Accelerating AI research that accelerates AI research
Between my PhD at Berkeley and joining Modal, I worked on Weights & Biases. Weights & Biases became the tool of choice for experiment management in AI research. It was heavily used in the development of epoch-making models like GPT-3 and 4, to name(-drop) a few. On social media, in blog posts, and at conferences I see screenshots of W&B dashboards whose designs I remember arguing about on Slack — and I still get a kick out of it every time.
Weights & Biases helped AI research move faster by providing standardized, shared, high-quality infrastructure for experimental data and metadata.
At Modal, we’re doing the same by providing standardized, shared, high-quality infrastructure for executing experiments.
We’re especially excited about virtuous cycles from AI research that itself accelerates AI research.
That is: our platform’s speed, scale, and reliability help researchers get better answers faster. They discover ways to run AI workloads better. We incorporate these discoveries into our workflows and our platform. The wheel finishes another turn.
It’s still early days for this process. But through our partnerships with academic researchers, we’ve already gotten a chance to sponsor impressive early work in this direction from labs like Hazy Research, Scaling Intelligence, and IRIS. In this blog post, we share what they discovered — and how Modal can be used to accelerate your AI research.
Modal accelerates AI research.
Modal is a cloud infrastructure platform designed to accelerate data- and compute-intensive workloads — especially in artificial intelligence, the hottest such workload today. The Modal platform provides these workloads with the scale, reproducibility, and isolation they need.
Fundamentally, contemporary AI research requires substantial compute: big GPUs and lots of them. The trusty workstation under your desk can only take you so far — especially when your experiments are dialed in and ready to be run in parallel, e.g. in a hyperparameter sweep. HPC clusters offer a higher peak scale, but they also suffer from downtime and queueing. These bite extra hard during the crunch before conference deadlines. Modal maintains a high quality GPU fleet that you can rent chunks of by the second. No reservations required.
Code written for workstations and clusters is often brittle and non-portable. That makes it difficult for other researchers to reproduce and build on your work. Modal is like a giant, global computer that anyone can run code on — taking “it works on my machine” to “it works on our machine”. For everyone!
Finally, many AI research workloads require strong isolation between workloads. A crash or an errant write from one entry in a coding benchmark shouldn’t take down the whole system — or worse, subtly cause their performance to change. Modal is a multi-tenant system with strong isolation by default. Other cloud providers have belatedly cottoned on to this with “sandbox” offerings like ours, but they often lack the resources AI workloads need — like, say, a hot, fast B200 GPU. Or eight of them.
AI researchers who accelerate AI research use Modal.
For these reasons and more, leading AI researchers choose Modal for their infrastructure.
And some of the most exciting AI research right now is on self-improvement: AI systems that improve AI systems.
We consider two different research threads:
- using AI systems that run on GPUs to write faster code for GPUs
- using AI systems to produce AI systems
And we consider three projects that used Modal to push these threads forward:
- KernelBench, led by Anne Ouyang, Simon Guo, and Will Hu of the Scaling Intelligence Lab
- TTT-Discover, led by Mert Yuksekgonul of the Stanford AI and AI for Science Labs
- RL-4-MLE, led by Anikait Singh of the IRIS Lab
The KernelBench benchmark framed the problem of automated kernel generation and established the baseline.
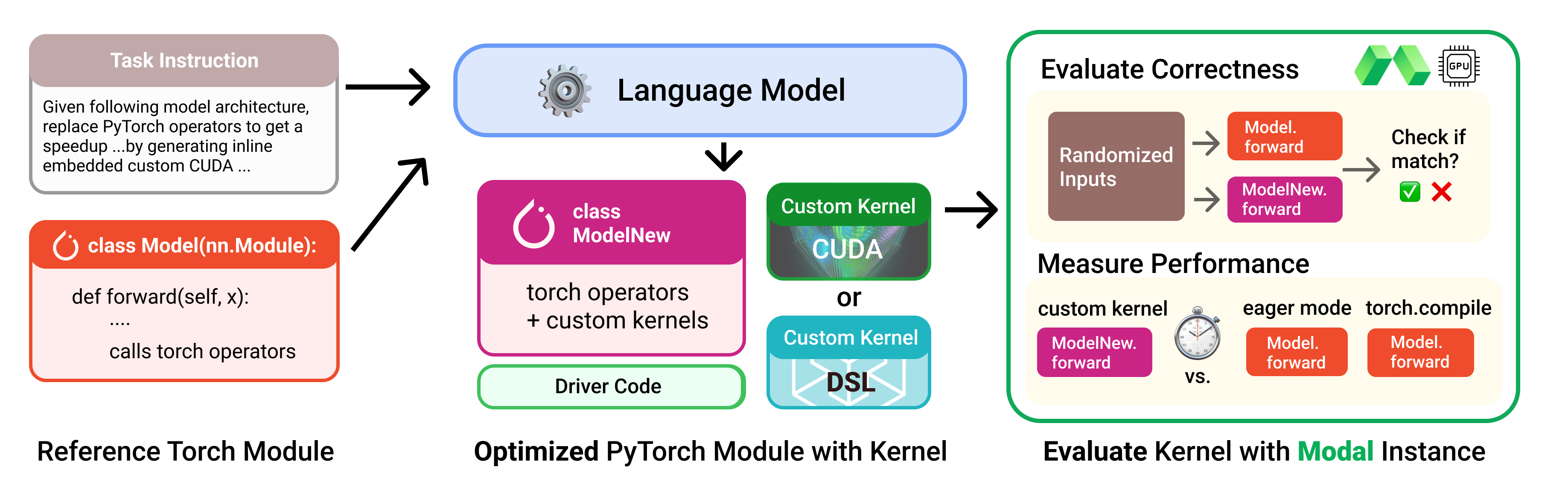
GPU kernels are the critical, performance-sensitive component of AI workloads. You may have heard of, for instance, the famous FlashAttention kernels that accelerate the key “attention” operation in Transformer neural networks. Making kernels faster makes AI workloads faster and more efficient, and it is currently bottlenecked on human software engineering labor.
Initially released in December 2024, the KernelBench project provides both a benchmark dataset of 250 problems in and a research environment for automated generation of correct and performant kernels. Benchmarks and research environments help focus work in a field and reduce duplicative and wasted effort.
Because GPU kernels are performance sensitive, performance has to be included in reward, not just correctness. Performance modeling for GPUs is limited. The solution is seemingly simple: just run the kernels. But “just run the kernels” is easier said than done!
Benchmark evaluation is also a natural fit for Modal’s reliable, reproducible auto-scaling infrastructure.
But these benefits are not unique to the KernelBench project in particular or to benchmark research in general. KernelBench’s kernel evaluation on Modal is part of the inner loop for reinforcement learning and evolutionary search algorithms. Other researchers, like Meta’s Code World Model team, use Modal’s dependable, scalable container infrastructure to support the inner loops for other kinds of computer use and agent environments.
Outside of KernelBench, the Scaling Intelligence Lab has embraced Modal as a “key building block” for multiple projects:
- Large Language Monkeys, a pioneering work on test-time compute (which we independently reproduced with a new dataset and model on Modal)
- Tokasaurus, a high-throughput inference engine hosted on Modal GPUs
- Cartridges, which used Modal to generate synthetic data for context-distillation
TTT-Discover writes better GPU kernels than human engineers.

With solid benchmarks for AI kernel authoring like KernelBench in place, the next step was to improve AI kernel generation enough to beat humans.
In January of 2026, the Test-Time-Training-Discover project succeeded, writing kernels that won first place in a highly competitive contest put on by the GPUMODE community. Their kernel established a new state-of-the-art for a triangular matrix multiplication operation used in certain molecular structure prediction models like AlphaFold.
TTT-Discover uses “test-time-training” — the same technique used by Ekin Akyürek, Jacob Andreas, and others to get second place in the 2024 ARC AGI Prize (also run and verified on Modal). In test-time-training, model weights are updated based on supervisory or reward signals from the test/inference environment.
First author Mert Yuksekgonul said that Modal was “crucial” to making their experiments “both reliable and scalable”. Reliability and scalability are of utmost importance for reinforcement learning techniques, like TTT-Discover, which are sensitive to nondeterminism and hungry for compute.
Modal’s vetted, dependable, and isolated GPUs gave their RL system a stable hill to climb:
And Modal’s scalable, serverless compute model helped it climb faster:
The GPUMODE kernel authoring contest was also sponsored by Modal and ran on our GPUs. We’re sponsoring another contest at the MLSys 2026 conference, alongside Nvidia and FlashInfer — with separate tracks for humans and AI this time.
RL-4-MLE pursues the Holy Grail: automating the entire machine learning lifecycle.
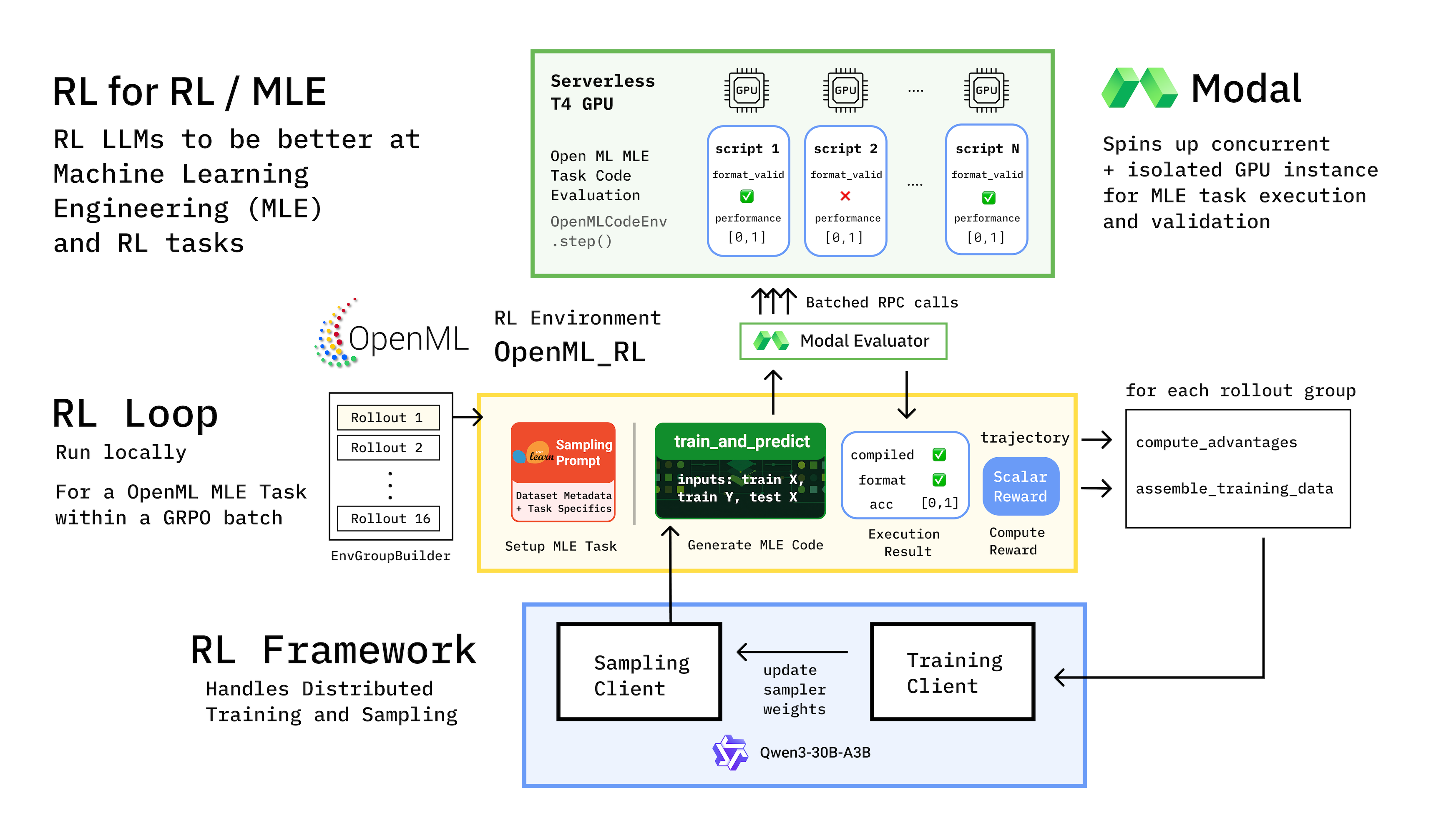
The holy grail of AI research is to fully automate AI research — provocatively framed by Andrej Karpathy as “Operation Vacation”. If AI systems can not only make themselves run faster, but also collect new data, update their weights, and otherwise improve their intelligence, then a wide variety of bottlenecks in AI R&D will be elevated, unlocking much more rapid technological advancement.
As with automated kernel generation at the release of KernelBench in 2024, this research is still in its early days today in early 2026. Modal has partnered with Anikait Singh, Simon Guo, Tanvir Bhathal, Jon Saad-Falcon, and others in Stanford’s IRIS and Scaling Intelligence Labs on some exciting preliminary research: the “RL-4-MLE” project.
This in-progress project aims to automate algorithm discovery for complex ML workflows, building on the authors’ previous work on algorithm discovery for reasoning models. Unlike many approaches to automation, but clearly in the spirit of Operation Vacation, the RL-4-MLE architecture is aimed at lifelong learning, at producing an automated research assistant that learns *how to research*, rather than optimizing for a single “correct” answer.
Long-horizon learning isn’t only challenging algorithmically. It also strains the underlying evaluation infrastructure.
Local environments simply weren’t up to the task.
Modal has been “essential” in providing infrastructure with the reliability and the scale to support this work.
Like many AI/ML researchers, I'm excited to see our tools come back to work upon themselves. I look forward to reading the RL-4-MLE paper when it is released!
Accelerate your AI, your research, or your AI research with Modal.
As artificial intelligence systems improve, we can increasingly use them to automate work, elevating bottlenecks and increasing productivity. That’s doubly exciting for technological research and development. It is then, by CEO math, four (2^2) times as exciting for AI research, which accelerates the process that accelerates R&D.
Wherever you fall in this stack, Modal’s scalable, dependable infrastructure can help you move faster and dream bigger. Try it now.