How Decagon shipped real-time voice AI on Modal
This post was written in conjunction with the Decagon team.
Decagon provides a unified platform to build, optimize, and scale AI agents that deliver concierge-level customer experiences across every channel. Earlier this year, they launched Decagon Voice, enabling teams to build fast, intelligent voice AI agents tailored to each brand’s tone, personality, and performance needs.
Voice is among the most technically demanding frontiers in AI. It requires sub-second latency, natural turn-taking, and seamless responsiveness, all while maintaining conversational quality. Meeting these constraints in production and at massive scale demanded breakthroughs in both model accuracy and inference performance.
To make it possible, the Decagon and Modal teams partnered closely on two fronts:
- Improving model accuracy: Using advanced supervised fine-tuning (SFT) and reinforcement learning (RL) techniques, the team trained a suite of compact open-source models that deliver state-of-the-art accuracy and response quality — while remaining efficient enough for real-time voice interactions.
- Achieving real-time inference: They then paired it with real-time inference powered by custom draft models and deep engine-level optimizations from Modal’s specialized LLM inference team.
Decagon Voice 2.0 now has a 65% reduction in latency along with significant gains in intent recognition and response quality, setting a new standard for what’s possible in voice AI interactions.
Part 1: Improving model generalization through data, SFT, and RL
Building a low-latency voice experience requires using smaller parameter models without sacrificing overall model accuracy. Early small-model experiments stalled on generalization: accuracy was not effectively carrying over to new domains. To overcome this barrier, the team employed a combination of state-of-the-art methodologies across data preparation, supervised fine-tuning (SFT), and reinforcement learning (RL) training schemas.
On the data front, Decagon focused on building diversity and robustness. They constructed a broad, augmented dataset spanning multiple verticals, conversational tones, and intent types to reduce overfitting and improve cross-domain transfer.
Within SFT, they explored curriculum learning to structure training progression and mixed-objective fine-tuning to preserve the model’s instruction-following ability.
The final breakthrough came when reinforcement learning techniques were applied to refine model behavior. By combining these approaches, the team surpassed frontier off-the-shelf performance of larger state-of-the-art models with a much smaller fine-tuned model.
Modal’s training solutions made that process frictionless. By providing high-GPU-concurrency sweeps, persistent volumes, and observability tools, engineers could easily launch, monitor, and compare fine-tuning runs without worrying about cluster orchestration or storage plumbing. This accelerated Decagon’s ability to train and iterate on a set of models that generalized effectively across customer conversations.
Part 2: Achieving real-time performance with custom draft models and runtime engineering
Voice AI conversations need sub-second responses to feel natural. To reach that bar, Decagon required more than just an accurate target model; they needed an inference pipeline optimized for speed. Modal’s inference team contributed on two fronts: training a specialized draft model and re-engineering the serving engine.
Training a custom speculator
Speculative decoding is a technique that accelerates inference by pairing a target model with a smaller “speculator” (or draft model). The draft model rapidly proposes candidate tokens, and the target model verifies them. When many of those proposals are accepted, the system skips ahead, cutting generation time dramatically.
Off-the-shelf EAGLE3 draft models showed limited accept lengths when paired with Decagon’s target model. To address this, Modal’s team forked SpecForge and built a custom training pipeline for EAGLE3 draft models — first pre-training on broad conversational data, then fine-tuning using Decagon’s domain dataset.
The resulting draft model achieved 38% higher accept lengths than open-source baselines, unlocking a major leap in inference efficiency.
Re-engineering SGLang for real-time
While the custom draft model provided a major speedup, more performance gains could be unlocked at the runtime layer. By digging into SGLang — the open-source inference engine used to serve the models — Modal uncovered some optimization opportunities that ultimately made real-time inference feasible.
SGLang’s synchronous design introduced two main bottlenecks:
- CPU stalls in the critical path capped GPU utilization.
- No async scheduler for low-latency speculative decoding.
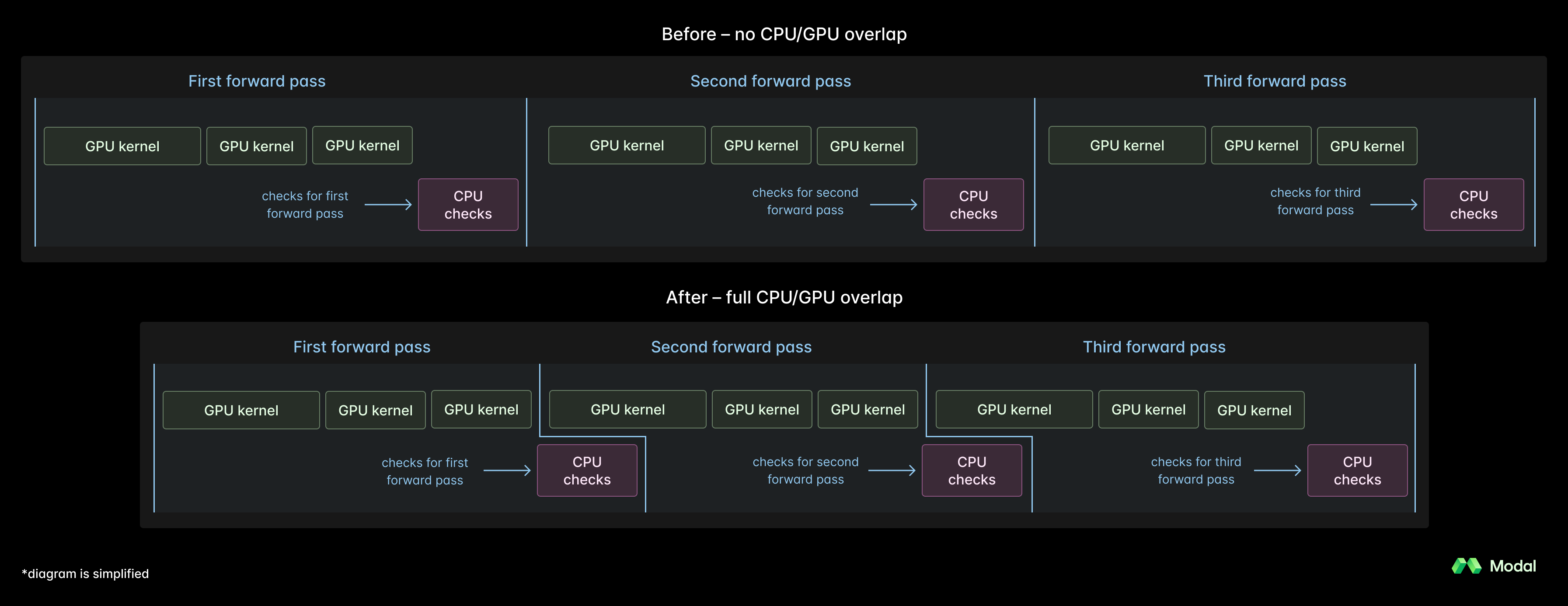
To overcome these limitations, the team built a new asynchronous scheduler for speculative decoding. This eliminated host-side inefficiencies, enabled GPU kernels to run in parallel rather than serially, and made SGLang effectively sync-free for speculative decoding.
These changes completely eliminated idle time on H200 GPUs and improved throughput by up to 12%. The improvements are already being upstreamed to SGLang in this PR.
Decagon was able to achieve a p90 latency of 342ms, well below the sub-second range required for natural customer conversations — delivering speed, efficiency, and enterprise-scale reliability.
What’s next for Decagon and Modal
Building real-time voice AI at scale is one of the toughest infrastructure challenges, combining the demands of large-model training with the latency constraints of interactive systems. Together, Decagon and Modal pushed the boundaries on both fronts, pairing advanced fine-tuning and reinforcement learning techniques with deep runtime optimizations.
Modal’s infrastructure powered this progress, enabling Decagon to train and serve increasingly capable models while scaling seamlessly to meet rapidly growing traffic. As Decagon’s platform continues to evolve, Modal’s systems will keep supporting the next generation of real-time AI experiences — training more models, serving them faster, and helping shape the future of conversational intelligence.