Host overhead is killing your inference efficiency
In asynchronous systems like React and the Linux kernel, there is a prime directive: never block the event loop.
AI inference workloads have a similar directive: never block the GPU.
When you block the GPU, you get a particular inefficiency called host overhead.
In this blog post, we’ll show you how to tell if your inference is suffering from host overhead, why that’s so bad, and what to do about it — including how we’ve reduced host overhead in production-grade open source inference engines.
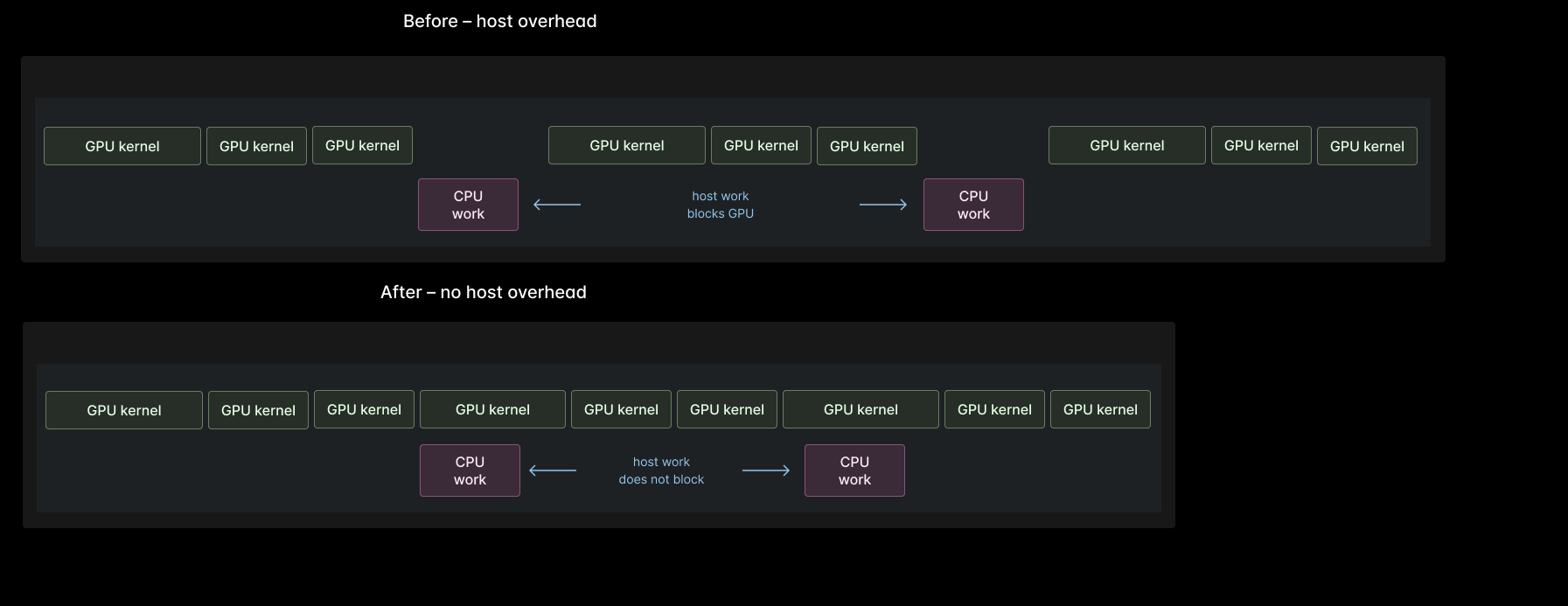
Host overhead shows up as low GPU kernel utilization.
We live in an era in which AI inference is manifestly too slow. User expectations and computer systems have evolved together such that any computer system taking over a few hundred milliseconds to respond is “slow”. AI inference struggles to meet these interactivity requirements.
Fundamentally, the bottleneck must be solved in silicon: more bytes per second from memory and more operations per second from cores.
But in the interim we, as software engineers, must make the best use of the hardware we have.
We’ve previously written about how to determine whether you’re using your GPU hardware effectively, from fleet management to Tensor Core pipe utilization. Host overhead appears in the middle: progress is halted at the level of the entire GPU while it waits for the CPU to prepare work for it.
This metric is reported by nvidia-smi and other tools as “GPU Utilization”. We prefer the more descriptive “GPU Kernel Utilization” — what fraction of your GPU’s capacity to run CUDA kernels are you using? It is 100% if at least one CUDA kernel was running on the GPU at every point in time during measurement.
If there is always work for the system as a whole to do (as is typically the case for a production system), then any point at which the GPU is not doing work is an instance of host overhead.
To identify opportunities to resolve host overhead, we recommend staring really hard at the code until you achieve enlightenment tracing your inference engine with the PyTorch Profiler or Nsight Systems. If you review these traces visually, you’ll find “gaps” in the CUDA streams — those are your opportunities to fix host overhead.
Host overhead is bad.
Properly fed, a modern data center GPU can complete about one million floating point operations in a nanosecond. That means every nanosecond that the GPU sits idle because the CPU is deciding what the GPU needs to do next is a waste of a million operations — of more arithmetic than you will do by hand in your lifetime.
And this has a direct impact on AI inference efficiency: if your host overhead is at 50%, the GPU costs for your inference are 2x what they could be. And GPU costs are typically the primary driver of inference costs.
Think of it like a navigator and their ship. The navigator needs to plan ahead on the journey far enough that the ship never stalls waiting for directions. Any time the ship stops while waiting for the navigator to decide what heading and velocity to take next, the voyage is experiencing “navigator overhead” — and unhappy passengers.
In AI inference workloads, the CPU host is like the navigator: it decides what work needs to be done. The GPU device is like the ship: it does the actual work. And good captains, like all good leaders, don’t want the actual work to be stalled on decision-making unless absolutely necessary.
Unnecessary synchronization with the CPU introduces host overhead.
Consider the following fragment of instructions for a voyage:
“Once you reach the coral reef, head for the island on the horizon“.
When the ship reaches the coral reef, the navigator needs to
- identify the island
- determine the heading towards the island
- issue the new heading to the ship
During that time, the ship will sit idle.
Compare that to:
“Once you reach the coral reef, adjust heading to 5 degrees west“
Now, the ship only waits while the navigator issues the new heading to the ship.
As you can imagine, setting this up is harder. You need to think ahead! Someone might need to go to the island and measure the heading ahead of time. But it’s worth it for a setting where that preparatory work can be amortized over many, many executions — like production AI inference.
You can avoid synchronization by constructing tensors instead of transferring them.
Unnecessary transfer of data between the CPU and the GPU is a common cause of host overhead that we’ve identified and fixed in production inference engines.
In one case, a tensor of position embeddings was being constructed on the CPU and then transferred to the GPU. But for an important special case that was particularly susceptible to host overhead (decoding), the tensor would always have a simple structure, so it could be constructed on the GPU instead.
Read more in our PR here. Note that the win here is not that the GPU is faster to compute the tensor values. Instead, it’s that we avoid a synchronous data transfer.
In another case, a tensor of KV cache page lengths was being moved from GPU to CPU to support appropriate kernel selection. But again, in an important special case that was particularly susceptible to host overhead (unit size pages), that tensor would always be all 1s, so it could be constructed directly on the CPU — computation, not communication.
Read more in our PR here. Here, it’s even more obvious that the win doesn’t come from GPU horsepower, since we actually moved the construction off the GPU here.
Every CUDA kernel launch is a potential source of host overhead.
Consider the following instructions for a ship:
- “Set heading to S for five minutes.”
- “Set heading to E for ten minutes.”
- “Set heading to N.”
After each instruction finishes, the ship briefly sits idle while waiting for the navigator to say what to do next. This isn’t so bad if there’s several minutes between changes in headings and it takes only a few seconds to steer. But if the ship needs to follow a tricky sequence of short headings where each heading is only a few seconds long — say, to carefully chart a course between Scylla and Charybdis — this overhead starts to matter.
It’d be better if we could do a single “instruction” that just combines multiple headings together:
“Set heading to S for five minutes, then set heading to E for ten minutes, then set heading to N.”
This same problem arises in AI inference workloads.
It takes on the order of microseconds to launch a kernel on the GPU. That may not sound like much — though remember, that’s enough time for a billion or so arithmetic operations on the GPU! Plus those microseconds add up, especially for small models on small inputs.
For instance, a B200 GPU with HBM3e memory can stream an 8 gigabyte model from RAM to registers in one millisecond (this is the “memory lower bound” on inter-token latency). An eight gigabyte model like Qwen 3 8B FP8 with dozens of layers composed of dozens of ops naively has hundreds of kernels. At a microsecond apiece, hundreds of kernel launches will meaningfully eat into your millisecond budget.
It’d be better if we could combine multiple launches into a single launch, paying the overhead only once.
Fuse multiple kernels to reduce host overhead from kernel launches.
One key trick to cut down on kernel launch overhead is kernel fusion — merging multiple kernels into one. This can be done manually or automatically. In PyTorch, the most popular neural network acceleration framework, the most popular kernel fusion tool is the Torch compiler.
In one case, we were able to use the Torch compiler to cut the number of kernel launches down from ~20 to 3, removing around 30 microseconds of host overhead and shaving 20% off of mean end-to-end latency. Read more in our PR here.
Use CUDA graphs to amortize launch overhead further.
In principle, every kernel in an inference pass can be fused together. In practice, this is too hard for compilers and too labor-intensive for humans. So even after manual and automatic kernel fusion, you’re generally left with a good number of kernel launches per inference pass.
Multiple kernel launches that form a directed acyclic graph can be merged into one launchable unit with CUDA Graphs. These are already used in production inference servers like SGLang and vLLM. As these engines and the models they serve mature, we expect it to become typical to launch entire forward passes as a single CUDA Graph. And we’re excited to work on it!
We’re building the infrastructure for open intelligence.
At Modal, we believe every microsecond counts — especially for emerging performance-sensitive workloads like artificial intelligence. That means host overhead is unacceptable. We’re proud to contribute to open source inference engines and drive forward the state of the art for performant inference of open models.
If you’re building production AI inference and you feel the same way, let us know. Our highly optimized AI infrastructure is ready to support you.
If you’re interested in working on open source inference engines, we’re hiring. Come ready to spend hours shaving a microsecond off a code path that will execute a trillion times.