Product updates: Multi-node training clusters, B200 and H200s, and Client 1.0 release
🏋️ Multi-node training clusters in beta
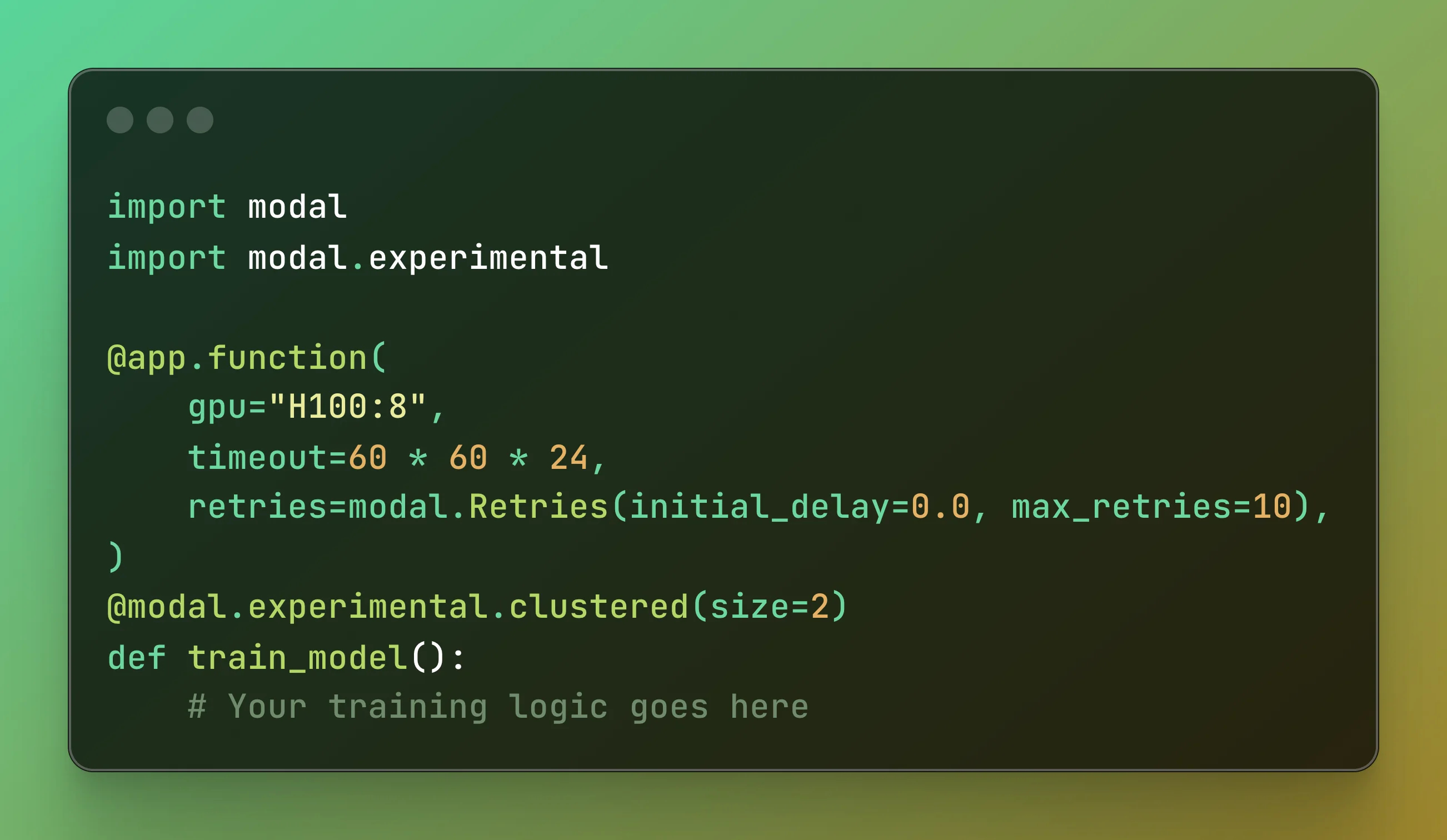
We’ve made multi-node training as easy as multi-GPU training on Modal. By simply adding the @clustered decorator, you can instantly tap into dozens of GPUs on multiple hosts, co-scheduled and co-located. And thanks to high-speed RDMA interconnect (3.2 Tbps Infiniband), those GPUs can communicate quickly enough to scale your training runs linearly with node count.
Check out the guide for more info and examples. We are actively looking for beta users, please reach out if interested!
🚀 Introducing B200s and H200s on Modal
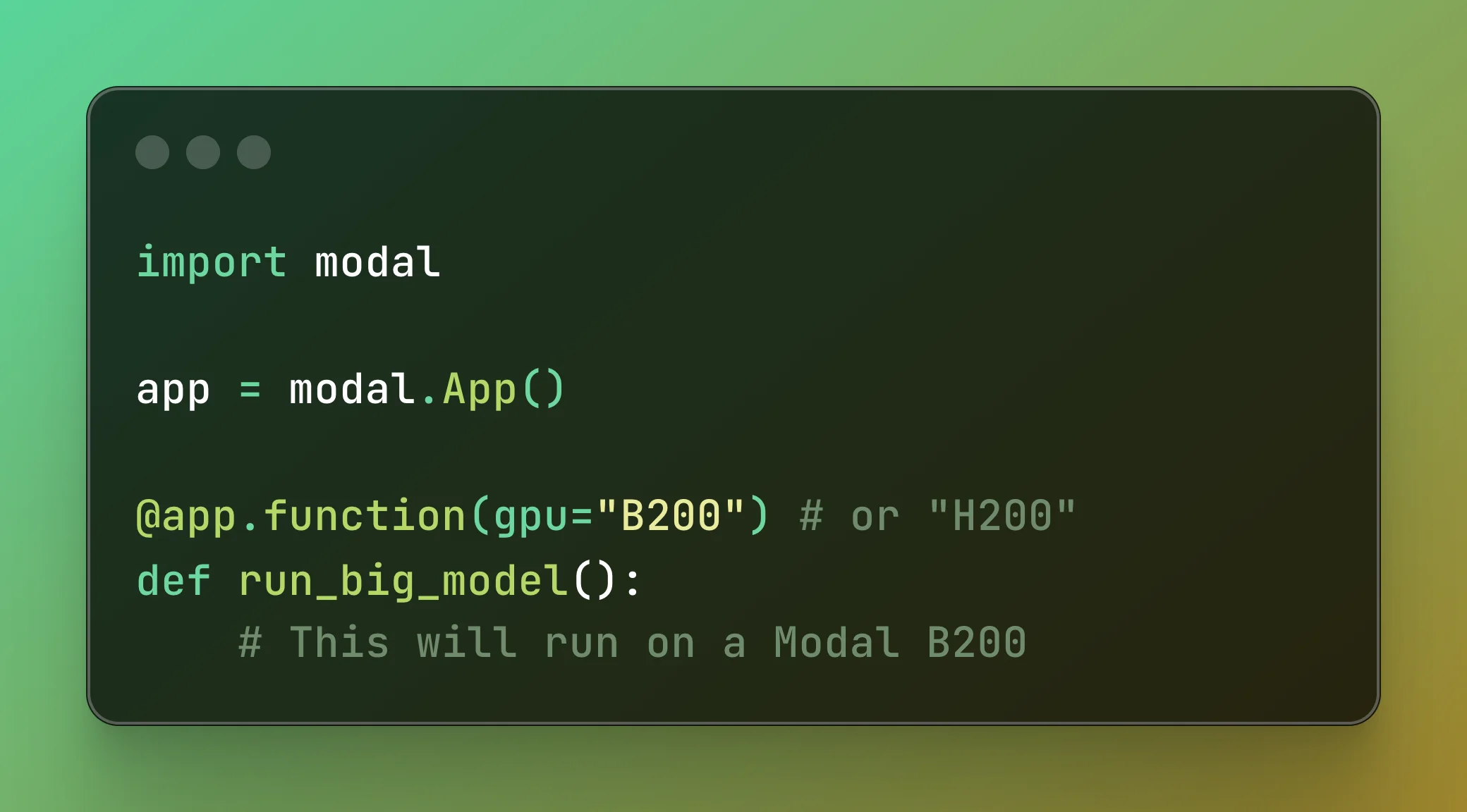
Modal now offers NVIDIA B200 and H200 GPUs serverlessly. Add a one-liner to your Modal function, pay as you go ($6.25/hr for B200, $4.54/hr for H200), and see up to 2-4× faster LLM inference compared to H100s.
See the full announcement here.
🗞️ Modal Client 1.0 release
We recently launched version 1.0 of the Modal client, underscoring our commitment to API stability and giving users more clarity and predictability. For instructions on how to migrate to 1.0, check out our migration guide.
For more insight into the design principles underlying the release, read our blog here.
👩💻 Client updates
Run pip install --upgrade modal to get the latest client updates.
- Added a
modal.Volume.read_onlymethod (1.05) - Added a
--secretoption tomodal shellfor including environment variables defined by named Secret(s) in the shell session (1.04) - Added support for specifying a timezone on
Cronschedules (1.03) - Added a
--timestampsflag tomodal app logsthat prepends a timestamp to each log line (1.01)
📊 LLM Engineer’s Almanac: SGLang or vLLM?
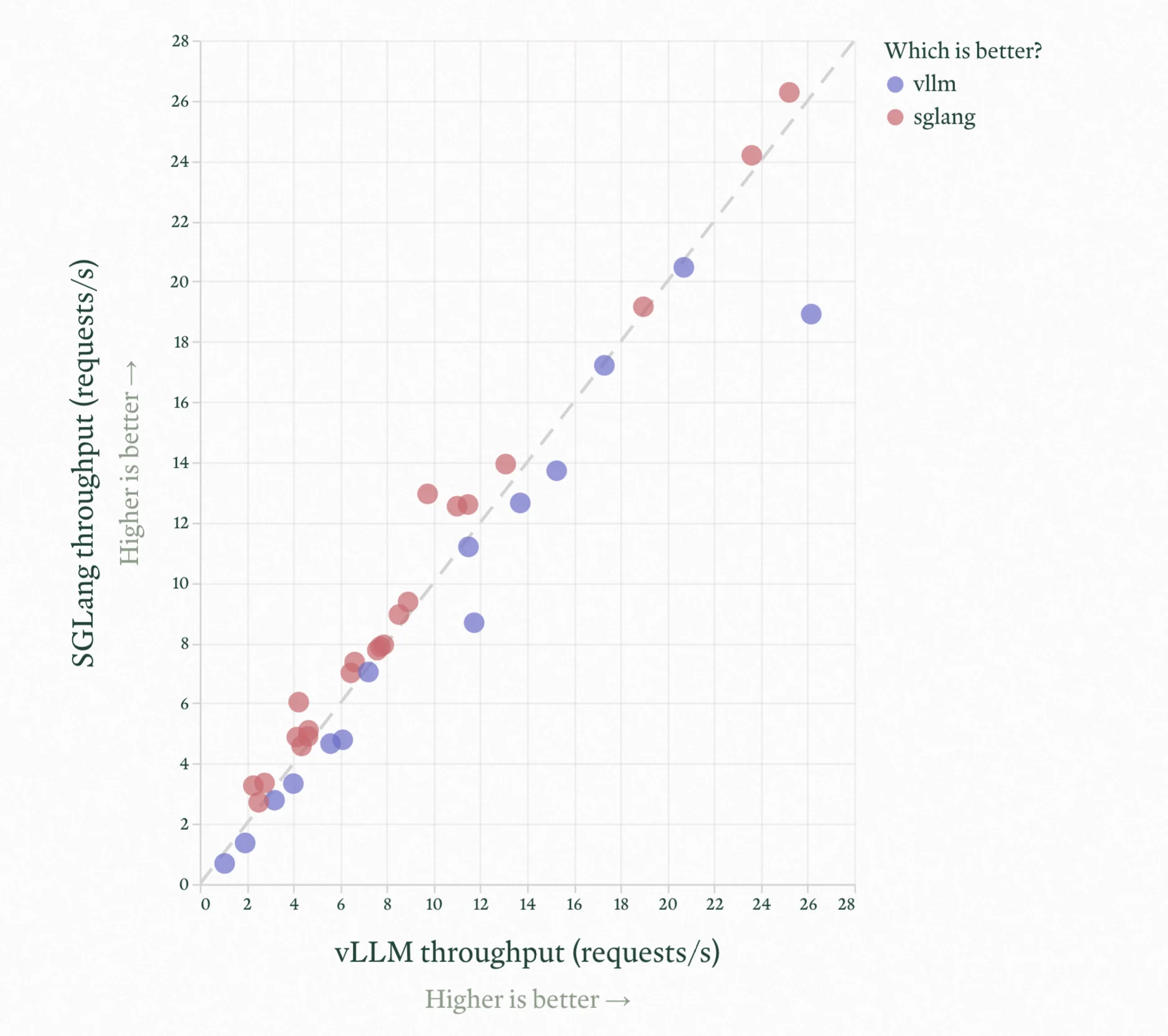
In case you missed it: AI is actually open now, thanks to the teams releasing open models (LLaMA, ERNIE, DeepSeek) and engines (vLLM, SGLang).
But that just means more questions: which engine should you use? How much will it cost to self-host your RAG chatbot? We ran over a thousand LLM engine performance benchmarks and built an interactive tool to help you answer these questions. Check it out here!
🖼️ FLUX.1 Kontext [dev] on Modal

Black Forest Labs released weights for FLUX Kontext [dev]. It’s the new state-of-the-art open-weight image generation model, with super precise contextual editing abilities across success renderings. Our example shows you how to run it on B200s.
🏎️ Run FLUX.1-dev 3x faster
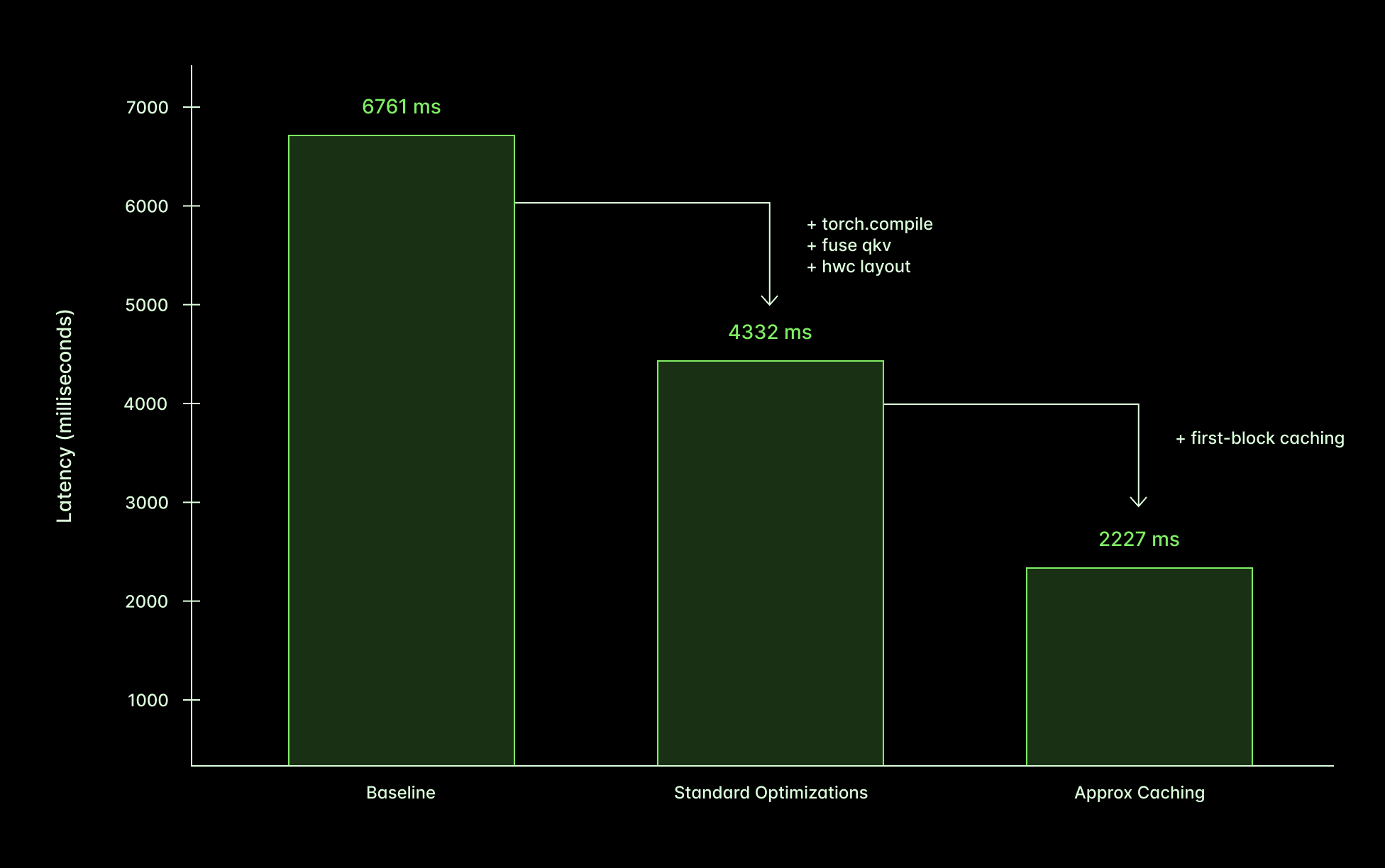
Speaking of FLUX: check out our blog post on how to make Flux [dev] run 3x faster with multiple optimizations. That means you have the flexibility of self-deployments while still getting the speed and price of API platforms! Read more here.
❓Learn how Quora uses Modal Sandboxes at scale
Quora uses Modal to power sandboxed code execution for Poe, their chatbot platform. Quora can create up to 1,000 Sandboxes per second with Modal, plus we’ve saved the team >15% engineering time compared to building their own sandbox solution! Read more here.