One-second voice-to-voice latency with Modal, Pipecat, and open models
In this post, we’ll walk you through how we built a voice AI chatbot that responds fast enough to carry on a natural conversation. And we only relied on Modal, open weights models, and the open source framework Pipecat.
Even if you’re not interested in voice AI per se but you still want to build real-time applications on Modal, many of the strategies we cover will still apply! To see the code and deploy your own low-latency voice AI application, check out the GitHub repo.
Conversational Voice AI Applications
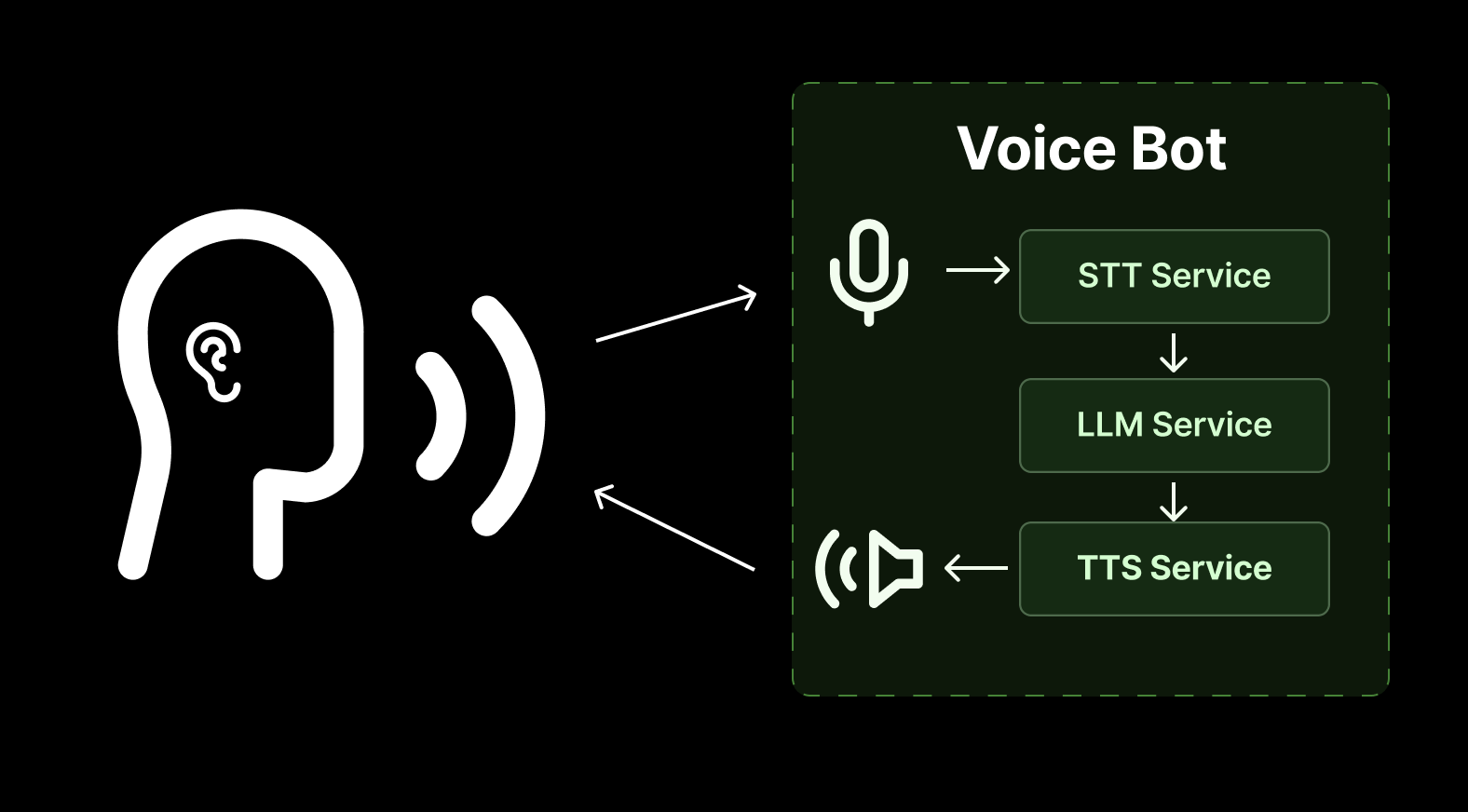
A conversational bot has to do more or less the same things that a conversational human needs to do - listen to the other participant, formulate a response, and say the response aloud, all while managing the complexities of conversation (more on that below). In terms of application architecture, this is often represented as a sequence of three inference steps, each of which leverages an AI model.
- Speech-to-text (STT): Transcribe speech from audio data.
- LLM: Feed the transcript into an LLM to generate a response.
- Text-to-speech (TTS): Generate speech from that response as audio data.
Voice AI Frameworks
In practice, these independent services do not pass data directly between each other but are coordinated by a conversational AI framework. This approach has several advantages.
- Service Modularity: Those building voice AI applications will find a rich ecosystem of proprietary and open models for each of the three steps listed above. Using a conversational framework makes it easy to swap out different models and APIs.
- High-level Conversational Flow: Generating natural conversation entails more than just one response. Multi-turn conversation, with a human who may interrupt your bot, requires voice-activity detection (VAD) and turn-taking inference, i.e. did the other participant stop speaking or did they just pause? Quality frameworks provide hooks for these types of models and their output events.
- Statefulness: Most LLM APIs are RESTful and therefore stateless. And the same goes for most STT and TTS services. Conversational frameworks, often a coordinated set of concurrent loops, provide the long-running, stateful process which can store conversation history and other relevant information.
- Networking: Conversational frameworks abstract away cumbersome boilerplate for managing WebRTC or WebSocket connections between clients and bots or between bots and services.
- Frontend: Most frameworks provide some browser-based frontend for clients. Some offer simple and static interfaces intended mostly for testing while others provide a rich set of components tailored for the voice use case.
Pipecat
We’re going to use the open source voice AI framework Pipecat built by the folks at Daily, and maintained with the support of the developer community. Pipecat applications are built around a pipeline which coordinates a series of processors that handle real-time audio, text, and video frames with ultra-low latency. Some processors handle requests to external AI services and others process local data like audio filters or text parsers. Each pipeline starts and ends with a transport node that manages the real-time media connection with the client.
Let’s look at a few features that make Pipecat particularly useful. If you want to learn more, you can check out their excellent documentation.
SmallWebRTCTransport
SmallWebRTCTransport is a free, open source peer-to-peer (P2P) WebRTC transport built on aiortc that provides end to end encryption and low latencies. A great option for one-on-one conversations with a bot.
If you want to build an app with multi-user rooms, support a large number of globally distributed clients, or otherwise need an ultra-performant transport layer, it’s just a few lines of code to swap from SmallWebRTC to a proprietary network. Daily, with the support of the community, maintains Pipecat as vendor neutral, so you while you can use Daily’s global mesh network, Pipecat also supports several other transport options. For example, you can integrate Pipecat directly with Twilio.
Custom Services
Using a remote service with Pipecat requires an AIService implementation, and many of the most popular voice AI and LLM providers already have integrations.
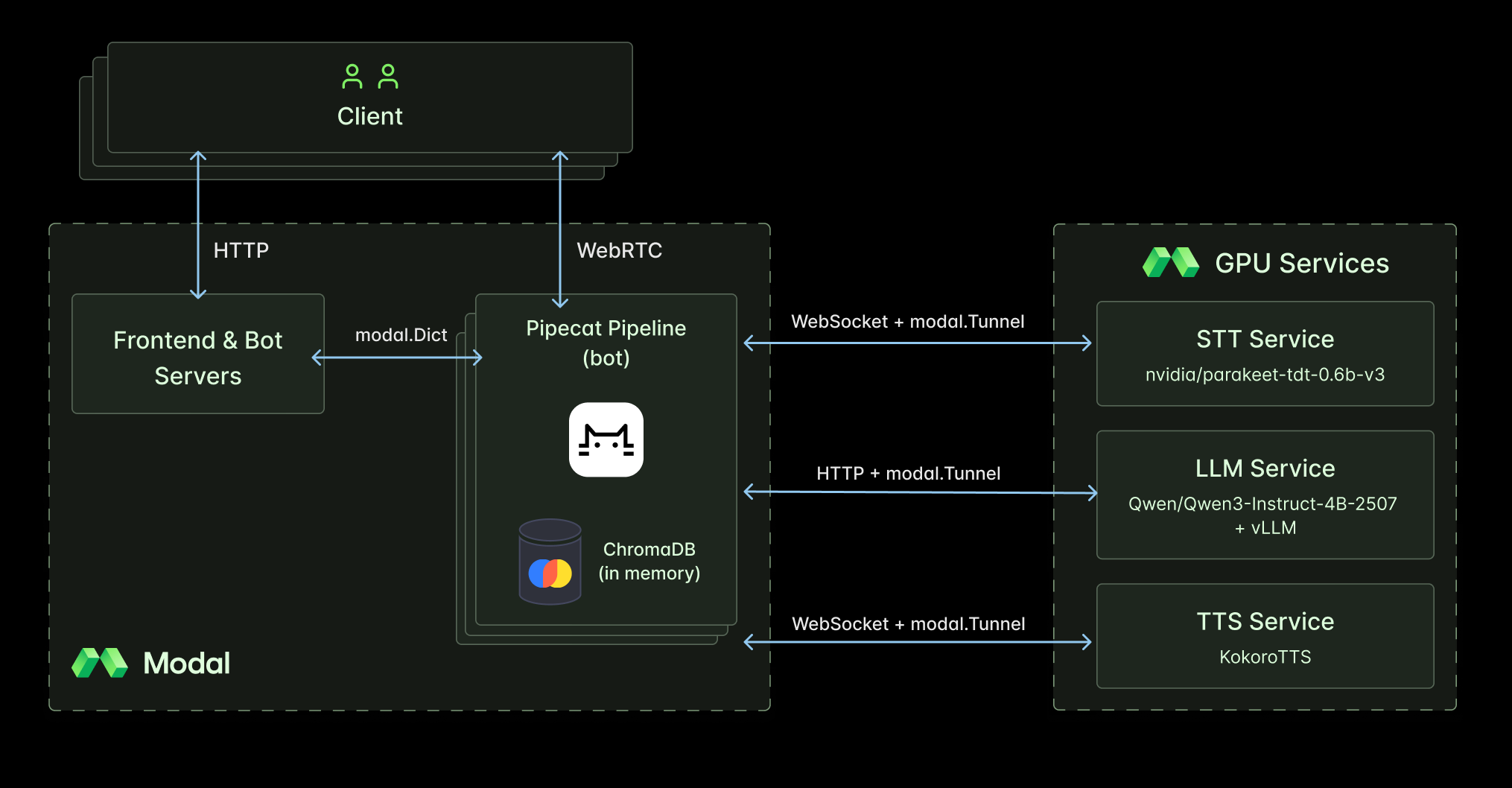
Because it’s open source, we can easily incorporate our custom Modal services. We wrote a base service class that makes it easy to connect to an STT or TTS service deployed on Modal using WebSockets.
Optimized VAD and Turn Detection
Pipecat provides a simple integration with Silero, probably the most common choice for VAD in the voice AI landscape, as well as their own turn-taking model called SmartTurn.
When used in tandem, Silero VAD and SmartTurn emit frames indicating when users have started and stopped their conversational turn with high accuracy and very low latency. These speaking frame events drive Pipecat’s optimized interruption logic which produces a natural feeling conversation where bots yield to user interruptions but don’t respond prematurely during a user’s brief mid-sentence pauses.
Voice-UI-Kit
Pipecat also provides a rich suite of React components that developers can use to build custom frontends for their applications. (Thanks to Jon and the team at Pipecat for their help with the code block and link components for this demo!)
Why Modal and Pipecat work so well together for Voice AI
Modal gives you an ergonomic SDK to run Python code on GPUs or CPUs in the cloud. Behind the scenes, Modal’s custom container stack and global GPU fleet guarantee your app can respond quickly to demand.
A key Modal feature we leverage in this demo is the ability to independently autoscale functions that have different hardware and container requirements. With Pipecat as a stateful orchestrator we can move our heavy computations into their own GPU services that autoscale independently from the bot container and can be shared by all active bots.
Even with Silero VAD and SmartTurn enabled, Pipecat bots only require CPUs to run efficiently. This means you can save money by using a CPU-only container for the long-running, stateful bot process and make requests to GPU services which can autoscale as needed!
Voice-to-Voice Latency
The figure-of-merit for conversational voice AI is response latency, specifically the duration from when the user stops speaking to when they first hear the bot’s response - aka voice-to-voice latency. During natural conversation, voice-to-voice latencies can be as short as 100 milliseconds - and this doesn’t include the case where one participant might interrupt the other!
But not all responses have to be that fast. When someone is asked a serious or technical question, they may pause before answering. And, anecdotally, some users find it jarring if an AI voice bot responds too quickly.
In general, conversational voice AI applications target response latencies around one second or less which is not easy to achieve - especially when your computations are distributed across different machines. In the following sections we’ll share strategies for developing low-latency applications on Modal that allowed us to hit that target.
Building a Conversational Voice AI for Modal’s Docs
We’re going to build a voice assistant that can answer questions about developing Python applications with Modal. We’ll add a RAG step to our pipeline that queries Modal’s documentation and appends the results to the user’s transcription.
For a richer and more useful experience, we’ll request a structured output from the LLM with three elements: a spoken response, short blocks of example code, and relevant links to the source documentation. The spoken response will be sent to our TTS service, while the code blocks and links will be delivered directly to our client for rendering in the browser.
Our final pipeline contains the following high-level steps:
- receive audio data over WebRTC from the client
- transcribe client audio
- query Modal’s documentation with transcript
- assemble query results and conversation history into a prompt
- generate a structured response from the LLM and parse
- generate audio data from spoken response
- send audio and other response data back to client over WebRTC
Open Weights Models and RAG Libraries
The performance of open weights models for STT, LLM, and TTS inference continue to improve month over month, and choosing the right models may look different for different applications. But in general, we want models that are fast and, ideally, streaming.
For our application, we landed on the following models which we deploy as independent Modal services - meaning they don’t contain any application-specific knowledge regarding our bot.
STT: Parakeet-tdt-v3
Most low-latency STT services operate on streaming audio input and can return both partial and final transcription results. However, we found that in practice using Pipecat’s local VAD and turn detection to segment audio and passing that to NVIDIA’s parakeet-tdt-0.6b-v3 was faster than the open weights streaming implementations we tried or implementing our own VAD alongside the model.
While this doesn’t provide the real-time feel of partial transcripts, when it comes down to total voice-to-voice latency, the only thing that matters is the final transcript time. And in terms of final transcript time and accuracy, it’s hard to beat Parakeet - as we’ve shown previously in our batch transcription post.
LLM: Qwen3-4B-Instruct-2507 + vLLM
Our critera for choosing an open weights LLM is that it should be as small and therefore as fast as possible while producing quality answers. Newer instruction-following models were also preferred so that they have a baseline knowledge of Modal’s SDK. For our use case, the 4B parameter version of Qwen3-Instruct’s latest updates (the “2507” family of models) performed very well.
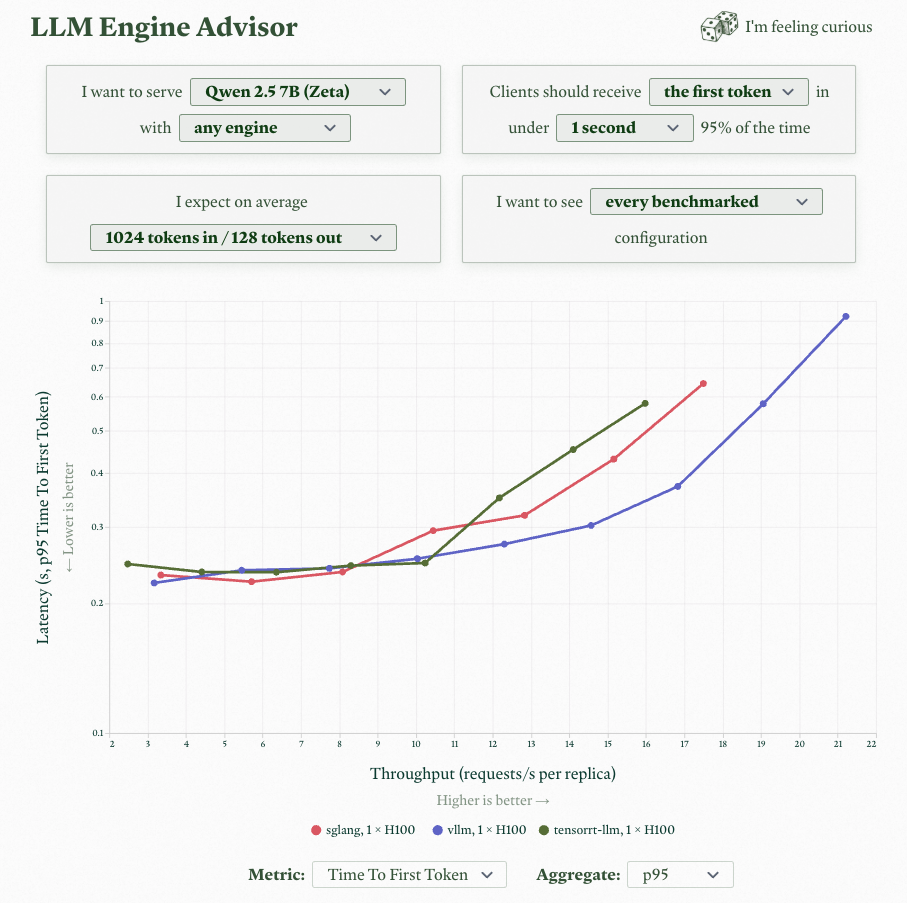
To optimize LLM inference serving for low-latency responses, we use vLLM as our inference engine. We referenced the LLM Engineer’s Almanac to help guide this choice by querying which inference engine consistently produced the lowest time-to-first-token (TTFT) across a range of input and output token sizes. We fine-tuned the engine and CUDA graph compilation configuration to reduce TTFT (in some cases at the expense of cold-start time).
TTS: KokoroTTS
For TTS, we opted to use Kokoro, a relatively small 82M parameter model. Kokoro is not only fast but also produces streaming output which minimizes the time-to-first-byte (TTFB) at the client.
It also accepts phonetic symbols as input so we can be sure domain specific words like “Modal” are always pronounced correctly.
RAG and Embeddings: ChromaDB and all-minilm-l6-v2
ChromaDB is a fast and free Python library for RAG retrieval - a non-trivial task from a runtime performance perspective. When combined with all-minilm-l6-v2 running with OpenVINO, the total retrieval time to embed the query and perform search is just a few tens of milliseconds.
Minimizing Network Latency
A major source of latency in a voice AI application is the time it takes to pass data over the Internet. The duration of each network request is dependent on several things including the protocol, the transport layer, and the physical distance between the client’s device, our bot container, and each of the inference servers.
Client ↔ Bot: WebRTC
Pipecat provides both a JavaScript client API and a Python API (the SmallWebRTC layer mentioned previously) that work together to establish and manage a WebRTC connection between the client’s browser and our bot behind the scenes.
Modal Tunnels & Web Servers: Bot ↔ Inference Services
In general, requests to Modal applications first go through Modal’s input plane to facilitate autoscaling and other powerful features. The tradeoff is that the extra layer leads to additional latency.
To bypass the input plane and communicate directly with services, we can use Modal Tunnels. A simple and powerful pattern is to serve a fastapi app using uvicorn and use the Tunnel to relay requests from a public URL to the uvicorn port.
We’ll serve a WebSocket endpoint over a Tunnel for our STT and TTS deployments to establish low-latency, bidirectional, and persistent lines of communication between our Pipecat bot and these voice AI services. What’s especially nice about this approach is that the bot-side code is the same whether we serve the WebSocket endpoint over a Tunnel or using the standard modal.asgi_app.
We can serve vLLM in a similar manner using a Tunnel to forward HTTP requests to the vLLM server.
Recovering Autoscaling and Function Calls
Bypassing the Modal input plane comes at the cost of autoscaling because Modal is no longer proxying the client requests.
To get around this, we’ll create something like a session where we spawn a FunctionCall at the beginning of our conversation and cancel it at the end - effectively linking the lifecycle of the function call to the lifecycle of the conversation. We use a Modal Dict to share URL and lifecycle information between the client and service containers.
Admittedly, this solution isn’t perfect. But stay tuned because Modal’s engineers are cooking up something that delivers the best of both worlds, low-latency networking and Modal’s instant autoscaling.
Pinning Bot and AI Service Regions
Even after leveraging WebRTC and Modal Tunnels, we’re still constrained by the speed of light. The only way to battle this constraint is to move the host machines closer together geographically by pinning our Modal services to a region.
Choosing a single, specific region (i.e. one data center) can limit the available GPU pool and increase wait times. To balance GPU availability with geographic proximity, it’s helpful to permit a small set of data centers clustered in a small area like Virginia in us-east or the San Francisco Bay Area in us-west. You can also permit several GPU types to expand the available pool.
Testing Performance
Measuring Voice-to-Voice Latency
The most straight-forward way to measure voice-to-voice latency is to record the conversation in the same space as the client. This will account for the full end-to-end latency, including hardware.
For these tests, the client was in the Bay Area and we set the bot and inference service regions to one of three options:
- a set of data centers in the Bay Area:
us-west-1, us-sanjose-1, westus - a set of data centers in Virginia:
us-east-1, us-ashburn-1, us-east4 - the default (
None) which indicates no preference - the container could be anywhere in Modal’s global fleet.
We also tested a configuration without Modal Tunnels, i.e. using a standard Modal Web Function. In this case, we set the bot and services in us-east, close to the input plane.
Pyannote For Speaker Diarization
Once we have the recording of a conversation we still have to identify the beginning and end of each speaker’s turns in the waveform. Doing this by hand is cumbersome and suffers from bias and irreducibility issues.
To automate the process, we turned to Pyannote. We used their proprietary Precision-2 model - which they deploy on Modal behind the scenes - to diarize conversation recordings. While not an open model, the results were worth it. And for this use case the free tier sufficed.
From the diarization output, we can easily compute and aggregate voice-to-voice latency estimates.
Analyzing and Plotting the Results with a Modal Notebook
We processed the audio recordings using Pyannote’s REST API, summarized the results, and generated plots in a Modal Notebook. You can fork the notebook and try it yourself.
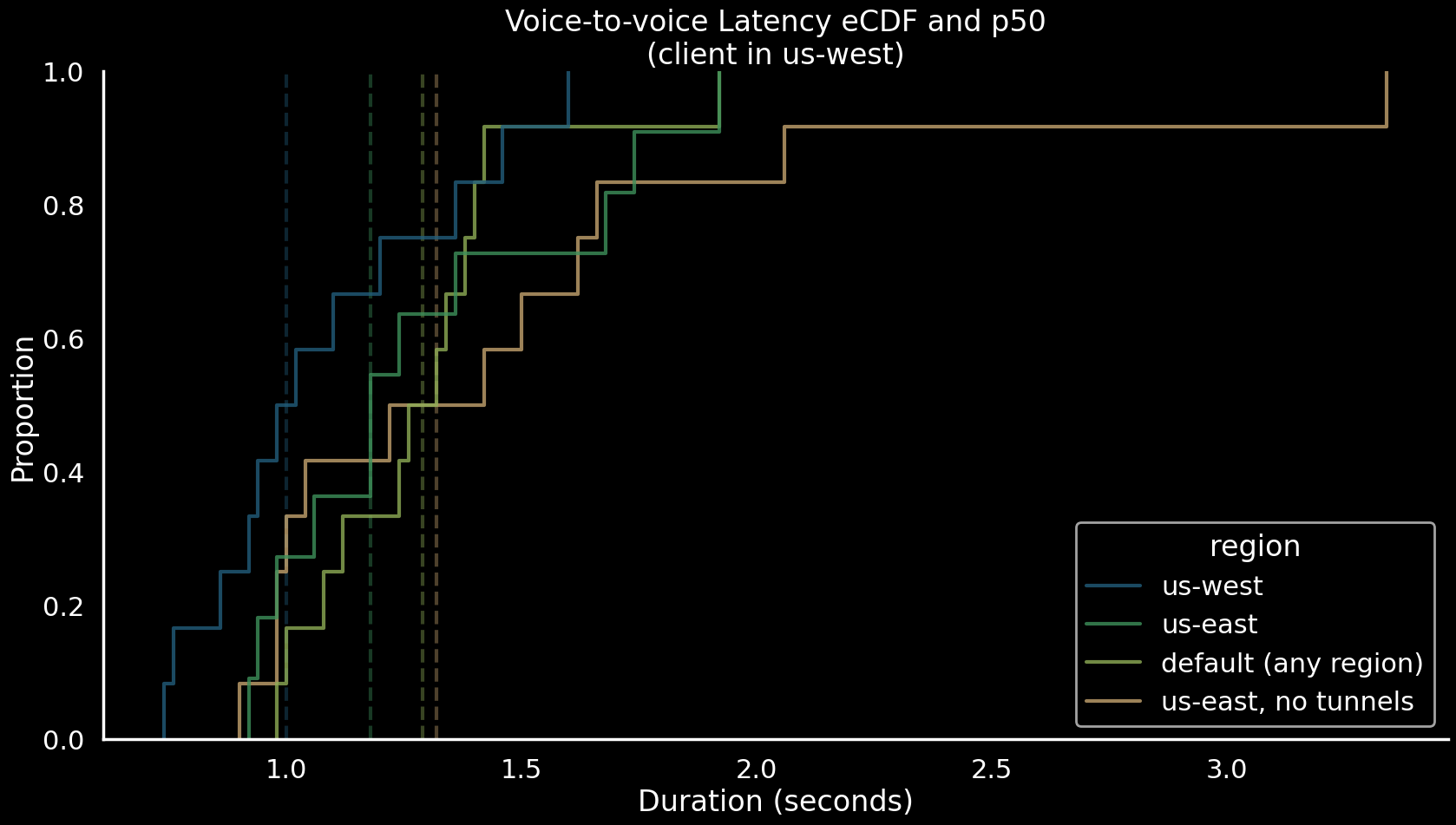
Our tests demonstrate that
- when the client and the Modal containers are near each other, our app can hit a median voice-to-voice latency of one second which is on par with many proprietary voice services.
- regardless of the client to bot distance - which is covered by a WebRTC connection - ensuring that the bot and the Modal services reside in proximal data centers is important for latency reduction.
- if you don’t use Modal Tunnels, it’s best to deploy your bot and services in regions near the input plane in
us-east.
Deploy Your Own Conversational Voice AI on Modal
The code is available in the GitHub repo. Let us know if you have any questions in our Community Slack!
Bonus: Animating Modal’s Mascots Moe and Dal
For fun, we also added an animated avatar using Modal’s mascots Moe and Dal. Since they are a duo, they’ll each need their own voice which gives us a chance to demonstrate Pipecat’s parallel pipeline capability and concurrent WebSocket connections to our TTS service - each with its own voice setting.
Pass enable_moe_and_dal = True to the run_bot call to enable the animation and dual voice pipeline.