
GLM 5.2 FP8
zai-org/GLM-5.2-FP8
Large model good for coding, agents, and tool use.
modal endpoint create --model zai-org/GLM-5.2-FP8 “Our ML engineers want to use Modal for everything. Modal helped reduce our VLM document parsing latency by 3x and allowed us to scale throughput to >100,000 pages per minute.”
“Modal powers both our reinforcement learning infrastructure and production inference. Millions of sandboxes on one end, real-time serving on the other.”
“Modal makes it unbelievably quick to deploy our models onto scalable infrastructure. We’ve been able to move faster on our last few model launches, including Olmo and Tülu, thanks to the platform.”
zai-org/GLM-5.2-FP8
Large model good for coding, agents, and tool use.
modal endpoint create --model zai-org/GLM-5.2-FP8 '%20fill-rule='nonzero'%20/%3e%3cdefs%3e%3clinearGradient%20id='qwen-color-gradient'%20x1='0%25'%20x2='100%25'%20y1='0%25'%20y2='0%25'%3e%3cstop%20offset='0%25'%20stop-color='%236336E7'%20stop-opacity='.84'%20/%3e%3cstop%20offset='100%25'%20stop-color='%236F69F7'%20stop-opacity='.84'%20/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e "Qwen")
Qwen/Qwen3.6-35B-A3B
Model tuned for fast chat, reasoning, and extraction.
modal endpoint create --model Qwen/Qwen3.6-35B-A3B '%20fill-rule='evenodd'%20/%3e%3c/svg%3e "Google")
google/gemma-4-E4B-it
Compact instruction model for lightweight workloads.
modal endpoint create --model google/gemma-4-E4B-it Select from our full catalog of models, or bring your own weights from Hugging Face or a Volume.
4x faster with custom speculator models
Engineered for low-latency, high-throughput inference
Optimized for your workload
Modal’s Rust-based container stack spins up GPUs in < 1s.
Modal autoscales up and down for max cost efficiency.
Modal’s proprietary cloud capacity orchestrator guarantees high GPU availability.
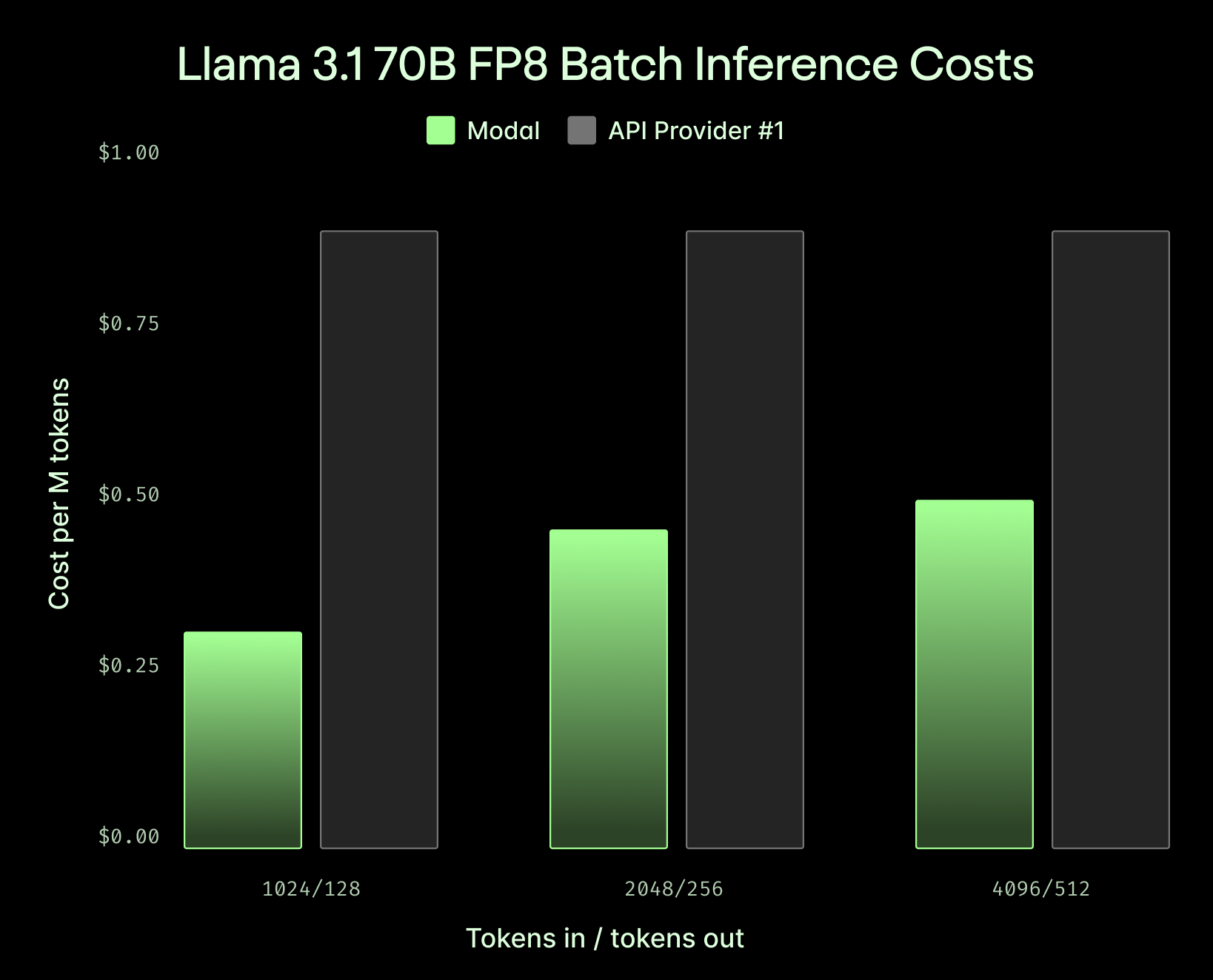
Unbeatable cost for batch inference
Save 50%+ on high-throughput, short-context tasks compared to API providers.
Sub-10ms network latency for online inference
Global GPU fleet runs close to your users, wherever they are. Support for inference optimizations like prefill disaggregation and prefix-aware routing.
Volumes
Load LLM weights quickly from any region.
Observability
Intuitive dashboards help you navigate the health of your deployments.
Enterprise-grade security
SOC2 and HIPAA compliance, zero data retention, and more.


'%3e%3cpath%20d='M16.889,8.985L16.889,6.28C17.151,6.26%2017.417,6.247%2017.687,6.238C25.087,6.006%2029.942,12.597%2029.942,12.597C29.942,12.597%2024.698,19.879%2019.076,19.879C18.333,19.882%2017.594,19.764%2016.889,19.529L16.889,11.325C19.769,11.673%2020.349,12.945%2022.081,15.833L25.933,12.585C25.933,12.585%2023.121,8.897%2018.381,8.897C17.866,8.897%2017.373,8.933%2016.889,8.985ZM16.889,0.047L16.889,4.09C17.154,4.069%2017.42,4.052%2017.687,4.042C27.977,3.696%2034.682,12.482%2034.682,12.482C34.682,12.482%2026.982,21.846%2018.959,21.846C18.224,21.846%2017.535,21.778%2016.889,21.663L16.889,24.161C17.442,24.231%2018.015,24.273%2018.613,24.273C26.078,24.273%2031.477,20.461%2036.705,15.948C37.572,16.642%2041.121,18.331%2041.85,19.071C36.879,23.231%2025.295,26.586%2018.727,26.586C18.113,26.584%2017.5,26.552%2016.889,26.49L16.889,30L45.264,30L45.264,0.047L16.889,0.047ZM16.889,19.529L16.889,21.662C9.984,20.432%208.067,13.254%208.067,13.254C8.067,13.254%2011.383,9.58%2016.889,8.985L16.889,11.325L16.878,11.324C13.988,10.977%2011.731,13.677%2011.731,13.677C11.731,13.677%2012.996,18.221%2016.889,19.529ZM4.625,12.943C4.625,12.943%208.717,6.903%2016.889,6.28L16.889,4.088C7.838,4.815%200,12.48%200,12.48C0,12.48%204.439,25.313%2016.889,26.488L16.889,24.16C7.753,23.011%204.625,12.943%204.625,12.943Z'%20style='fill:rgb(118,185,0);'/%3e%3c/g%3e%3c/svg%3e "NVIDIA")
