Reinforcement learning is an infrastructure problem
Reinforcement Learning (RL) to post-train LLMs has exploded in popularity on Modal.
We've helped teams of all sizes, from research labs to established enterprises, build training systems to achieve frontier cost-performance from foundation models. What we realized is that the present bottleneck of RL is infrastructure.
Today, we want to share what we've learned from running RL post-training at scale, along with an open-source library we built so you don't have to learn it the hard way.
The shape of the problem
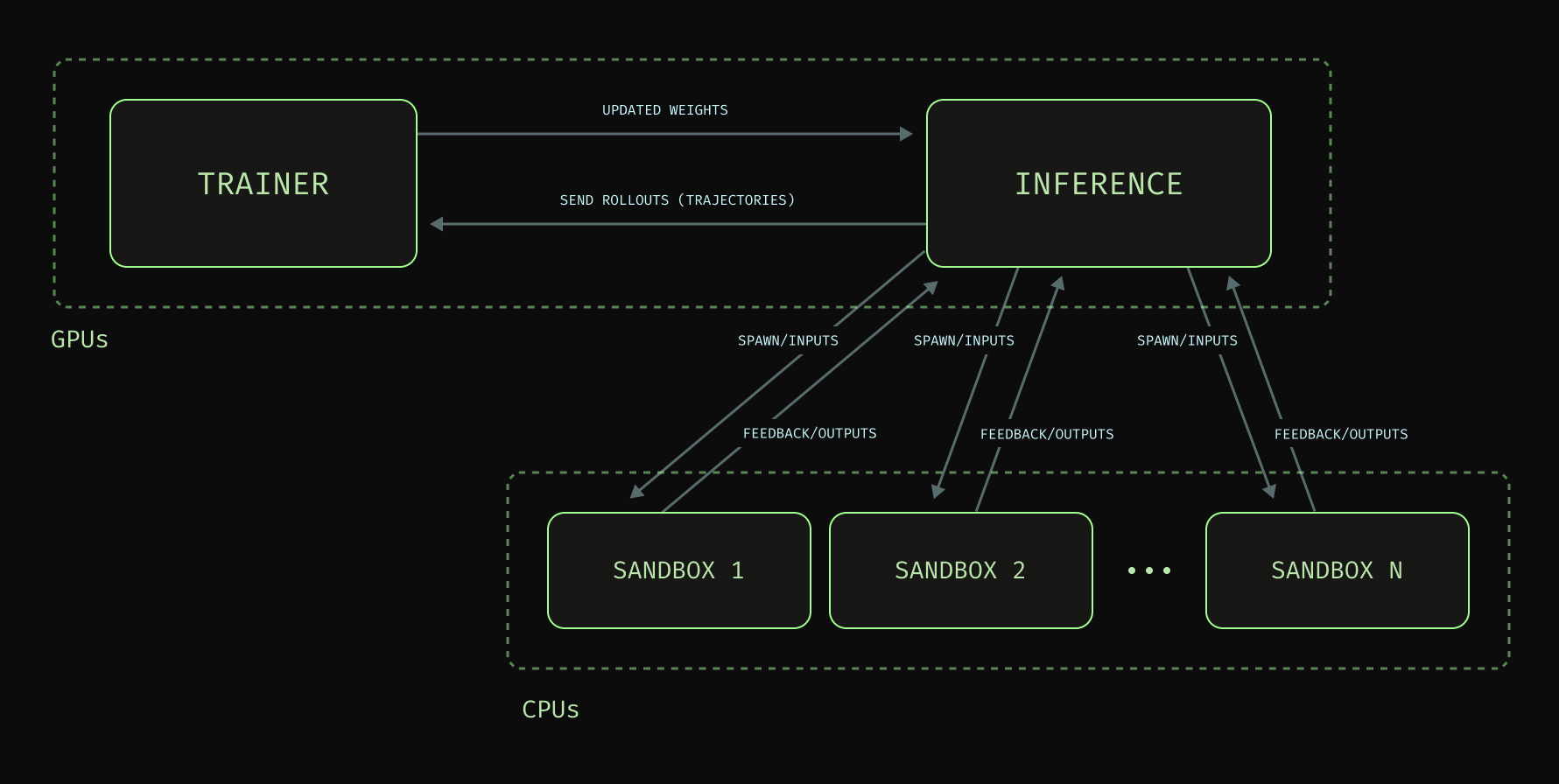
An RL training loop is a whole divided into three parts, each of which is an independently difficult infrastructure problem.
- Training with an engine that can run forward passes, backward passes, and weight updates reliably and at the scale of useful foundation models (billions to trillions of parameters).
- Rollouts from high-performance inference engines that can serve large models near the speed of light on one, or many, of the latest GPUs (from one card to hundreds).
- Isolated environments where your model policies can become actions concurrently at a consistent rate that matches your rollouts (thousands to millions of containers).
What's changed in the last year: Going multi-node
More teams are fine-tuning open-weights models. They are shipping AI to production, not just cobbling together demos for executives with a vague "AI mandate", and many of those products are rapidly maturing. At the same time, the total token cost for proprietary models at the frontier is flat or increasing, thanks to increasing reliance on test-time compute. Fortunately, multiple organizations, from NVIDIA and Google to DeepSeek and Kimi, are releasing excellent models under permissive licenses.
While small (here, under a billion parameters) models still have strong fine-tuning potential, for more complex tasks, larger models are the move. They tend to have a higher capability ceiling, better data efficiency, and less catastrophic forgetting. The cost is more VRAM to hold weights, gradients, optimizer states, & KV caches—and more bandwidth to transfer them.
Once training spans multiple GPU nodes, the weight sync between the trainer and rollout engine becomes the bottleneck. Techniques such as LoRA, async RL, or colocated trainer-rollouts each reduce the pressure, but with different tradeoffs. Even so, a training cluster is expensive, so in most cases you’re still consuming on the order of cents for every idle second.
That makes having a multi-node setup table stakes.
Within the same cluster, RDMA transfer speed improves training by 100x.
| Model | Size of weight update | Transfer speed (NCCL over TCP) | Transfer speed (NCCL over RDMA) | Reference GPU Count | Estimated Cost Savings per training step |
|---|---|---|---|---|---|
| Qwen3 8B | 16.3 GB (BF16) | 2.62 s | 41 ms | 1x8 H100 | $0.21 |
| Qwen3-30B-A3B | 61.1 GB (BF16) | 9.78 s | 153 ms | 1x8 H100 | $0.77 |
| Qwen3-30B-A3B LoRA (r=32, shared-outer) | 1.0 GB (BF16) | 160 ms | 2.5 ms | 1x8 H100 | $0.013 |
| GLM 4.7 | 716.7 GB (BF16) | 114.67 s | 1.79 s | 4x8 B200 | $36.12 |
| GLM 4.7 LoRA (r=32, shared-outer) | 4.7 GB (BF16) | 752 ms | 11.75 ms | 4x8 B200 | $0.24 |
| GLM 4.7 LoRA (r=32, per-expert) | 18.8 GB (BF16) | 3.01 s | 47 ms | 4x8 B200 | $0.95 |
| Kimi K2.6 | 595.2 GB (INT4 MoE / BF16 attn) | 95.23 s | 1.49 s | 16x8 H200 | $119.99 |
| Kimi K2.6 LoRA (r=32, shared-outer) | 9.4 GB (BF16) | 1.50 s | 23.5 ms | 16x8 H200 | $1.90 |
| Kimi K2.6 LoRA (r=32, per-expert) | 41.0 GB (BF16) | 6.56 s | 102.5 ms | 16x8 H200 | $8.27 |
This assumes 50 gbps over TCP, 3.2 tbps over RDMA.
When doing disaggregated RL, model weight update times are slow since RDMA is not connected, but using delta compression can also improve the experience.
| Model | Size | Full weights transfer time | Delta Compression |
|---|---|---|---|
| Qwen3 8B | 16 GB (BF16) | 12.8s | 0.26s |
| Qwen3 30B-A3B | 60 GB (BF16) | 48s | 0.96s |
| GLM 4.7 (~355B) | 357 GB (BF16) | 285.6s | 5.73s |
| Kimi K2.6 (~1T) | 595.2 GB (INT4, MoE / BF16 attn) | 480s | 9.6s |
This assumes 10 gbps over a WAN internet link and that Delta Compression saves 98% of the weight update magnitude.
Where teams get stuck
We found that teams got bit by the same three problems:
- Maintaining glue code
- Queueing for cluster time
- Under-utilizing GPUs
None of these are problems you'll find in your favorite RL textbook. All of them are solved by better infrastructure.
Maintaining glue
To build a good training set-up, you have to do a lot of infrastructure management. With that, an increasing proportion of your training code becomes glue code (or worse, YAML).
Where will you acquire and prepare trainer nodes? How do you bootstrap a training framework onto it? Where does the sandbox buffer and rollout buffer fit in? What happens when [REDACTED INFERENCE ENGINE] crashes your rollout node? Even though failures in training are expensive, your typical training code base has bad answers to these questions and training runs are both buggy and hard to debug.
Fortunately, Modal bundles the infra and the code. For instance, on Modal, customers can spin up an RDMA-connected, GPU-accelerated training cluster with built-in observability, fault tolerance (retries, GPU health), and autoscaling, with just a few lines of code. Look, mom, no glue!
import modal.experimental
@app.function(
gpu="H100:8",
timeout=60 * 60 * 24,
retries=modal.Retries(initial_delay=0.0, max_retries=10),
)
@modal.experimental.clustered(size=4, rdma=True)
def train_model():
cluster_info = modal.experimental.get_cluster_info()
container_rank = cluster_info.rank
world_size = len(cluster_info.container_ips)
main_addr = cluster_info.container_ips[0]
is_main = "(main)" if container_rank == 0 else ""
print(f"{container_rank=} {is_main} {world_size=} {main_addr=}")
...The single Boolean rdma=True keyword argument hides a tar pit of complexity from model trainers. As it should be! "The purpose of abstracting is not to be vague, but to create a new semantic level in which one can be absolutely precise."
The same clean abstractions structure our offerings for other components, like Sandboxes for environment execution. But maybe you've already built one of these components? Modal is a modular platform, so you can BYO any component in the training loop if you want to risk it in the glue mines.
Queuing for cluster time
Having the necessary scaffolding code is only the first step to being able to execute your training run.
We are in the midst of a compute shortage. But you don't need to listen to the Dwarkesh Podcast or buy SemiAnalysis's market model to see it. How many times have you kicked off a training job just to queue for hours?
Then, when you’re finally scheduled, the run instantly fails because you configured NCCL wrong or forgot to set some YAML value. Queues kill iteration speed, which kills engineering velocity (for humans and for agents).
8cp59fsi_89c4ec12.webp)
We have capacity. We are able to manage it with extreme efficiency and take advantage of the superior economy of multi-tenancy. With the help of our fast container boot tech, our users are able to go from zero to a B200 cluster within minutes—not hours and certainly not the days it takes on other platforms.
Under-utilizing the GPUs
So you built the spaghetti scaffolding and you have the capacity. Now you run into the last hurdle: environments bottlenecking your GPUs.
You paid for the whole GPU. You must use the whole GPU. You must never block the GPU.
To do that, you need to correctly size your sandbox buffer, a pool of sandboxes with environments prepped and ready for your rollouts. If you arbitrarily define a sandbox buffer that is too large, you eat up the cost of idle compute. If you maintain a buffer that is too small, you block the GPU with sandbox spin-up time, for every. single. rollout.
Modal Sandboxes start up in hundreds of milliseconds, so sometimes our customers forget that buffer size is something they can optimize, but every millisecond counts.
So, how do you size your buffer? A general rule of thumb is that at every inference step, there are at most batch size number of new actions, usually way less. Therefore, you only need to maintain at least one sandbox per episode/rollout so that actions are immediately processed, with no queueing. You should also factor in error rates: running many environments means you observe more failure modes and for long-running tasks, failures are more expensive.
We’ve architected Modal Sandboxes to have the scale to spin up thousands of sandboxes per second and keep up to a million concurrent at a time. This means you can evaluate all rollouts concurrently, speeding up training and keeping your GPUs fed.
To illustrate the effect that the number of concurrent sandboxes has on step duration, let’s consider the following scenario.
A single step requests 10,000 rollouts. Each sandbox is responsible for taking a simple action (e.g. code execution) that takes an upper bound of 10s to complete end to end.
You can also use features such as snapshots to skip over setup work when sandboxes are created, checkpoint agent actions, and more.
You should not worry about all of this alone!
All of this—maintaining training clusters, fighting for capacity, and managing rollouts and sandboxes—becomes a lot for a team to manage.
That’s why we find teams are turning to Modal to abstract away a lot of the gnarly details so they can focus on what actually matters: improving their environment, their reward calculation, and their training algorithms to achieve better outcomes—on the loss function and on the product surface.
Why we are betting on open source
We also want to highlight one last point: the teams we see succeeding at RL today almost universally start from an open source training framework—slime, miles, verl, OpenRLHF—rather than rolling their own.
There's a good reason: these frameworks are validated against real frontier-scale training runs. They handle the subtle parts of RL (advantage estimation, KV cache reuse, distributed weight syncs) in ways that have been stress-tested on hundreds of thousands of GPU hours.
With these frameworks, Modal currently supports our customers with SFT and RL on large models such as GLM 4.7 and Kimi K2.6, for both low-rank adaptation and full fine-tuning. There’s a lot of work we did to improve this experience, such as adding delta compression to slime. All of our improvements are being upstreamed to these open source frameworks to help everyone, not just our users, to succeed at training large models—just as we open source our improvements to kernels like FlashAttention 4 and our improvements to inference engines like SGLang.
We could have built a closed-source, managed service for training, like many others are doing. But we chose not to. Our customers use open source models and open source training frameworks on top of our infrastructure for two reasons:
- The RL ecosystem is moving too fast for any single vendor to keep up. New algorithms, base models, environment patterns, and ideas ship every week, and a static product gets stale in a quarter and is obsolete in a year. Controlling the training framework code means you (or your agent) can just implement the features you need instead of creating a ticket in someone else's task tracker.
- Modal's value isn't in owning your training loop and then enshittifying it. It's in giving you the cleanest path from a Python file to thousands of GPUs without things you don't care about getting in your way.
With Modal, anyone can train anything. And we will continue to build more infrastructure to better empower our users.
So, what’s next?
Our users create training jobs that run validated frameworks on RDMA-connected Clustered Functions, orchestrate environments in thousands of concurrent Sandboxes, and store weights in distributed Volumes for downstream evaluation and promotion to production. They can iterate their training on Modal in serene confidence that infrastructure will not bog them down. But there is still one last piece to the puzzle: onboarding and adopting these frameworks and tools is its own headache.
Tools and frameworks like slime are usually built for researchers who want every knob exposed, which means finetuning a model to cat "hello world" to a file is often 2,000 lines of configuration and another pile of glue code.
Every team we worked with was doing roughly the same scaffolding work over and over: wiring up multi-node clusters, plumbing environments, and building more observability.
So we decided to abstract away the final piece of glue infrastructure.
Introducing the Modal Training Gym
In the past month, we built an experimental library with the common abstractions that our customers care about.
To honor the ones who came before, we call it the Modal Training Gym, and you can access it on GitHub here. With this library, you can define a training job in under 100 lines of code. All you need to do is specify and configure the things you care about: a reward function, model, and an environment.
The Training Gym is the layer of abstraction on top of Modal that we wanted as training users ourselves. It comes with built-in training observability, a set of RL tutorials, and great agent DX. Download it, tell your coding agent to “train a model that does X with Y” and just let it rip.
pip install -q git+https://github.com/modal-projects/training-gym.git@mainWe are rapidly adding features to this over the next few months, and we are actively looking for design partners. If this is interesting to you, please come talk to us.
Let’s define the future shape of open source training on Modal together.