mission Cliffs and needing to check back in in the evening. And efficiency savings remained substantial.
Stage 3: Scaling up for validation
By the middle of the night, the agent had a clear picture of which architectures worked best. It needed validation at full scale.
So it scaled from single-GPU to 8×H100 per experiment. The infrastructure change was one parameter: gpu='H100' became gpu='H100:8'. No new cluster config, no deployment manifest — Modal handled multi-GPU provisioning the same way it handled single-GPU. The agent ran its top five configurations at full scale — 5 × 8×H100, 40 GPUs running simultaneously — and BPB dropped from 1.34 to 1.14.
| Speedup vs Workstation | Efficiency vs Cluster | ∆BPB |
|---|---|---|
| 5x | 1x | 0.2 |
Here, we see the speedup benefits for the Modal deployment over the workstation: the core experiments finished in four hours, instead of twenty. That’s the difference between a job you find out about during the same working day and one you wait through the weekend for.
The efficiency gains are now small. But that’s an unrealistic best-case scenario for the cluster! We’re assuming it was provisioned perfectly for this run. But like golf, research is not a game of perfect. And so in practice, researchers either underprovision and lose the speedup or overprovision and lose the efficiency. Modal keeps the GPU allocation perfectly tuned.
Stage 4: Scaling back down to debug
Then the agent got stuck. The model trained fine, but the quantization step — GPTQ compression to fit the 16 MB budget — was running on CPU and taking over 45 minutes. The 10-minute evaluation window meant the submission couldn't even complete. The bottleneck was in the post-training pipeline.
What followed was a long debugging stretch. The agent tried the obvious fix first: raising timeouts. 45 minutes, then 60, then 90, then two hours. During this phase, it dropped back to running one to two experiment at a time since there’s no point in parallelizing when you're diagnosing a sequential bottleneck. Five and a half hours, over 60 GPU-hours, and every run timed out.
Then it changed approach entirely. It rewrote the quantization step to run on GPU. The next experiment completed in 52 minutes total, training and quantization included.
| Speedup vs Workstation | Efficiency vs Cluster | ∆BPB |
|---|---|---|
| 1.25x | 4x | 0 |
Again, debugging has a modest speedup — though here, there were a few cases where strategies could be pursued in parallel. But the efficiency savings are substantial.
Stage 5: Scaling back up to finish
With the full pipeline working, the agent entered its optimization phase. It started with a validation round — 2 parallel 8×H100 experiments to confirm the fix hadn't regressed quality (BPB: 1.1420). Then it fanned out to 5 parallel 8×H100 experiments — 40 GPUs at a time, each testing different architectures, learning rate schedules, regularization, and data mixing strategies. Modal's elastic provisioning meant it could scale from a single debugging sandbox to 40 simultaneous GPUs and back, all through simple sandbox creation call.
BPB inched down over three optimization rounds: 1.1230, then 1.1217, then 1.1206. A final round of 4 × 8×H100 came back at 1.1220 — slightly worse. The agent recognized diminishing returns. It scaled to zero and stopped.
| Speedup vs Workstation | Efficiency vs Cluster | ∆BPB |
|---|---|---|
| 3.8x | 1.3x | 0.02 |
During this phase, we see both benefits together: we can hit the peak experimental throughput when trying strategies in parallel, giving a big speedup over the workstation, but we can adjust that throughput to match the demand from experiments over time, giving a big efficiency win vs the cluster.
The age of scaling and research
On social media and at panels, you’ll hear debates about whether we’re in the age of research or the age of scaling.
At Modal, we don’t like false trade-offs, whether that’s between development speed and engineering efficiency or between operating at peak scale and doing novel research. Coding agents, autoresearch, and other applications of artificial intelligence to research give the lie to this false dilemma. We can have our LeCake and eat it too.
Want to try it yourself? Drop our autoresearch Skills into your agent and point it at your problem. We’d love to hear what you find.