Product updates: Modal Notebooks, sandbox idle timeouts, and more
📓 Modal Notebooks
Modal Notebooks allow you to experiment and collaborate on Python code in Modal’s cloud, no setup required. Attach custom images and distributed volumes, accelerate your code with up to 8 B200 GPUs, collaborate in real time, and share your work on the web.
To get started, open modal.com/notebooks or read more here.
⌛ Sandbox Idle Timeouts
You asked, we listened. Users are now able to provide an optional idle_timeout parameter to modal.Sandbox.create(). When provided, Sandboxes will terminate after a specified number of seconds of idleness.
More details in our docs here!
👩💻 Client updates
Run pip install --upgrade modal to get the latest client updates. Here are some highlights from the changelog:
Added a
startup_timeoutparameter to the@app.function()and@app.cls()decorators. When used, this configures the timeout applied to each container’s startup period separately from the inputtimeout(1.1.4)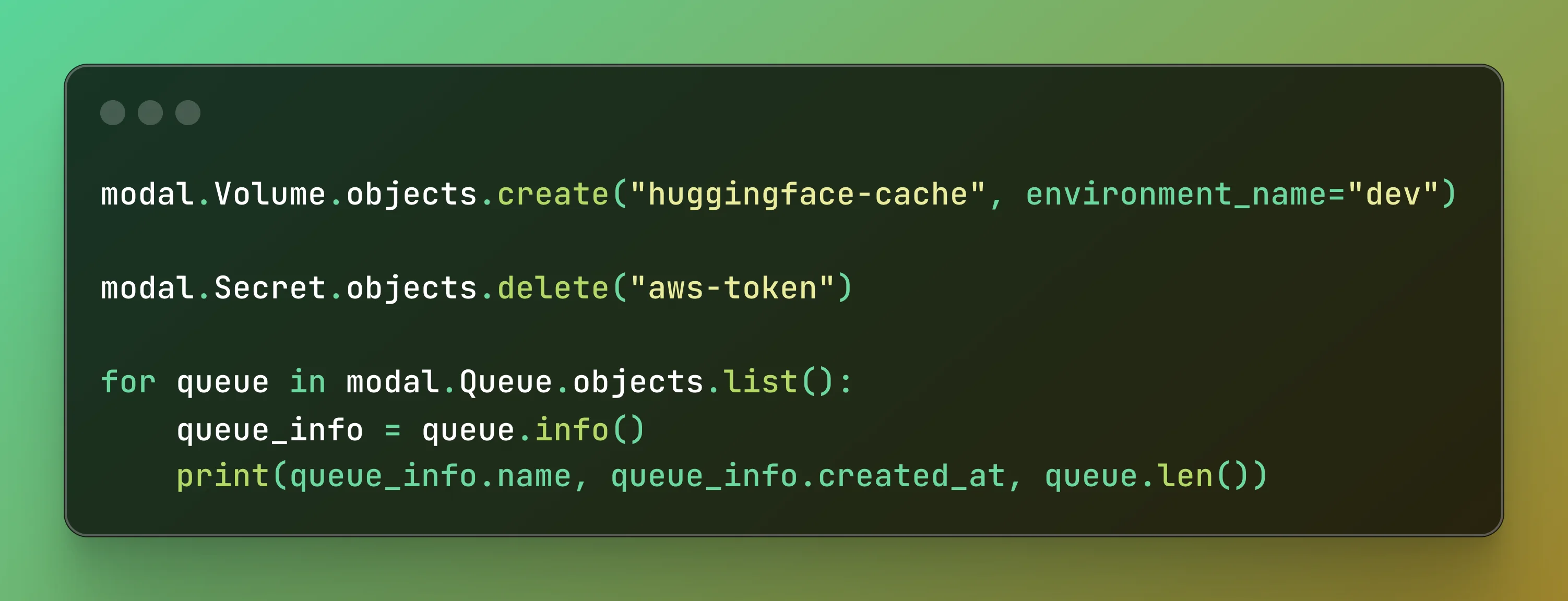
Introduced a new API pattern for imperative management of Modal resource types (
modal.Volume,modal.Secret,modal.Dict, andmodal.Queue) (1.1.2)
❤️ Customer spotlight: Zencastr
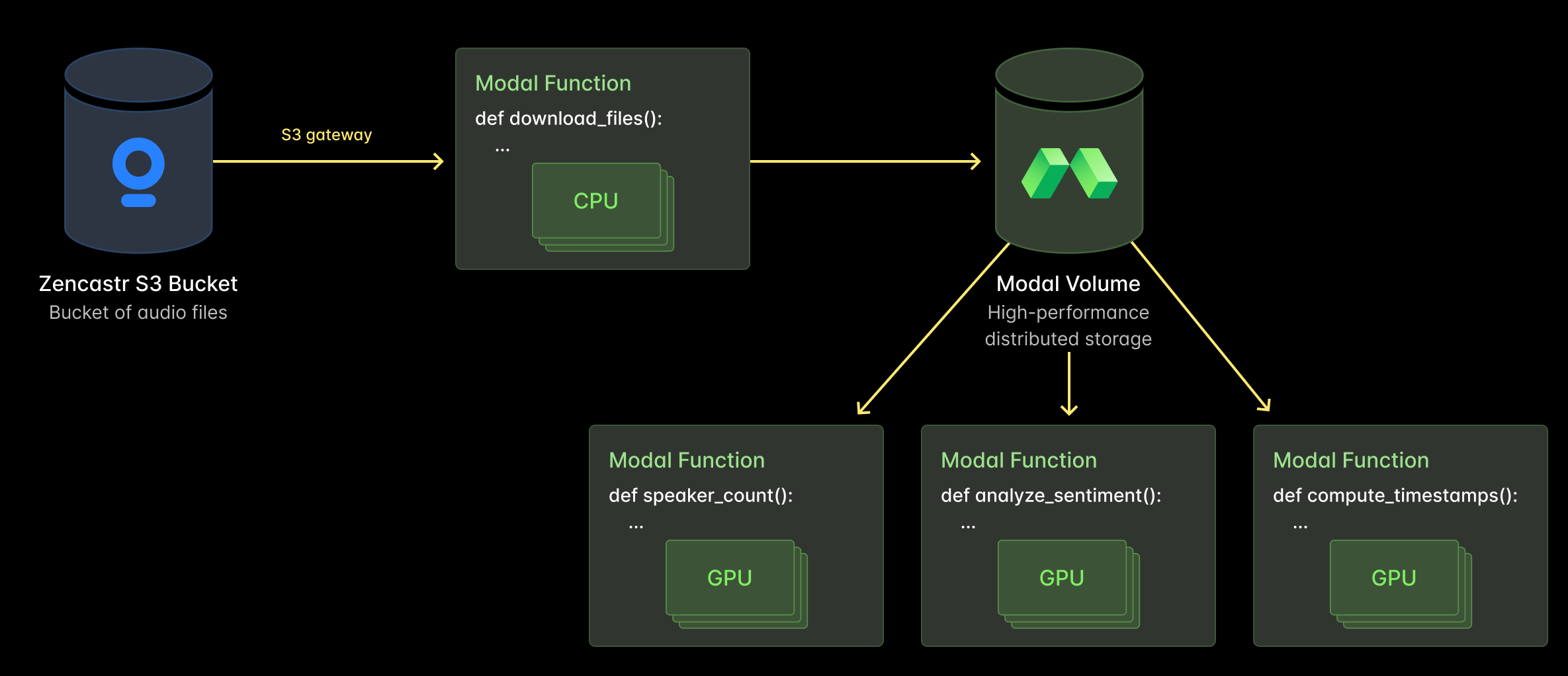
Zencastr uses Modal to power their audio processing workloads, including AI-powered transcription, speaker counting, and audio quality scoring. During one run, Zencastr scaled up to 1,500 concurrent GPUs within minutes to enrich all of their podcast content. Read the full case study here.
🏎️ GPU Performance Glossary

For GPUs and their applications, performance is the product. That’s why we extended our popular “CUDA docs for humans”, the GPU Glossary, with a new section on performance. We cover everything from warp divergence at the assembler level to memory-bound LLM inference napkin math to the roofline model from quantitative computer architecture.
Read it here.
🦥 Finetune an LLM with Unsloth
Unsloth provides optimized methods for LLM finetuning with LoRA and quantization, leading to 2x faster training with 70% less memory usage. Learn how to use Unsloth to finetune a version of Qwen3-14B with the FineTome-100k dataset on Modal using only a single GPU! Check it out here!
🗣️ Finetune an ASR model with Whisper
In this example, we demonstrate how to fine-tune OpenAI’s Whisper model to improve transcription accuracy. Learn how to fine-tune and deploy the model on Modal here!
📅 Upcoming events

- We’re co-hosting an invite only “Modern Infrastructure in Biotech” Panel and Mixer in Boston on Wednesday. October 1! Hear biotech founders, engineers, and scientists share candid takes on what’s working (and what’s still broken) in infra + AI for bio. Stick around after for food, drinks, and networking with fellow builders at the intersection of bio 🧬 and tech 💻. Seats are limited: RSVP here

- We’re headed to Vapicon in SF on Thursday, October 2! Catch Modal co-founder Erik Bernhardsson on the Voice AI Infrastructure: How to Scale and Achieve 99.999? panel at 3:10pm. Snag 20% off your ticket with code “BERNHARDSSON20”
- We are also hosting an intimate, invite-only Voice AI dinner after the conference with Daily and Rime. Register here.