Product Updates: Modal in AWS & GCP marketplaces, Sandbox improvements, and more
Modal is available on AWS and GCP Marketplace
Enterprise customers can now purchase and manage Modal through AWS or Google Cloud Marketplaces. Existing AWS or GCP spend commitments can be applied to Modal usage.
Chat with us to learn more.
Improved Sandbox observability
We’ve shipped a round of UI updates to make Sandboxes easier to understand at a glance — including clearer resource and region details, and a new execution timeline showing each Sandbox’s full lifecycle from creation to termination
Client Updates
Run uv pip install --upgrade modal to get the latest client updates. Here are some highlights from the changelog:
- Added support for Python 3.14, including experimental support for free-threaded Python (3.14t) inside Modal containers (1.3.1)
- Added
modal token infoand-timestampsflags across key CLI commands to make authentication and logs easier to inspect (1.3.1) - Added experimental async usage warnings to help detect blocking Modal APIs used inside async contexts (1.3.0)
How Ramp built Inspect, their internal coding agent, on Modal
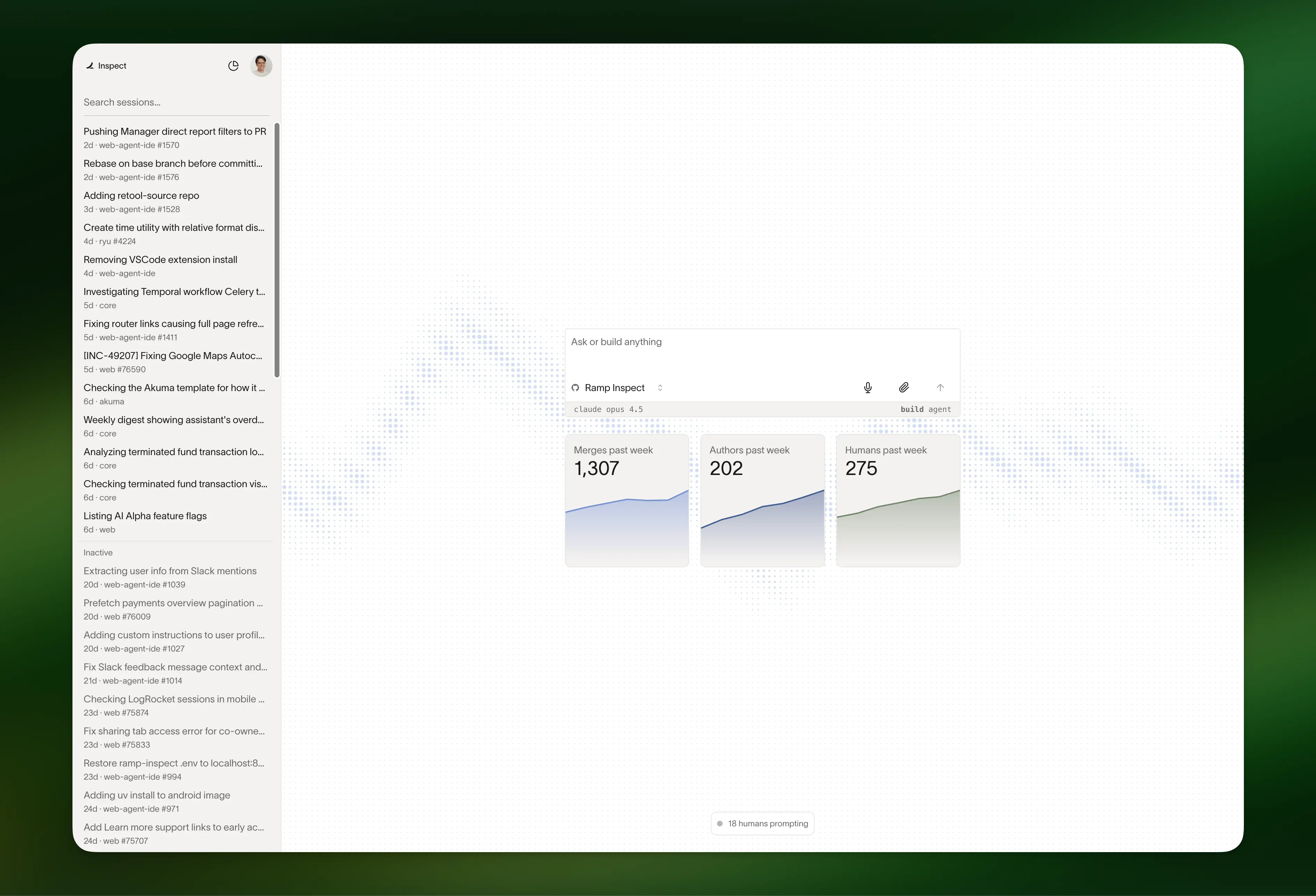
Each Inspect session runs in a sandbox on Modal with a full dev environment, instant startup, filesystem snapshots, and unlimited concurrency. It’s now used to write ~30% of Ramp’s production PRs across frontend and backend, without tying up developer laptops.
Read the full breakdown from Ramp.
Run LLM inference at maximum performance

In this deep dive, we break down the three major types of inference workloads we see in production today — offline, online, and semi-online — and explain how their performance and cost tradeoffs differ. We share concrete recommendations for engines like vLLM and SGLang, real-world examples from teams running at scale, and how to architect each workload efficiently on Modal.
Read the full post or join our virtual event to learn more.
Keeping 20,000+ GPUs healthy at scale
Modal runs a globally distributed GPU fleet across all major clouds, launching millions of instances and managing over 20,000 concurrent GPUs. In this post, we share how we test instance types, prepare machine images, continuously health-check GPUs, and monitor reliability at scale — plus lessons learned from operating at the edge of GPU failure modes.
Check out the full post.
Modal IRL this February
We’re hosting a packed month of events across NYC and SF — from reinforcement learning meetups and AI leader breakfasts to startup office hours and biotech mixers. If you’re around, come join us. Here are a few highlights:
- Cafe Compute: Feb 12 | New York
- FDEs in AI with Modal and Snowflake: Feb 18 | San Francisco
- Modal for Startups office hours: Feb 23 | San Francisco
See the full list of everything coming up.