How Reducto improved enterprise-scale document processing latency by 3x
Reducto is on a mission to turn messy, real world documents into structured data. Their platform ingests and processes millions of PDFs, spreadsheets, and slide decks per day. Reducto helps companies ranging from AI-native startups to the world’s largest enterprises and hedge funds, particularly in sensitive verticals like finance, legal, insurance, and healthcare.
Their customers bring demanding workloads: millions of pages at once, highly variable traffic, and strict latency requirements for real-time user interactions. To maintain a seamless experience, Reducto needed elastic infrastructure for their multi-model pipelines. That’s where Modal came in.
The challenge: spiky, high-stakes workloads
Early on, Reducto ran their product on manually provisioned EC2 instances. As usage grew, they adopted Kubernetes to manage their compute. It worked for a while, but problems soon emerged as Reducto kept growing:
- Scaling a monolith: With dozens of models in production, Reducto had to scale all of them together, even though usage patterns varied. Over-provisioning GPUs was costly, and scaling Kubernetes workers for every spike was operationally complex.
- Latency variance: Large, bursty uploads up to millions of pages introduced substantial load spikes, making it challenging to maintain predictable P90 latency for all customers.
- Infrastructure strain under spikes: Maintaining resilience under these extreme bursts was nearly impossible. The team needed a way to isolate workloads and scale them independently without impacting other customers.
The Reducto team started evaluating alternative solutions. Some products didn’t autoscale quickly enough. Others, namely API-first providers, didn’t give them the full code control they needed for their inference logic. The team ultimately landed on Modal to give them the customizability, GPU availability, and delightful devex they needed.
Deploying complex multi-model pipelines on Modal
Reducto achieved massive latency reductions, including a 3x reduction in P90 latency, after migrating inference workloads for their 30+ models to Modal. This was made possible by several key features:
- GPU memory snapshotting: To drastically cut cold boot times, the team utilizes GPU snapshotting for several models. This reduced cold boots by 83%, from ~70s to ~12s.
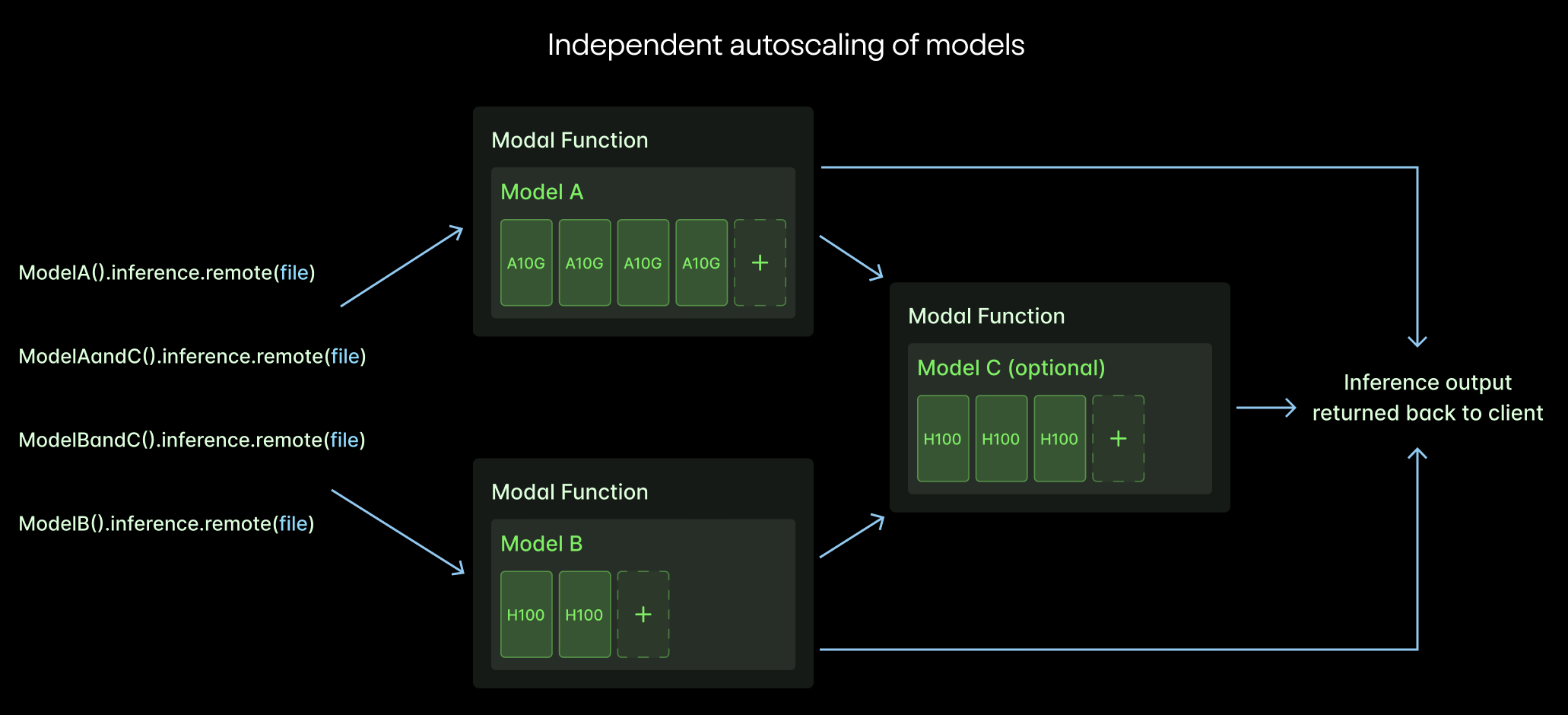
- Independent scaling of models: Reducto bundles some models together into single Modal Functions and keeps others in separate Functions. This means they have full control over which models autoscale together, maximizing compute utilization and minimizing resource contention.
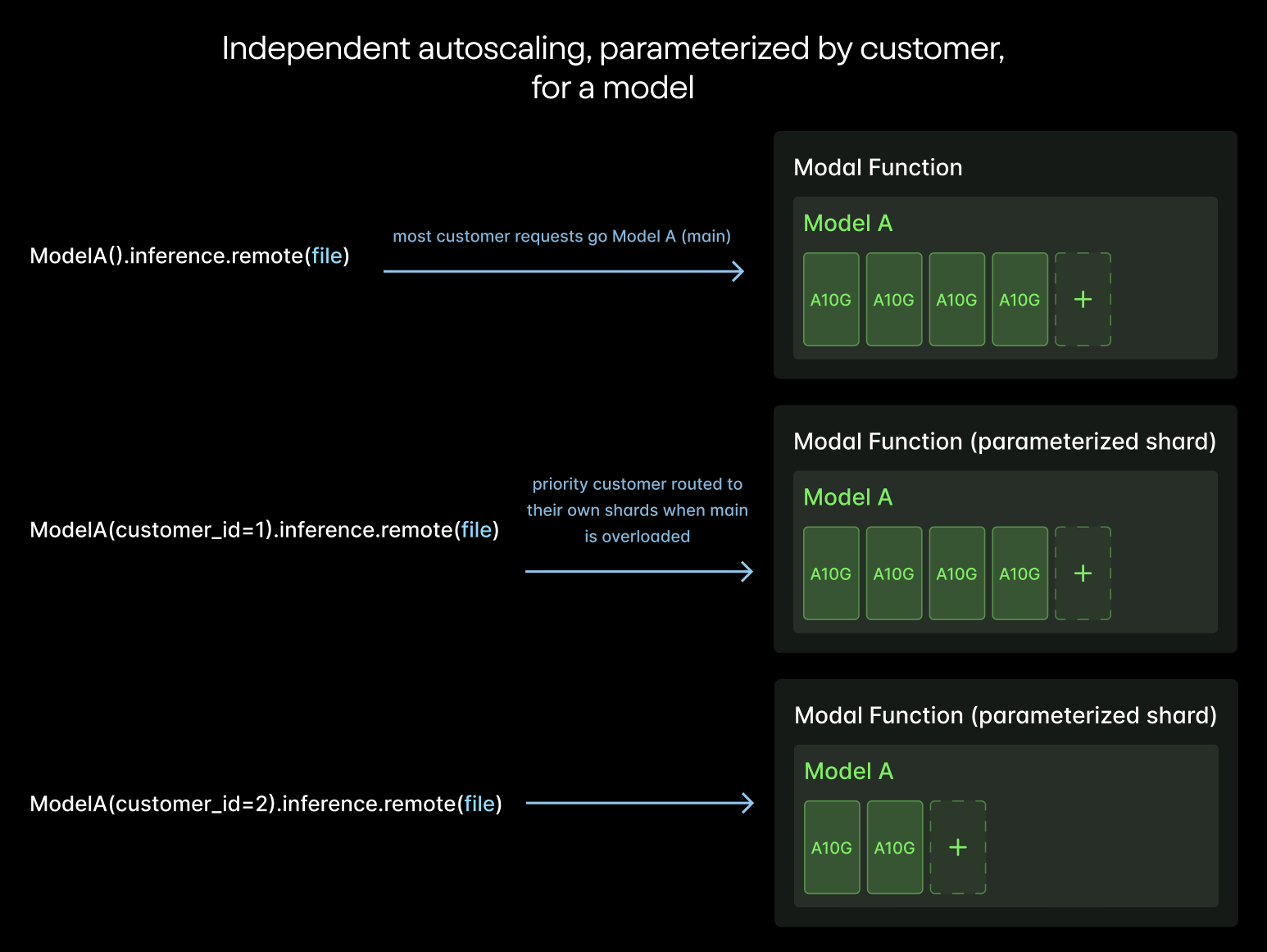
- Customizable scaling per customer: Reducto uses parameterized Functions to easily create and restrict independent autoscaling compute pools per customer. This ensures that spikes from one customer don’t impact SLAs for others.
- Granular regional control: To reduce overhead network latency, Reducto pins certain latency-sensitive Functions to US West, where their servers are. Other workloads leverage Modal’s full global compute pool to service peak volume.
Load-testing Modal at extreme scale
When a large enterprise prospect asked Reducto to demonstrate throughput of 100k pages per minute, the team saw it as an opportunity to load test their architecture. On Modal, Reducto seamlessly scaled its ingestion pipeline to over 1,000 GPUs in under an hour, then cleanly back down. The test underscored Reducto’s ability to support the most demanding enterprise workloads and gave the prospect confidence to move forward and sign the deal.
Bonus: making Reducto engineers happy
For Reducto’s engineers, managing infrastructure used to mean fighting Kubernetes, spending time on complex networking setups, and writing significant amounts of boilerplate code. Modal changed that completely.
By using Modal’s ergonomic SDK and powerful networking primitives, the team is spending a lot more time shipping the next great OCR model and a lot less time on devops.
Looking ahead
As Reducto builds AI-powered document intelligence pipelines that classify, extract, and reason over dense enterprise document corpuses, Modal provides the foundation to scale reliably and cost-effectively. Reducto continues to expand its use of Modal with the deployment of new large language and vision-language models.
The team is also leveraging Modal Notebooks for early fine-tuning workflows and rapid experimentation, helping them iterate quickly on new product capabilities. With Modal as its infrastructure backbone, Reducto can deliver highly performant, production-grade document intelligence solutions for its largest customers.