Train more, configure less
“Modal lets us deploy new ML models in hours rather than weeks. We use it across spam detection, recommendations, audio transcription, and video pipelines, and it’s helped us move faster with far less complexity.”
“Modal's user-friendly interface and efficient tools have truly empowered our team to navigate data-intensive tasks with ease, enabling us to achieve our project goals more efficiently.”
Where researchers can run
experiments, not ops
Define in code
Define your training function with Modal’s SDK. Easily keep ML dependencies and GPU requirements in sync with application code.
Native storage
Ingest training data from anywhere: Modal’s distributed Volumes, cloud buckets, or your local filesystem.
Sub-second startup
Modal’s container stack launches GPUs for your function in < 1s. Fan out experiments to accelerate your research.
Speed up training jobs by going multi-node
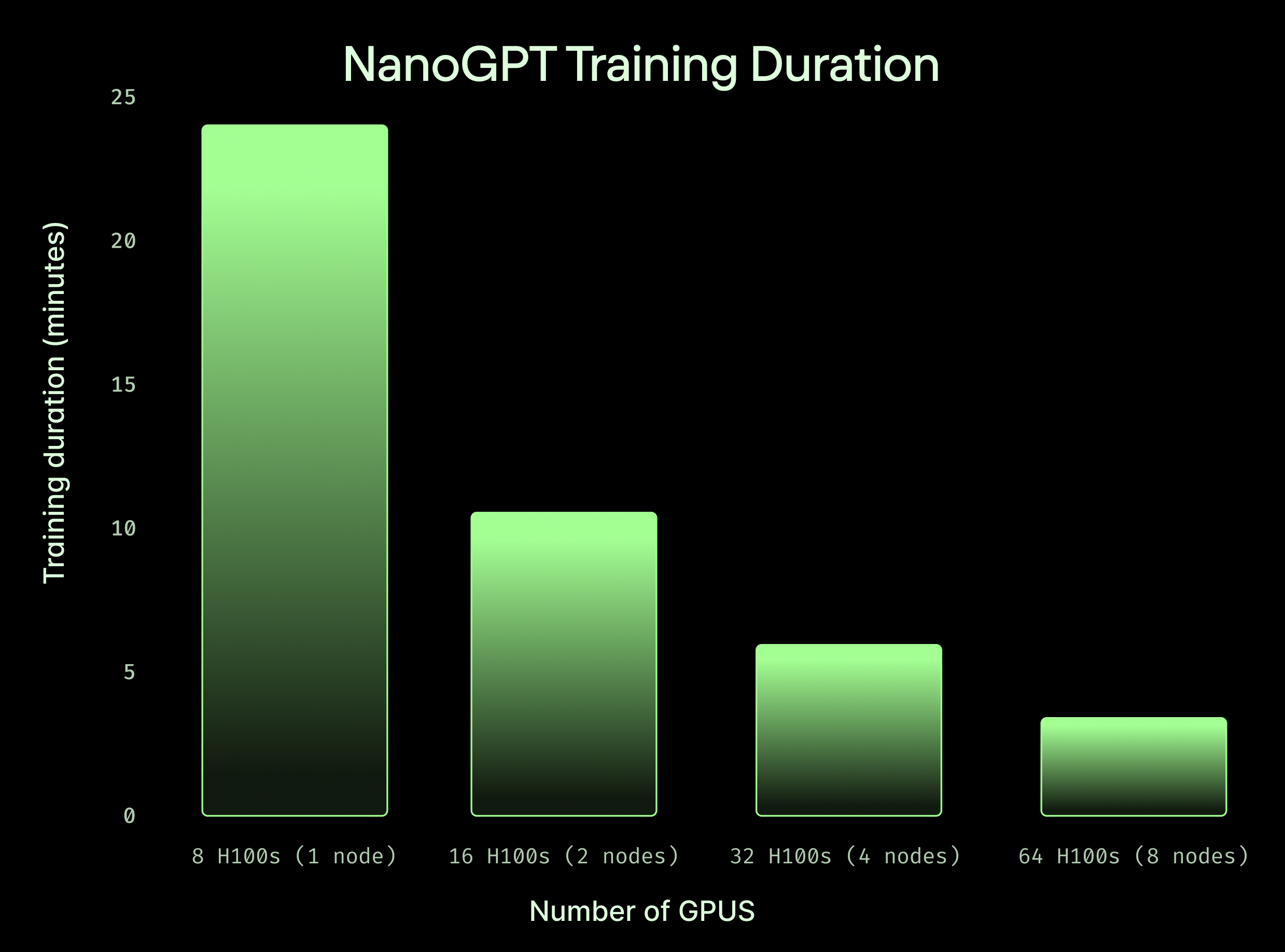
Scale from 1 GPU to 64 with just one line of code
Spin up a cluster in a second with no minimum commitments
B200, H200, and H100 clusters equipped with Infiniband and private networking
No black boxes. You control the training logic.
Any base model
Use Qwen, Flux, Whisper, your own custom model, or train from scratch.
Any training framework
PyTorch, Axolotl, Unsloth, Hugging Face TRL, and more.
Any MLOps framework
Weights and Biases, TensorBoard, and more.