Boosting multimodal inference performance by >10% with a single Python dictionary
tl;dr: Multimodal models are promising, but inference engines haven't been optimized for them yet. We profiled SGLang’s scheduler on a multimodal workload and identified an opportunity to replace expensive book-keeping around shared GPU memory with a simple cache lookup. Throughput and latency both improved over 10% on our target workload. The improvement is merged in SGLang v0.5.10.
| Metric | Handle Cache OFF | Handle Cache ON | Improvement |
|---|---|---|---|
| Throughput (req/s) | 22.2 | 25.7 | +16.2% |
| TTFT mean (ms) | 965 | 838 | -13.2% |
| TPOT mean (ms) | 72 | 60 | -17.2% |
Multimodal vision-language models (VLMs) give artificial intelligence eyes. Our users deploy smaller VLMs for efficient parsing of unstructured documents and large ones to power multimodal coding agents who can see the apps they are designing.
These new input types and new models pose new challenges for open source inference engines, like SGLang and vLLM. And one of the most stubborn challenges is maximizing performance -- solved here, as always, only by a relentless grind, one small improvement at a time.
This blog post tells the story of one of those humble changes.
While working with a customer, we were benchmarking Qwen2.5-VL-3B-Instruct on H100s, and we noticed that SGLang’s throughput had plateaued well below what the GPU could handle. The solution was to remember the "golden rule" of inference performance engineering: never block the GPU.
Identifying host overhead
When you notice an inference performance issue, stop yourself from going CUDA MODE and scrutinizing warp stall reasons in Nsight Compute -- you can even put down the Torch Profiler! Check the easy things first: what is happening on the host and why isn't it faster?
In (V)LM inference engines like SGLang, the scheduler is the key host-side component and potential bottleneck -- a single-threaded loop that gates submission of work the GPU.
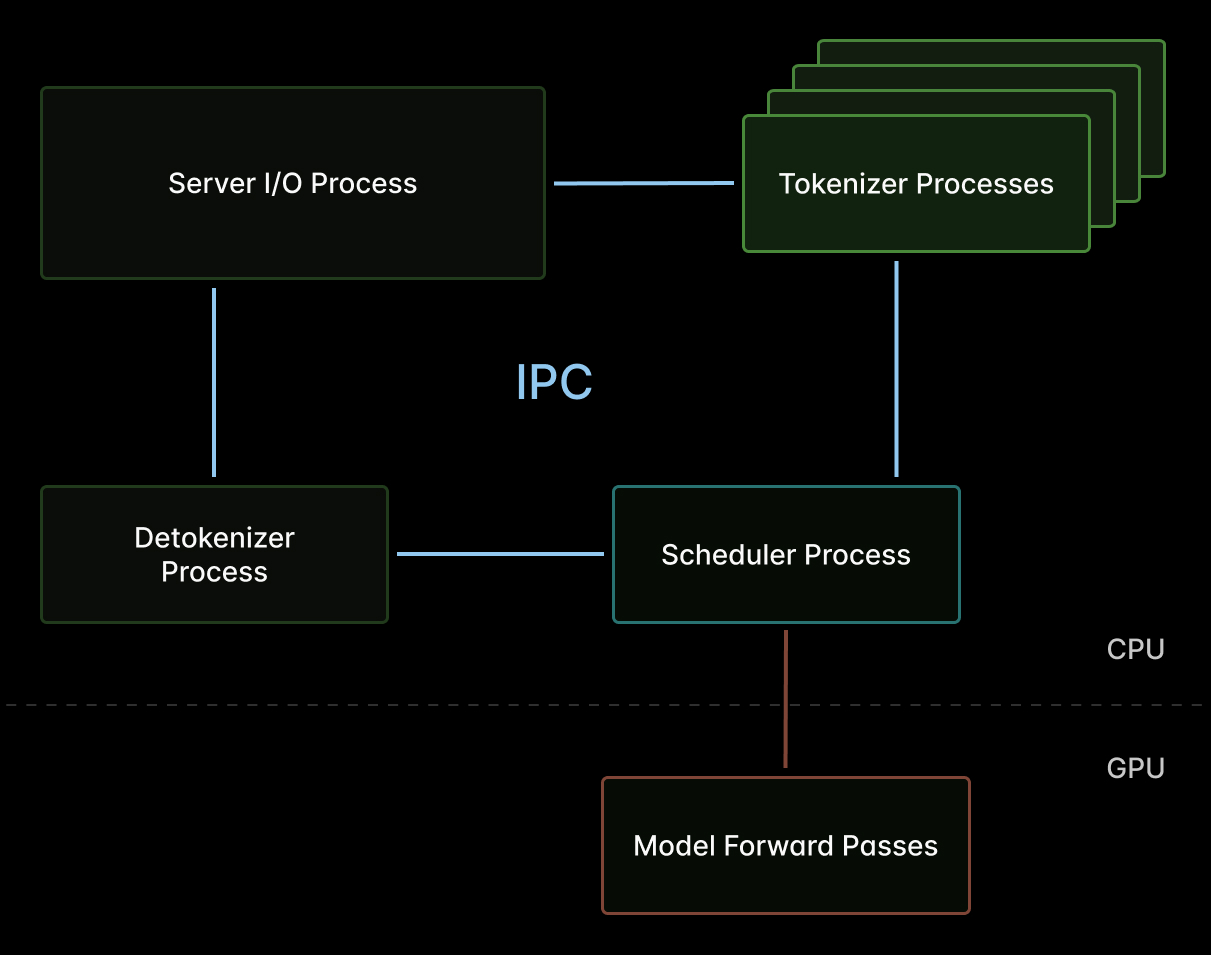
Every millisecond spent in the scheduler is a millisecond that prefill and decode iterations are stalled for all in-flight requests. We’ve said it before: host overhead will kill your inference efficiency.
Introspecting overhead with py-spy
So we attached the humble Python profiling tool py-spy to a running SGLang scheduler process serving multimodal traffic:
py-spy record --pid ${scheduler_pid} --duration 30We love py-spy -- it can sample call stacks from running Python programs with minimal overhead. After 30 seconds of sustained multimodal traffic, we had ~3k samples and a usable flamegraph.
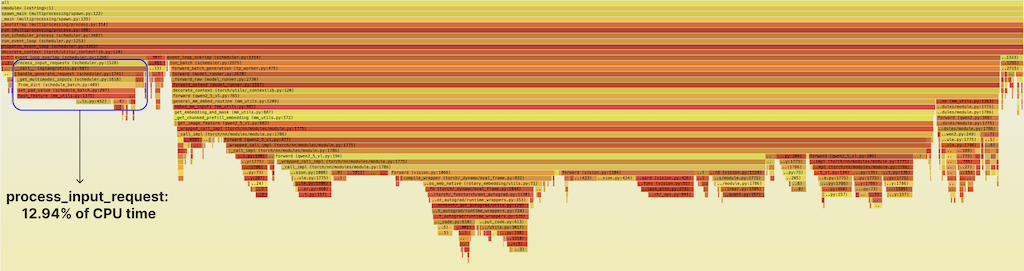
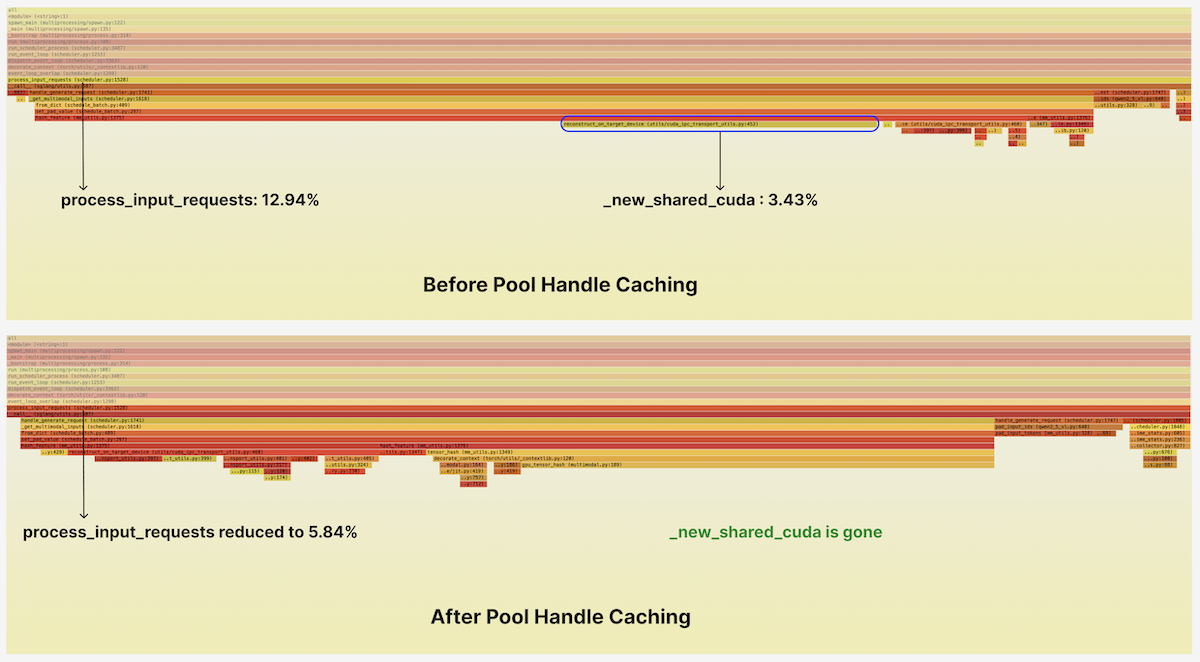
The highlighted band on the left is a function called process_input_requests. It prepares incoming multimodal requests so that the scheduler can form a batch and dispatch it to the GPU. It consumed ~13% of total scheduler CPU time and stood out as a suspicious "mesa" in the flamegraph.
Drilling into process_input_requests, we see that the majority of the time is spent in a function called hash_feature, which maps input images to hash-based IDs so they can be identified cheaply during KV cache lookups. This is a new code path for multimodal inputs (text tokens come with a natural ID, their vocab index) and so we figured it was likely it hadn’t had much optimization attention.
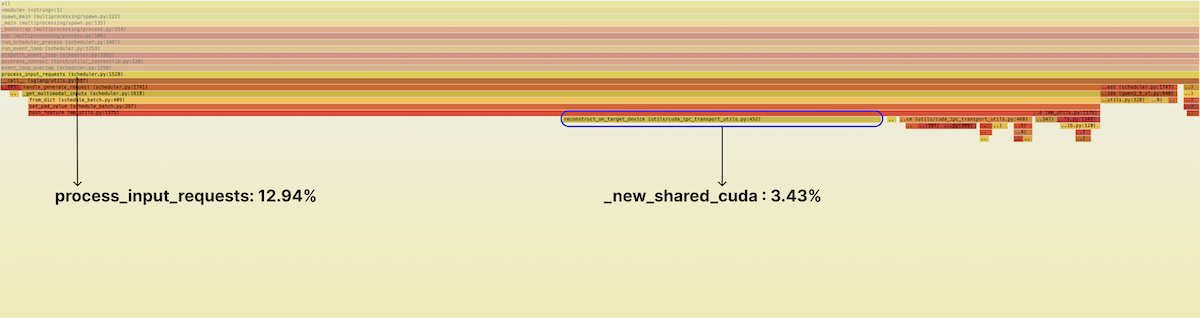
Inside, we see something suspicious. About 25% of the time in this function, or a bit over 3% of total runtime for the scheduler, is being spent in calls to reconstruct_on_target_device — and from there, on a call to torch.UntypedStorage._new_shared_cuda.
So now we need to ask: what is that doing? And can it be faster?
Avoiding book-keeping in the hot path with a Python dict
Why shared storage? Device memory allocations in CUDA are by default associated with a single process, just like memory allocations in CPU programming.
SGLang splits work across processes. For instance, the scheduler orchestrates GPU inference in one process, while one or more tokenizer workers preprocess raw inputs into tensors in parallel in other processes.
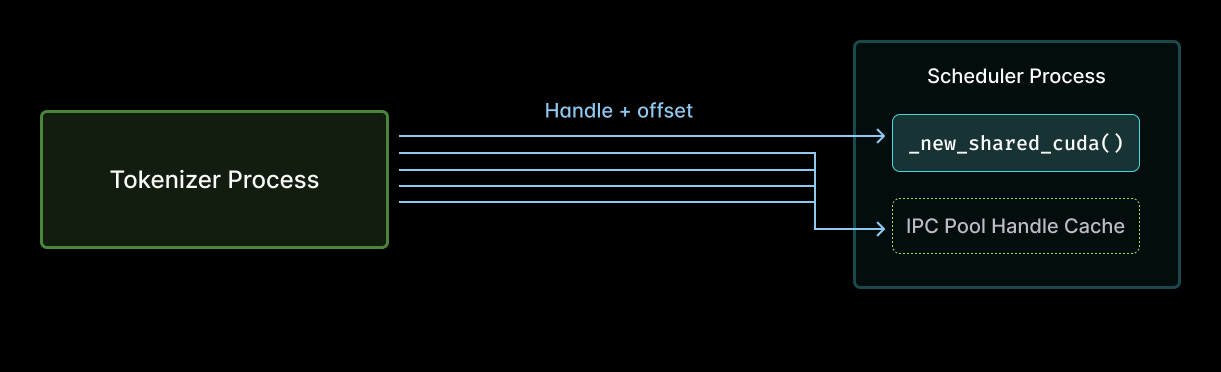
So these tensors must cross the process boundary. The fastest way to do that for large on-device tensors in SGLang uses CUDA Interprocess Communication (IPC), which avoids copies. In particular in SGLang, each worker has its own GPU memory pool, every tensor is a slice of that pool, and those tensors are identified by their pool’s handle and an offset in the pool. That metadata needs to be communicated between the tokenizer processes and the scheduler.
Reviewing the code in the context of the flamegraph, we realized that the scheduler was calling _new_shared_cuda on every tensor. Like this:
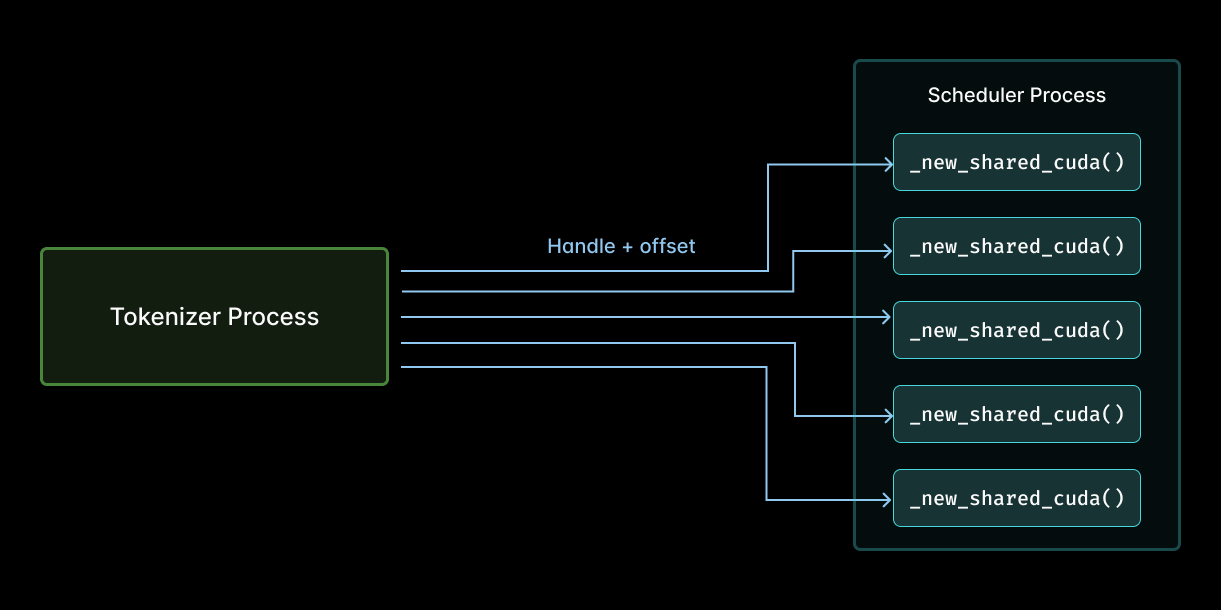
That is, the previous implementation of tensor sharing between a tokenizer process (left) and the scheduler (right) during multimodal feature hashing required a call to _new_shared_cuda for each tensor shared (arrows).
That means the scheduler was reopening the same few handles over and over, incurring host-side overhead on book-keeping each time, only to discard the book at the end of the scheduler iteration! This work scales with the number of entries in the pool and the number of iterations. But really, you only need a constant amount of work, one call per pool. Do it once, but don’t do it again!
What work are we talking about here? At the CUDA API level, repeated opens are cheap (reference-counted). So most of the overhead comes from the PyTorch wrapper - fresh StorageImpl, CUDA event recording, GIL interaction, and allocator book-keeping. See this GitHub Issue for more details.
This is a misuse of precious milliseconds, and every millisecond counts!
The fancy-sounding “CUDA IPC Pool Handle Cache” is implemented as a simple Python dict. The pools are never reallocated, so cache invalidation is unnecessary. We also only need a lock when writing to the cache, not when reading it. And writes are very rare! The implementation is just:
_pool_storage_cache: dict = {}
_pool_cache_lock = threading.Lock()
def _pool_handle_cache_get(pool_device_index, pool_handle):
"""Open a pool IPC handle once, return cached storage."""
cache_key = (pool_device_index, tuple(pool_handle))
storage = _pool_storage_cache.get(cache_key)
if storage is None:
with _pool_cache_lock:
storage = _pool_storage_cache.get(cache_key)
if storage is None:
storage = torch.UntypedStorage._new_shared_cuda(
*pool_handle
)
_pool_storage_cache[cache_key] = storage
return storageSpot-checking the fix with another flamegraph
We reran py-spy profiling under the same load with the new cache enabled. The _new_shared_cuda hotspot disappeared from the profile, and the total number of samples in input processing was cut by more than half.
Measuring end-to-end outcomes: 16% more throughput and 10% lower latency
Flamegraphs are nice for debugging performance issues, but they don’t guarantee an end-to-end win. So we went back to our benchmark, Qwen2.5-VL-3B-Instruct on a single H100. Below are the results before and after the addition of the pool handle cache.
Request throughput improved by ~16% and mean end-to-end latency dropped ~10%. Tail latencies improved too!
| Metric | Handle Cache OFF | Handle Cache ON | Improvement |
|---|---|---|---|
| Throughput (req/s) | 22.2 | 25.7 | +16.2% |
| TTFT mean (ms) | 965 | 838 | -13.2% |
| TTFT p99 (ms) | 2058 | 1819 | -11.6% |
| TPOT mean (ms) | 72 | 60 | -17.2% |
| ITL p99 (ms) | 627 | 556 | -11.4% |
| E2E latency mean (ms) | 1979 | 1768 | -10.6% |
| E2E latency p99 (ms) | 4309 | 3666 | -14.9% |
Details in the PR.
Our benchmarks used Qwen2.5-VL-3B, but the improvement applies to any multimodal model using SGLang’s CUDA IPC transport. Benefits should scale with the total number of multimodal inputs.
Decode latency improved too!
One result that is surprising at first blush: average time-per-output-token dropped 17%. Decoding got faster, even though the fix is entirely in the input/prefill path. How could that be?
First, with mixed-chunk scheduling enabled, prefill and decode tokens can share a batch, so slowing down the setup of prefill batch elements can also slow down the decodes.
But the real win is deeper. Remember, SGLang's scheduler runs on a single thread -- one thread to process incoming requests, form batches, and dispatch batches to the GPU. So slowness anywhere means slowness everywhere! With everything running on one thread, time spent in process_input_requests is time not spent dispatching the next batch.
This perf improvement is already in released SGLang. Try it out now!
The optimization was upstreamed via sgl-project/sglang#21418 and is a part of release v0.5.10. You can enable it, when using CUDA IPC, by adding the following flag:
export SGLANG_USE_IPC_POOL_HANDLE_CACHE=1If you want to try it yourself, our guide to deploying VLMs with SGLang on Modal will get you running in minutes.
P.S. If this is the kind of problem you like solving, we’re hiring.