Agents need good developer experience too
For as long as developers have existed, we’ve been chasing better developer experience. Every major leap in software—from compilers and version control to continuous integration and cloud infrastructure—has come from the same goal: make it faster, easier, and more satisfying to build things.
Now, we’re at another inflection point. For the first time, we’ve built tools that don’t just improve the process of writing code, they actually write the code for us. This shift, from humans writing most code to agents writing a substantial share of it, challenges some of our most basic assumptions about what “good developer experience” means.
At Modal, we’ve always been obsessed with developer experience. So naturally, we’ve spent a lot of time thinking about what it means in this new world. This post lays out a framework for how we think about developer experience in the age of coding agents—a set of principles we’ve arrived at through years of iteration. They’re ideas that make humans happier, agents faster, and the handoff between them a little easier.
Humans and agents succeed when feedback loops are tight
If you ask ten engineers to define “good developer experience,” you’ll get ten different answers. For us, a few patterns have emerged from working with thousands of users. Above everything else, fast iteration loops matter most. The distance between writing some code and seeing the results should be as short as possible.
Why? Because programming is an ongoing cycle of hypotheses and corrections. You make a change, run the code, see what happens, and adjust. The tighter that loop, the faster you learn. Every extra second—waiting on builds, watching deploys, digging through logs—compounds into friction that slows down discovery.
When coding agents entered the picture, we first worried that designing for humans and designing for agents might differ. Unlike humans, agents don’t get “frustrated” when things are slow. But over time, we’ve had a surprising revelation: much of the work that we’ve done to make Modal’s developer experience great for humans is paying off for agents too.
That’s because agents rely on feedback loops just as much as humans do. They generate code, run it, observe what happens, and adapt. It’s the same iterative process, just faster and more literal. When that loop is tight, agents can make rapid progress. When it breaks—because an error is vague, a config isn’t accessible, or human intervention is required—they stall. The best design accelerates their ability to try again, quickly and correctly.
Designing for agents, then, isn’t about reinventing developer experience. It’s about applying the same principles that make humans productive and making sure they hold up when the developer is no longer human. Let’s talk about what those principles are.
Programmatic access shortens feedback loops
For humans, a CLI is one of the most effective ways to keep iteration loops tight. Instead of clicking through a UI or waiting for a multi-step deployment pipeline, you type a single command and see the results right away.
Agents benefit even more. Anyone who has used coding agents knows you need to give them tools, and a CLI is the simplest, most universal tool you can hand an agent. It provides a structured, repeatable way to run code, capture outputs, and try again.
But the real key to fast feedback loops is having all relevant functionality available programmatically. A CLI is a good start, but an SDK or API opens up for more flexibility and an even larger degree of automation. If billing information, logs, or details about your runtime environment—like how many containers are active or what hardware your code is running on—are only available through a UI, that limits both humans and agents. Agents, especially, work best when they can use text-based, structured interfaces rather than graphical ones.
Actionable error messages make debugging faster
Most programming time is spent debugging, which is why error messages matter so much. A terse or cryptic failure leaves you stuck, reaching for documentation or Stack Overflow. A detailed and actionable error message, with hints or examples, instead nudges you back onto the happy path. For humans, this shortens the feedback loop dramatically.
For agents, error messages are even more critical. Much like humans, agents rely on limited context windows. You can load them up with an entire codebase or thousands of tokens of documentation—and sometimes that’s necessary—but it’s rarely efficient. What’s far better is supplying only the most relevant information at the exact moment they need it. A precise, explanatory error message that tells you how to fix the problem, is exactly that: a high-signal piece of context that an agent can use immediately to correct its behavior.
The example below shows a warning that catches a subtle bug, which is easy to miss, and explains how to fix it. Our experience is that this level of detail in errors and warnings improves the developer experience for both humans and agents substantially.
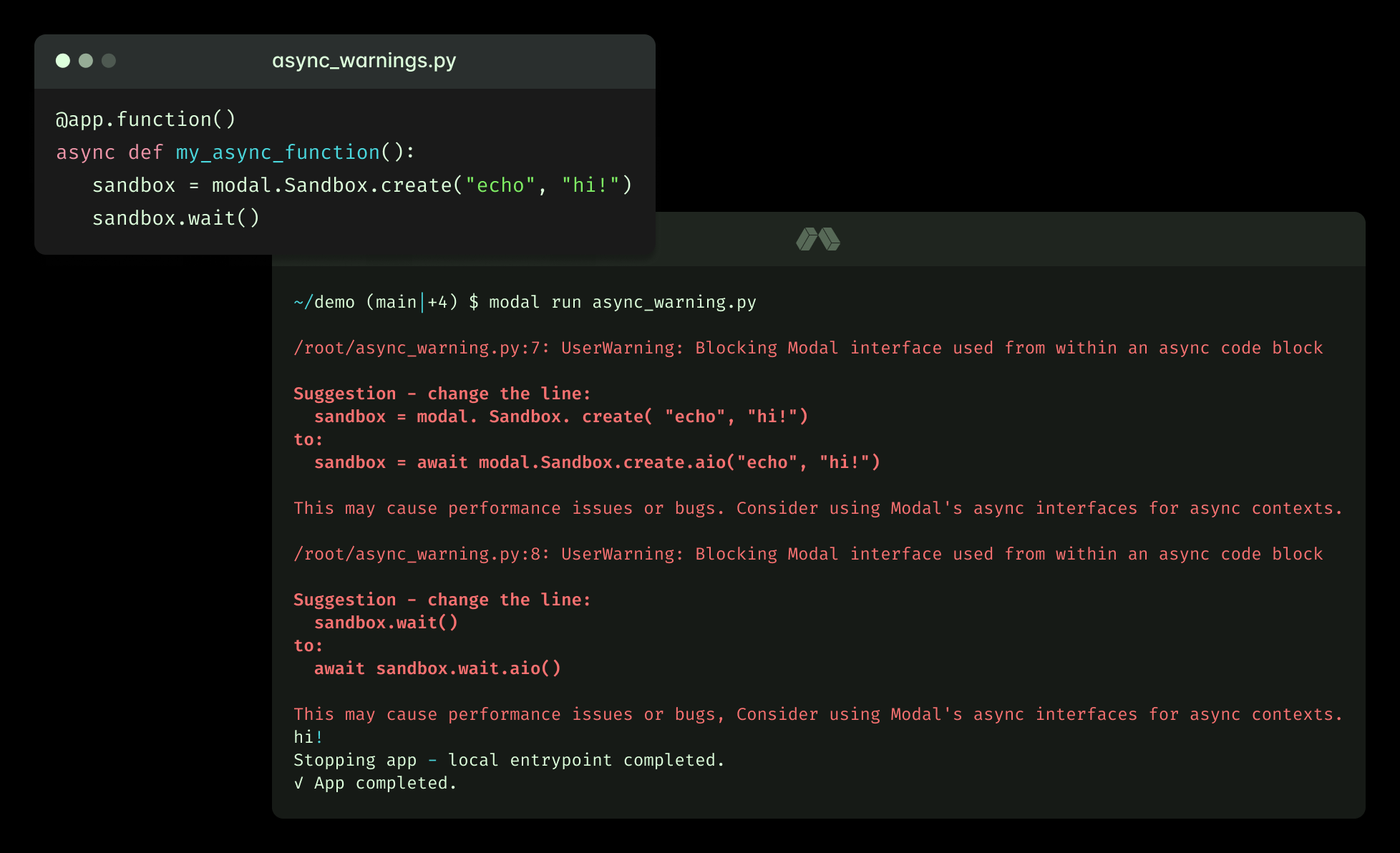
Examples are the foundation of learning
Humans are pattern-matching creatures. They don’t learn by reading long expositions on “core concepts,” but by adapting concrete examples. Agents work the same way. They are fantastic at following and remixing patterns they’ve seen before. So the more examples you provide, the more likely it is that an agent, or human, will find one close enough to their problem to adapt into a solution.
Just having lots of examples isn’t enough though. Both humans and agents need to be able to extrapolate from them, so patterns need to be consistent across your library. If there are three ways to achieve the same thing, and all three are used in your examples, both humans and agents will struggle.
We’ve also noticed that both humans and agents benefit from explanations that reside in close proximity to code. Below is a snippet from our vLLM inference example:
# ## Set up the container image
# Our first order of business is to define the environment our server will run in:
# the [container `Image`](https://modal.com/docs/guide/custom-container).
# vLLM can be installed with `pip`, since Modal [provides the CUDA drivers](https://modal.com/docs/guide/cuda).
# To take advantage of optimized kernels for CUDA 12.8, we install PyTorch, flashinfer, and their dependencies
# via an `extra` Python package index.
import json
from typing import Any
import aiohttp
import modal
vllm_image = (
modal.Image.from_registry("nvidia/cuda:12.8.0-devel-ubuntu22.04", add_python="3.12")
.uv_pip_install(
"vllm==0.10.1.1",
"huggingface_hub[hf_transfer]==0.34.4",
"flashinfer-python==0.2.8",
"torch==2.7.1",
)
.env({"HF_HUB_ENABLE_HF_TRANSFER": "1"}) # faster model transfers
)Keeping infra and logic together prevents drift
One of the easiest ways for both humans and agents to go off the rails is when infrastructure and application logic live in different layers. YAML is the classic example: update a deployment in one place, and you also need to reconcile changes across other files. Humans make mistakes here, but agents struggle even more, often hallucinating new fields or misaligning configs.
A better approach is to keep infrastructure and logic together, in one place and one language. Configuring infrastructure with Python rather than YAML has a lot of benefits: it supports static analysis, offers clear documentation and autocomplete, and is more token-efficient for agents. It improves locality of behavior, by keeping related code and configuration close together, so their interactions are easy to see and reason about. It also makes discoverability simple—you can inspect a function or check supported arguments directly, instead of hunting through schema docs. And by keeping the SDK surface area small and consistent, it’s easier for both humans and agents to reason about what’s possible.
As an example, here’s how you can define a function, its environment, and its hardware requirements in a single code block using Modal:
image = modal.Image.debian_slim().pip_install("torch", "numpy")
@app.function(image=image, gpu="h100")
def matmul(a, b):
import torch
a = torch.tensor(a).to(device="cuda")
b = torch.tensor(b).to(device="cuda")
c = a @ b
return c.cpu().numpy()When everything lives side by side—code, resources, environment—you get a single, legible source of truth. Especially for AI workloads, where compute, code and data are tightly coupled, this makes iteration much faster and less error-prone.
Names shape how we think about systems
Even with the rise of agents, humans are still reading, reviewing, and reasoning about code. That makes naming central to developer experience: names shape how you understand a system. Functions, classes, and parameters should reflect what they actually do, and map to concepts humans already understand.
When names diverge from intuition, the mental model breaks. We once used the term concurrency_limit to describe how many parallel containers could run a function. It was technically correct, but confusing because Modal also supports concurrency within containers. Renaming it to max_containers made the behavior obvious, because it aligned the name with the specific concept it was controlling.
@app.function(min_containers=1, max_containers=500)
def my_function(input):
...
return resultThis matters for agents, too. Ambiguous names increase the risk of errors and broken feedback loops. You can paper over some problems with long, overly descriptive names, but those become cumbersome for humans—and token-expensive for agents. The real value though, isn’t in any individual naming choice, but in the consistency of those decisions across your system. Concise, consistent, and intuitive naming helps both humans and agents understand how the system really works.
Designing for humans also means designing for agents
We didn’t set out to design for agents. Our goal was to reduce toil for humans and keep them in fast, satisfying iteration loops. But the same principles— fast feedback, helpful errors, runnable examples, unified logic and infra, and readable code—also maximize the chances of agents succeeding.
The future of development may look different, with humans and agents sharing more of the work. But the foundation remains the same: both need good developer experience to thrive.