How Zencastr transcribed hundreds of years worth of audio in just a few days
Zencastr is a leading podcast platform that empowers creators with everything they need to record, produce, and host their shows. With thousands of creators on the platform, Zencastr is helping bring millions of podcast episodes to life with high-quality production tools and AI-powered enhancements.
One of Zencastr’s core products is speech transcription, which includes features like forced alignment, verbatim words, timestamps, and more. While they started off using transcription models that could run on CPUs, they decided a couple years ago to move to transformer-based models like Whisper, which delivered better transcription quality but more effectively ran on GPUs.
As Zencastr continued to grow, their infrastructure requirements became more complex. So, they found Modal. Modal not only gave them a scalable, cost-efficient GPU platform, but also helped Zencastr rapidly provide high-quality transcriptions for their users by scaling to 1,500 concurrent GPUs instantly and effortlessly.
The problem: Kubernetes isn’t built for AI workloads
Initially, Zencastr managed GPU nodes themselves on Kubernetes. This was both costly and introduced significant devops overhead.
- Cost at scale: Transcription workloads at Zencastr are very spiky—peaking around midday and dipping at night or during holidays. But their old setup required keeping GPU nodes online at all times, leading to significant over-provisioning and wasted spend. They had no way to dynamically scale down GPU infrastructure during off-hours, which made costs difficult to optimize.
- Infra management overhead: Supporting multiple ML models and workloads meant constantly juggling a web of GPU driver versions and ML framework dependencies. Each model had its own unique runtime environment requirements, whether that was completely different dependencies or different versions of the same dependency. There wasn’t an easy way to guarantee that correct drivers and packages were installed in any given machine.
Zencastr also evaluated other AI platforms, but they lacked performant cold starts for custom models and didn’t offer enough control over things like scaling behavior.
The fix: Modal handles the infrastructure so AI teams can focus on AI
After experimenting with Modal, Zencastr discovered that they could save on GPU cost while also rapidly accelerating development. Modal satisfied several key requirements:
- True scale-to-zero: Zencastr no longer pays for idle GPU time — Modal automatically flexes capacity up and down so they only pay when jobs are running.
- Seamless management of remote environments: Using Modal Images, which can be defined programmatically rather than in config files, Zencastr is able to easily keep different models and their requirements in sync. Modal’s pre-installed, up-to-date CUDA drivers for all GPU containers also take away the pain of dependency management.
- Flexibility to experiment with GPU models and concurrency: Modal also made it easy for Zencastr to optimize large jobs by trying different GPU models and concurrency settings. They could quickly compare how long the same workload would take under various configurations, without touching the source code. This gave them more control over performance trade-offs and cost efficiency when running at scale.
Having these features built-in dramatically increased the team’s iteration speed. Tasks that previously took days, like configuring environments or troubleshooting driver issues, now take just hours, significantly shortening the ML team’s iteration cycles.
Now, all core ML workloads run on Modal. This includes:
- AI-powered transcription for every podcast episode on the platform
- Speaker counting and laughter detection for content analysis
- Audio quality scoring and post-production enhancements
Bonus: scaling batch audio processing to 1500 GPUs
As part of the process of training their own models, Zencastr needs to enrich historical audio data with new features. These large-scale batch jobs require high parallelization across GPUs.
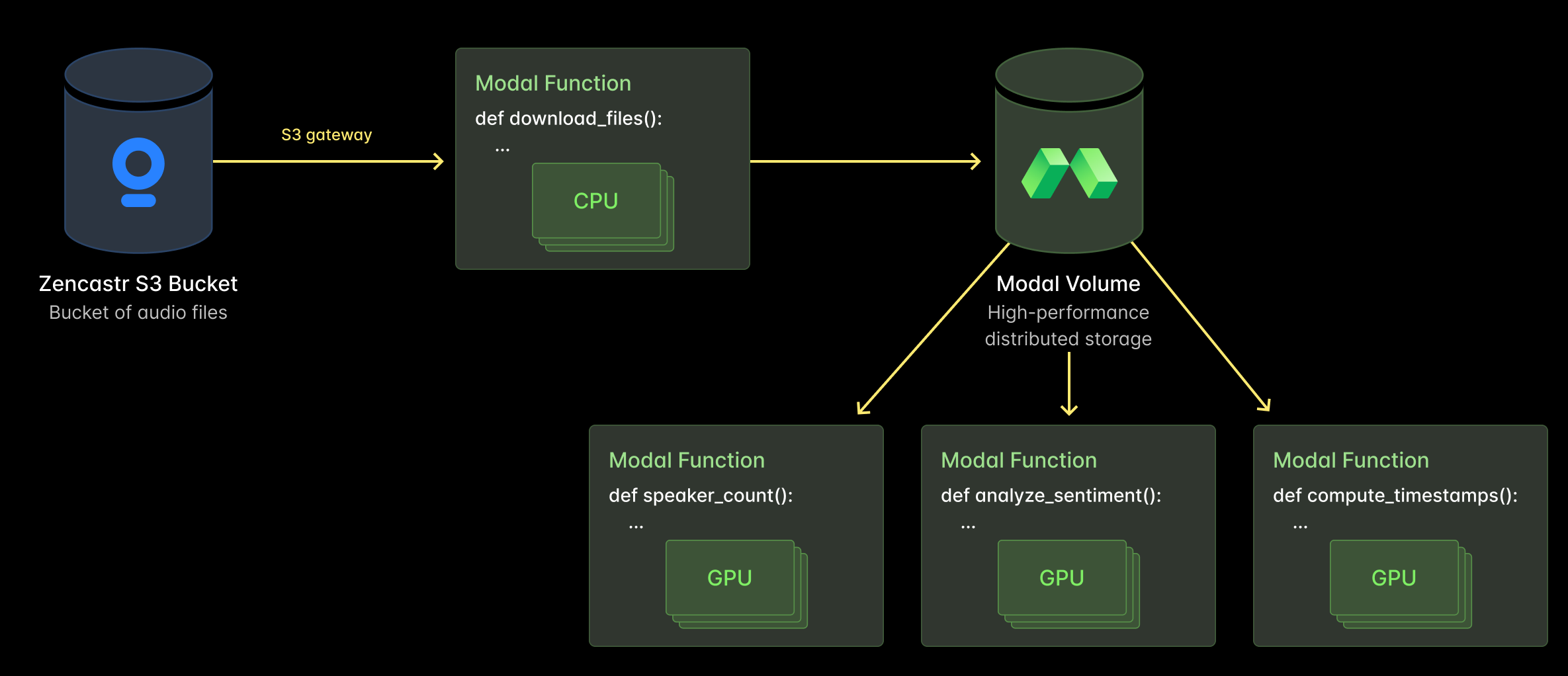
These batch jobs are straightforward to set up on Modal:
- A Modal Function is used to download audio files from their servers. This happens via an S3 Gateway endpoint to avoid egress fees.
- The files only need to be downloaded once, because they’re then moved to a Modal Volume. This is Modal’s distributed storage primitive that enables fast reads.
- Multiple audio features are extracted at the same time, via different Modal Functions that all pull from the same Volume.
During one run, Zencastr scaled up to 1,500 concurrent GPUs within minutes to enrich all of their podcast content. Despite the massive scale, Modal’s infrastructure was resilient and stable throughout. No additional devops work was required from Zencastr to make this happen.
Powering the future of podcasting
Zencastr continues to explore new ways to leverage Modal, like training voice-adjacent models.
Modal is proud to power Zencastr’s compute-heavy infrastructure as they build the future of AI-enabled podcasting.