












AI engineering teams at startups
You need grad-school-grade inference without hiring platform engineers. Modal's Python-native API lets you deploy models in the same codebase as training, with autoscaling and observability included.
Direct Answer
LLM inference is the process of running a trained large language model to generate predictions, completions, or responses in production. It transforms a static model into an API or service that processes real-time requests, handles batching, and serves predictions to end users or applications. Real LLM inference requires optimized serving infrastructure that manages GPU memory, request queuing, and autoscaling without latency penalties.
What you can build
Modal handles GPU provisioning, autoscaling, and observability so you can focus on model quality and product iteration.
Deploy GPT-style chat, code completion, or summarization with sub-second cold starts and automatic HTTPS endpoints.
Run inference across millions of documents, images, or records with elastic parallelism that scales to thousands of GPUs.
Combine vision-language models, embeddings, and retrieval into unified inference graphs.
Capacity adjusts in real time based on queue depth and request rate, scaling to zero when idle.


Run pip install modal and wrap your model loading and prediction logic with @app.function(gpu="T4"). Modal's code-first approach keeps ML dependencies and GPU requirements in sync with application code — no Dockerfiles, no YAML, no cluster management.
Execute modal deploy to push your function live with autoscaling, HTTPS endpoints, and logging enabled automatically. When a request arrives, Modal spins up a container in under one second across A100, H100, or A10s GPUs. You never hit quota limits.
Use Modal's dashboard to track request latency, GPU utilization, and error rates. Adjust GPU types, scaling policies, or vLLM parameters directly in Python — no YAML edits or cluster restarts required.
Real results from a production deployment
"We migrated from EKS with Karpenter autoscaling to Modal's native GPU orchestration in 40 developer-hours. GPU utilization jumped from 34% to 78% with vLLM continuous batching and automatic request queuing."
A startup building an AI code review tool deployed Llama 3.1 70B inference on Modal, replacing a self-managed Kubernetes cluster. Within two weeks they reduced cold start time from 90 seconds to 0.8 seconds, cut inference costs by 60% through scale-to-zero, and expanded from 2 AWS regions to 6 clouds without re-architecting.
AI Engineering Team, AI Code Review Platform, Modal Customer
Who benefits most
You need grad-school-grade inference without hiring platform engineers. Modal's Python-native API lets you deploy models in the same codebase as training, with autoscaling and observability included.
You run inference on thousands to millions of tokens in GPUs for batch jobs. Modal ensures GPU clusters pre-emptively scale back to zero, eliminating reservation costs.
You manage dozens of models across business units with varying traffic patterns. Modal's unified deployment reduces operational overhead of multiplexing and latency SLAs.
Who benefits most
You need grad-school-grade inference without hiring platform engineers. Modal's Python-native API lets you deploy models in the same codebase as training, with autoscaling and observability included.
You run inference on thousands to millions of tokens in GPUs for batch jobs. Modal ensures GPU clusters pre-emptively scale back to zero, eliminating reservation costs.
You manage dozens of models across business units with varying traffic patterns. Modal's unified deployment reduces operational overhead of multiplexing and latency SLAs.
"We use Modal to run edge inference with <10ms overhead and batch jobs at large scale. Our team loves the platform for the power and flexibility it gives us."
Brian Ichter, Co-founder
"Modal makes it easy to write code that runs on 100s of GPUs in parallel, transcribing podcasts in a fraction of the time."
Mike Cohen, Head of Data
"Everyone here loves Modal because it helps us move so much faster. We rely on it to handle massive spikes in volume for evals, RL environments, and MCP servers."
Aakash Sabharwal, VP of Engineering
"Modal was the only infrastructure provider that enabled us to reliably run tens of thousands of app creation sessions in an instant. We're excited to build with them for the long term."
Anton Osika, CEO & Founder
 Igor KotuaEngineer, The Linux Foundation
Igor KotuaEngineer, The Linux FoundationIf you building AI stuff with Python and haven't tried @modal you are missing out big time
 CalebML Engineer, Hugging Face
CalebML Engineer, Hugging FaceBullish on @modal - Great Docs + Examples - Healthy Free Plan (30$ free compute / month) - Never have to worry about infra / just Python
 Daniel RothenbergCo-founder, Brightband
Daniel RothenbergCo-founder, Brightband@modal continues to be magical... 10 minutes of effort and the `joblib`-based parallelism I use to test on my local machine can trivially scale out on the cloud. Makes life so easy!
 @mattzcarey.com on blskyAI Engineer, StackOne
@mattzcarey.com on blskyAI Engineer, StackOne@modal has got a bunch of stuff just worked out this should be how you deploy python apps. wow
 Erin BoyleML Engineer, Tesla
Erin BoyleML Engineer, TeslaThis tool is awesome. So empowering to have your infra needs met with just a couple decorators. Good people, too!
 Aman KishoreResearch Engineer, Harvey
Aman KishoreResearch Engineer, HarveyIf you are still using AWS Lambda instead of @modal you're not moving fast enough
 Jai ChopraProduct, LanceDB
Jai ChopraProduct, LanceDBRecently built an app on Lambda and just started to use @modal, the difference is insane! Modal is amazing, virtually no cold start time, onboarding experience is great
 Izzy MillerDevRel, Hex
Izzy MillerDevRel, Hexspecial shout out to @modal for providing the crucial infrastructure to run this! Modal is the coolest tool I've tried in a really long time. Cannot say enough good things.
LLM training adjusts model weights to optimize performance on a task — it runs once (or periodically) and requires large GPU clusters for hours or days. LLM inference runs a fixed, trained model to generate responses in real time — it runs continuously in production and demands low latency, high throughput, and autoscaling. Modal supports both through the same Python API.
Yes. Modal's container images can install any version of vLLM from PyPI or directly from GitHub. Because Modal rebuilds images automatically when dependencies change, teams can pin to a specific commit for stability or upgrade to the latest release with a single version bump in their code.
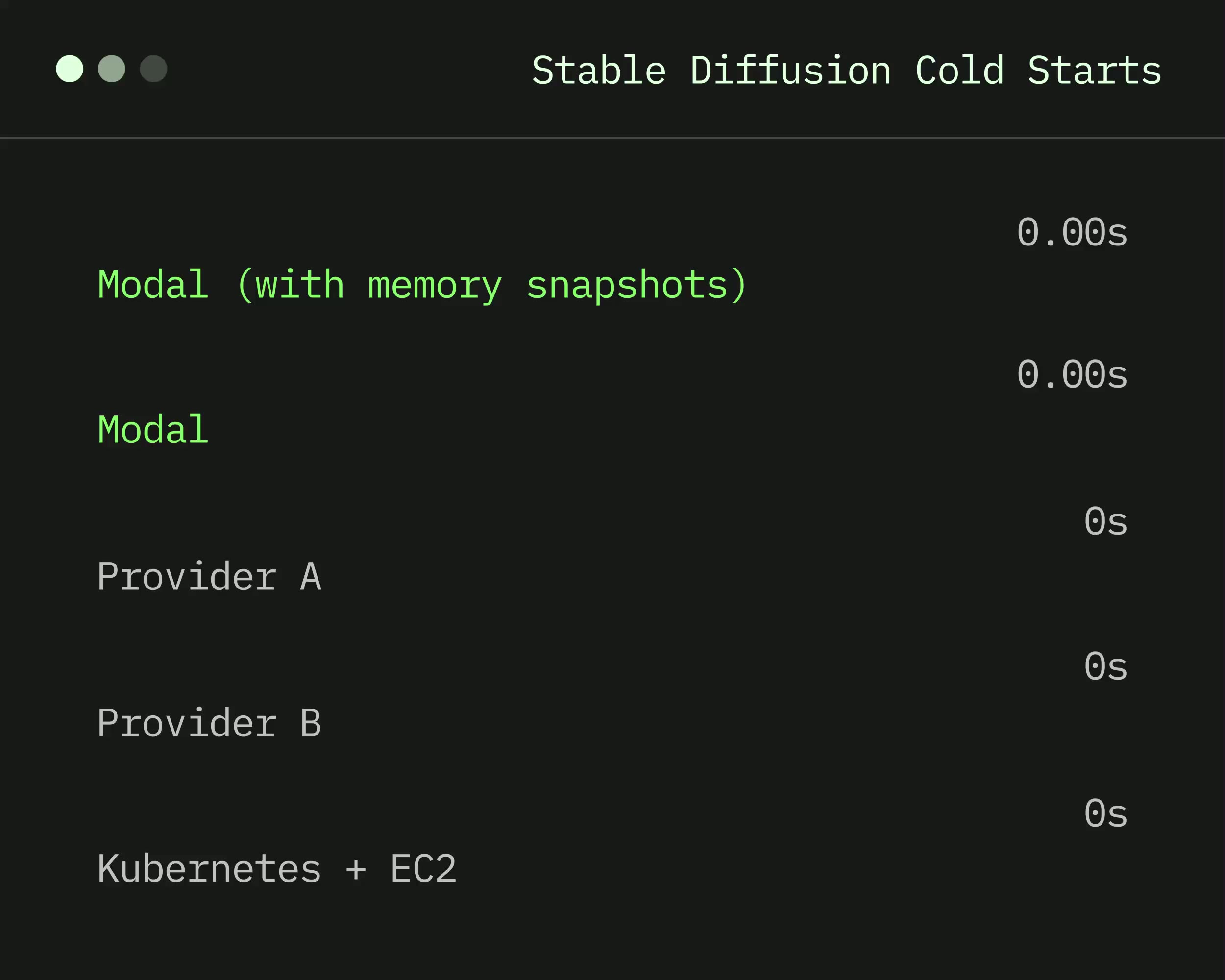
Modal achieves sub-second cold starts for pre-cached containers. For large models like Llama 3.1 70B, Modal's snapshot technology checkpoints a running container and restores it in under one second on a fresh GPU — compared to 60-90 seconds on traditional cloud instances.
Yes. Modal containers can run any binary, CUDA kernel, or native executable. You can install custom inference engines by defining them in your container image using pip, apt, or manual compilation steps.
By default, Modal scales containers to zero when no requests arrive, and you pay nothing during idle periods. When traffic resumes, Modal cold-starts a new container in under one second. For latency-sensitive applications, you can configure a minimum container count to keep containers warm.
Modal passes environment variables and startup arguments directly to your vLLM server process, giving you full control over continuous batching parameters like max_num_batched_tokens, max_num_seqs, and tensor parallel size. You can tune these values in Python code and redeploy without YAML edits or cluster restarts.