Batch and real-time ASR with scalability built-in
“Modal has been a really nice, scalable solution for audio transcription. We don’t have to worry about pre-allocating GPUs weeks ahead of time – we can spin up 1500 GPUs in minutes and it just works.”
“Modal makes it easy to write code that runs on 100s of GPUs in parallel, transcribing podcasts in a fraction of the time.”
Deploy state-of-the-art ASR models in minutes
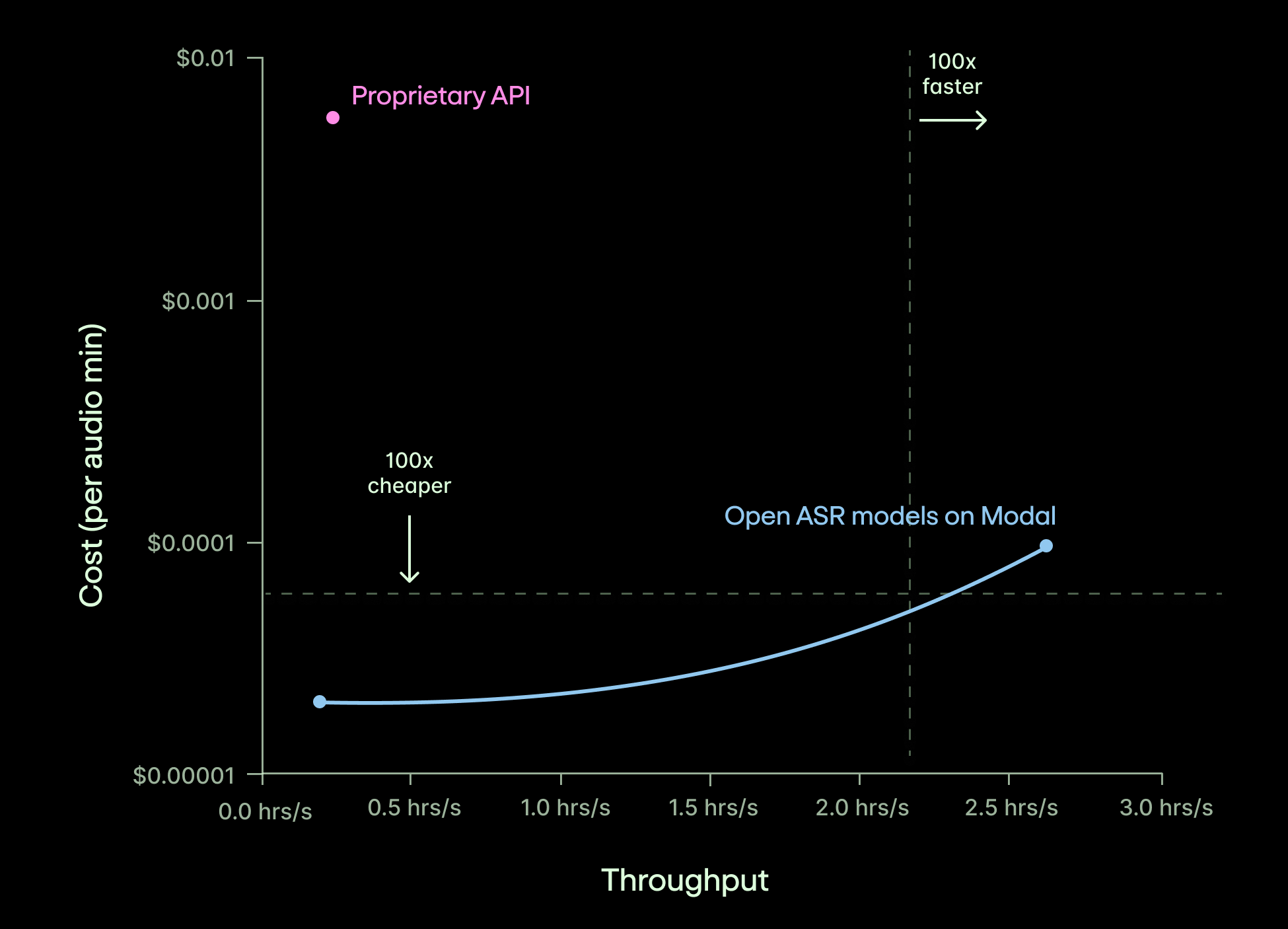
Outperform proprietary ASR
Get higher accuracy and 100x cheaper + faster transcription when you deploy the latest open-source ASR models on Modal.
Transcribe millions of hours of audio
Process 1M transcription jobs with Modal Batch. Leave the distributed systems to us.
Instant scaling. Modal’s Rust-based container stack provisions GPUs in less than a second.
Guaranteed GPU capacity. Modal’s cloud capacity orchestrator is robust to demand spikes.
Deploy low-latency transcription for real-time voice agents
Achieve 100ms latency with WebRTC on Modal. Get GPUs wherever your users are.
Integrate with your favorite voice AI frameworks like Pipecat and LiveKit
Serve best-in-class models for real-time ASR, like Kyutai or RealtimeSTT
Fine-tune ASR models without the black box

Achieve lower word error rates for your specific domain.
Iterate quickly on training code without managing cloud environments.
Fan out experiments on Modal’s autoscaling container infra.