Building an RL theorem-proving workflow on Modal
This post was written in by AE Studio, a Modal consulting partner. Join the teams helping ship AI faster with Modal at modal.com/partners.
Motivation: Teaching AI to Prove Math Theorems
At AE Studio, we do extensive pretraining and fine-tuning of language models, and parallel on-demand compute is the only way to efficiently run our workloads. By leveraging Modal, we can spin up thousands of GPUs in parallel and do research that would otherwise take weeks or months in just days. Here, we walk through our work on training LLMs to prove math theorems using reinforcement learning.
There's more than one way to train a model with reinforcement learning. The most common approach today is called Group Relative Policy Optimization (GRPO). In simple terms: the model generates a batch of proof attempts, the system ranks them against each other, and the model's internal weights get nudged toward the correct proof generations.
We wanted to test an alternative called Evolution Strategies (ES). Instead of adjusting the model through traditional backpropagation, ES takes a different approach inspired by natural selection: it creates a "population" of slightly different versions of the model, tests all of them, and then steers the original model toward the versions that scored best.
Recent research has shown ES can outperform GRPO in some settings. We wanted to see if this could be replicated for theorem-proving as a first step to accelerating AI-enabled science.
Setup
For a language model to prove a theorem, it needs to generate 'code' in a specialized language. A popular language for this is Lean. Once the code is generated, the Lean compiler can verify if the proof is correct. Code generation is done by the LLM and is GPU/inference heavy. The verification is done by the Lean compiler and runs on the CPU.
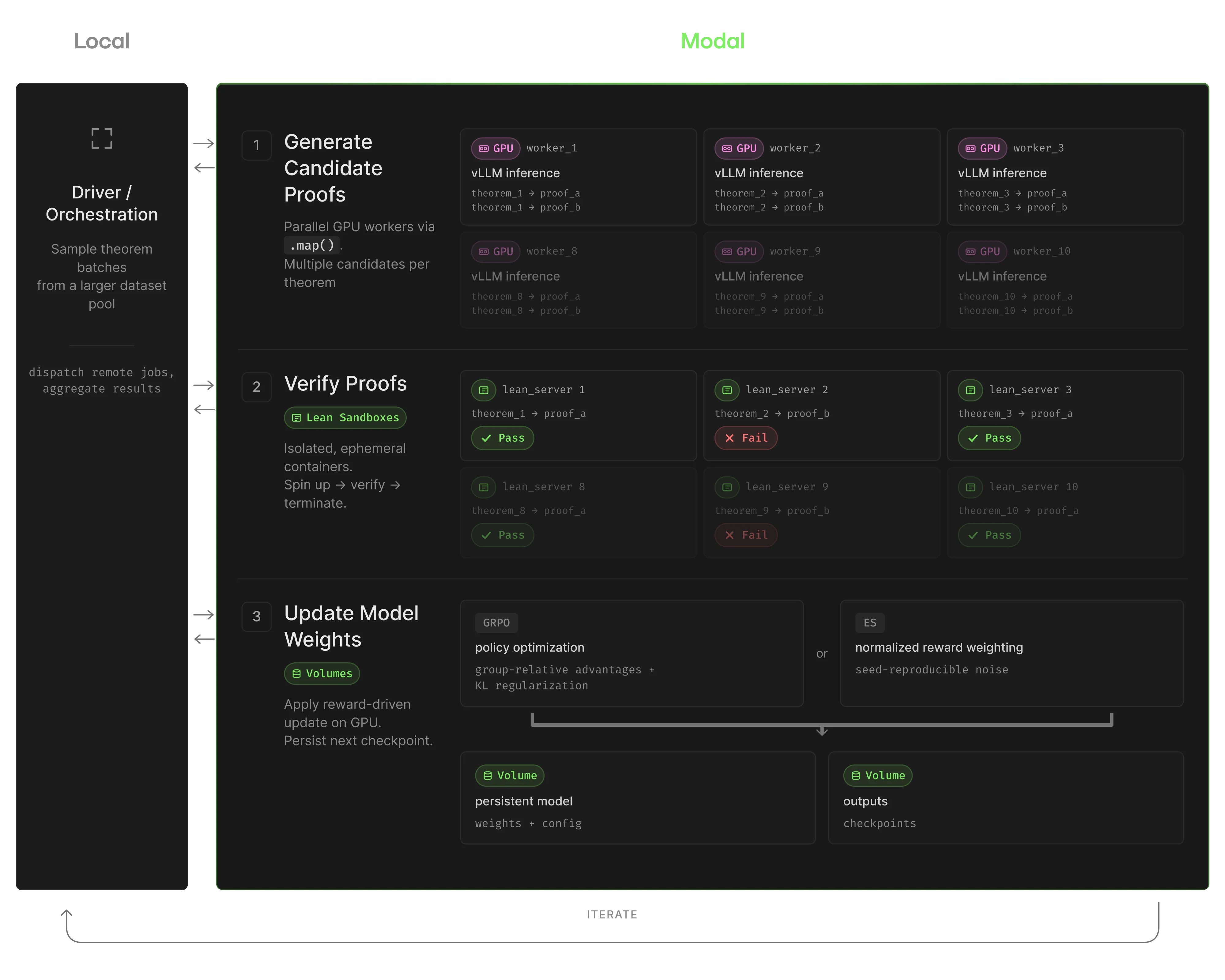
To run this workload, we therefore needed three different execution environments working together:
- Generating proofs: a vLLM instance running on GPUs is used to run inference for generating proof attempts.
- Checking proofs: each proof gets sent to a Lean verifier running on CPUs. This needs to be isolated because a bad proof can hang or crash the verifier, and we don't want one failure to take down the whole run.
- Coordinating everything: a lightweight process supervises the training loop, sending batches of theorems to the generators and verifiers, collecting results, and tracking progress.
Setting this up from scratch would mean managing multiple server environments, a job scheduling system, storage for model checkpoints, and a verification service robust enough to handle crashes gracefully. Instead of building all that ourselves, we ran the whole thing on Modal. This meant we could spend our time on the actual experiment instead of building infrastructure.
In practice, that translated into the following setup on Modal:
| Workload Requirement | Modal Feature |
|---|---|
| Separate runtimes for GPU generation, Lean verification, and orchestration | Per-function images let each step declare its own environment |
| Many independent evaluations per ES iteration | .map() fanned out remote jobs and streamed results back as they finished |
| Lean verification must be isolated from bad proofs and long-running requests | Sandboxes gave each verification batch its own short-lived Lean server |
| Base model must be available to all remote workers | Volumes stored the original base weights so every GPU worker could load them without downloading from Hugging Face each time |
| Gated model access from Hugging Face | Secrets injected credentials into remote functions without leaking them into local shell state |
The main friction we anticipated with this setup was that GPU sandboxes take time to warm up, and remote debugging is never as direct as working in a single local process. This is an inherent challenge when running bursty experiments across multiple GPUs. Fortunately, Modal helps smooth over much of that complexity with features that reduce cold starts and make remote iteration easier, which makes the workflow far more manageable for this kind of research.
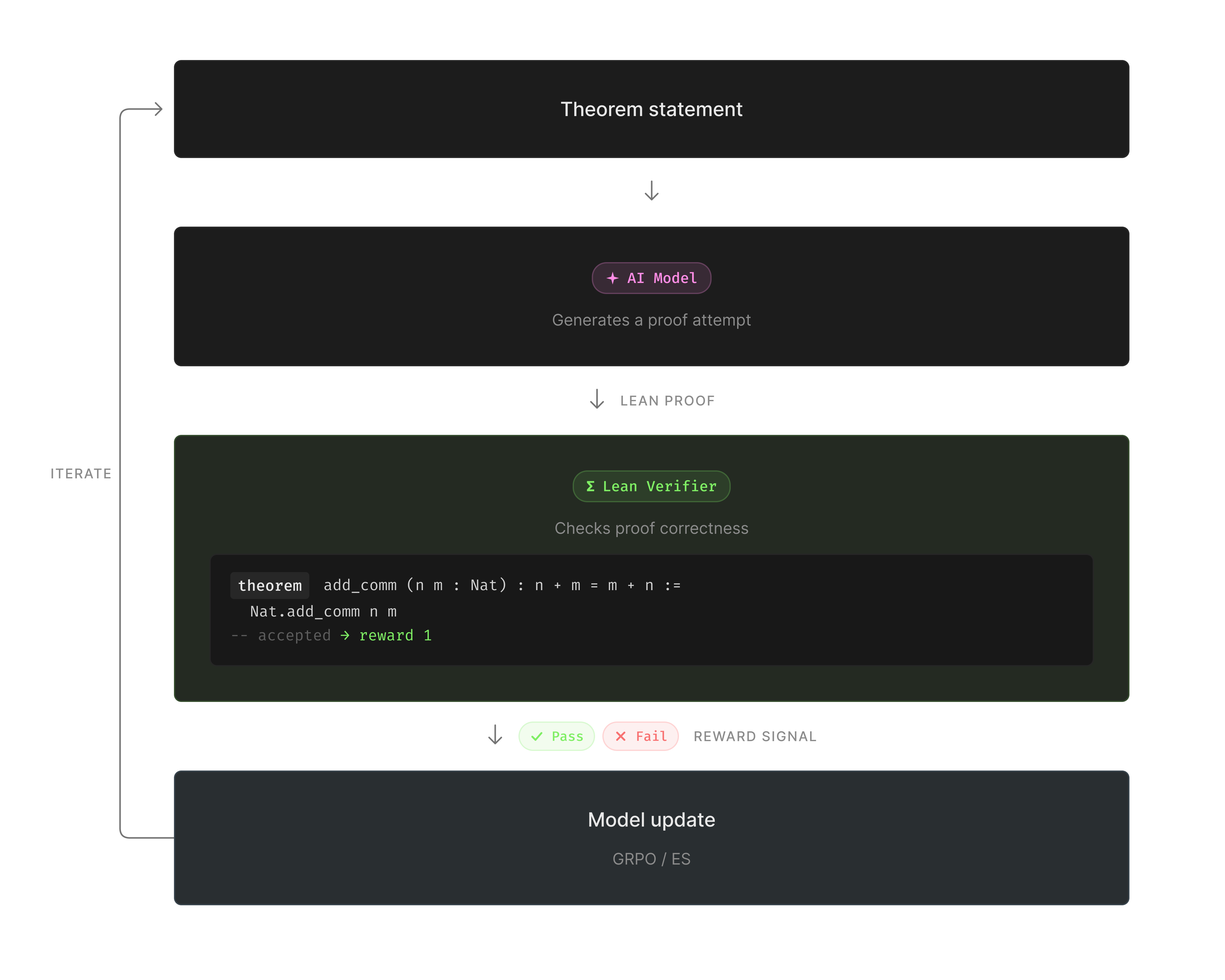
The Training Process
Our goal was to train a model to be good at math theorem proving. Here we used Lean, a formal theorem verification language which provides a verifiable reward for the training loop; instead of asking whether a model output looks plausible, we ask whether Lean accepts it as a valid proof.
A toy example is proving that if a = b and b = c, then a = c. The model writes a proof in Lean. The Lean verifier generates a reward signal depending on if the proof is correct or not.
We kept the training loop fixed, and only changed the update rule to compare the performance of GRPO and ES:
- GRPO generates groups of proof attempts and applies a gradient update based on relative performance within the group.
- ES evaluates a population of perturbed models, scores each perturbation by proof success rate, and updates the base model using a weighted combination of the population's perturbations based on their rewards.
How We Built It on Modal
Separate Images for Separate Jobs
We gave each compute role its own image instead of trying to force everything into one oversized environment:
gpu_image = (
modal.Image.debian_slim(python_version="3.11")
.pip_install("vllm>=0.6.0", "torch", "transformers", "datasets", ...)
)
orchestrator_image = modal.Image.debian_slim(python_version="3.11").pip_install(
"requests", "tqdm", "numpy"
)
lean_server_image = modal.Image.from_registry("projectnumina/kimina-lean-server:2.0.0")The GPU workers could stay focused on inference, the Lean sandbox on verification, and the orchestrator stayed lightweight. It also meant each environment could be cached and reused independently.
Parallel GPU Fan-Out with .map()
ES was the easiest part of the workload to distribute. Each perturbation evaluation needed the current checkpoint, the theorem batch, one perturbation seed, and generation parameters. We used .map() because the fan-out matched the structure of the algorithm:
for candidates in generate_with_perturbation.map(
[base_model_path] * population_size,
[seed_reward_history] * population_size,
[iteration_theorems] * population_size,
perturbation_seeds,
[sigma] * population_size,
[temperature] * population_size,
[max_tokens] * population_size,
):
candidate_proofs.extend(candidates)With ES, weight perturbations are fully determined by their seeds. The update step only needs seeds and rewards to aggregate all individuals of the population, avoiding expensive weight transfers between GPUs. Each worker receives the full seed/reward history and reconstructs the current model from the base weights before applying its own perturbation.
Sandboxed Lean Verification
Verification was the part of the system where isolation mattered most. Proof attempts can hang, crash the checker, or consume far more resources than expected. We did not want one bad batch to affect the rest of the run.
For each verification batch, we created a sandbox, started the Lean server inside it, sent proofs over HTTP, collected results, and shut the sandbox down:
sb = modal.Sandbox.create(
image=lean_server_image,
cpu=4,
memory=16384,
timeout=3600,
encrypted_ports=[8000],
)
proc = sb.exec(
"bash", "-c",
"cd /root/kimina-lean-server && nohup python -m server > /tmp/server.log 2>&1 &",
)
tunnel = sb.tunnels()[8000]
server_url = tunnel.urlWe verified proofs in parallel with the same basic fan-out pattern:
for batch_results in verify_batch_in_sandbox.map(
verification_batches,
list(range(len(verification_batches))),
kwargs={"timeout_per_proof": 120},
):
verification_results.extend(batch_results)One iteration created 3,840 proof attempts, which we split into batches of 64. Modal’s sandbox model makes it possible to scale this much further. If we wanted the verification step to complete faster, we could run each proof attempt in its own sandbox and execute thousands of them in parallel.
Stateless Checkpointing with Seed Histories
A nice property of ES is that the entire model state can be described by the base model plus a list of (seed, reward) pairs. Each perturbation is generated from a deterministic random seed, so you never need to store the actual noise vectors. The orchestrator maintained a running list of seed/reward entries and passed it to each worker.
seed_reward_history: List[Dict] = []
for iteration in range(num_iterations):
result = run_es_iteration.remote(
base_model_path=model_name,
seed_reward_history=seed_reward_history,
...
)
seed_reward_history.append(result["history_entry"])Each history entry was just the seeds, their normalized rewards, and the hyperparameters needed to recompute the update. About 200 bytes per iteration:
history_entry = {
"seeds": perturbation_seeds,
"normalized_rewards": normalized_rewards,
"alpha": alpha,
"sigma": sigma,
"population_size": population_size,
}On the GPU side, each worker loaded the original base model from a Volume, then replayed the full history to reconstruct the current weights before applying its own perturbation:
def replay_es_history(self, history: list):
for entry in history:
alpha = entry["alpha"]
pop_size = entry["population_size"]
for seed, norm_reward in zip(entry["seeds"], entry["normalized_rewards"]):
coeff = (alpha / pop_size) * norm_reward
for _, p in self.model_runner.model.named_parameters():
gen = torch.Generator(device=p.device)
gen.manual_seed(int(seed))
noise = torch.randn(p.shape, dtype=p.dtype, device=p.device, generator=gen)
p.data.add_(coeff * noise)
del noise
if seed_reward_history:
llm.collective_rpc(replay_es_history, args=(seed_reward_history,))The replay walks through every past iteration's seeds and rewards, regenerates the same noise on GPU using the deterministic seed, and applies the weighted update in place. The base model lives in a Volume so that workers can load it without re-downloading from Hugging Face each time:
model_cache = modal.Volume.from_name("rl-theorem-model-cache", create_if_missing=True)The Volume is read-only from the training loop's perspective. The full model state traveled as a plain Python list, small enough to pass as a function argument to every remote call.
Key Performance Metrics
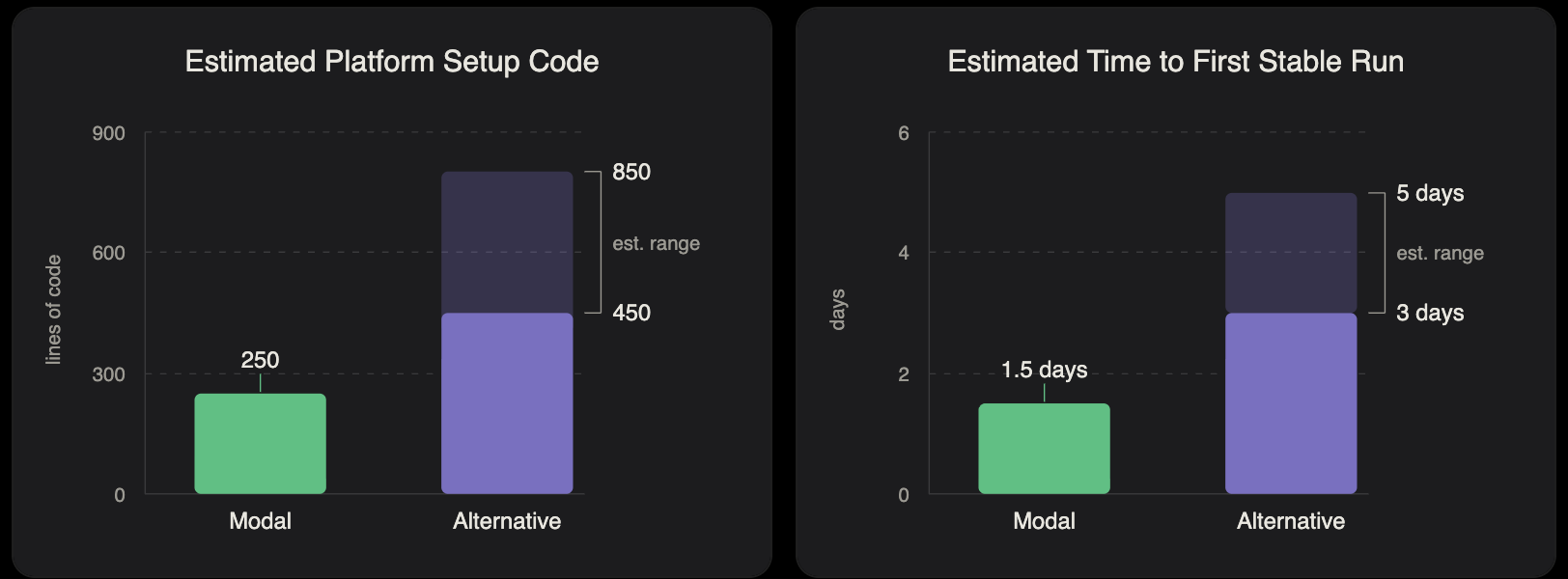
For this experiment, Modal provided the ideal balance of speed, simplicity, and cost. Our Modal implementation required roughly 250 lines of platform setup code, less than half of the ~600 lines we typically see on other platforms for similar experiments. This reduced complexity translated to completing a successful training run in less than two days from kicking off the project, 60% less than we see when using alternative platforms. It also means faster iteration speed as we continue to tweak and optimize the training pipeline.
Runtime efficiency also improved significantly. While the generation step (requiring GPUs) averaged 147 seconds per iteration, the full loop took 538 seconds due to the verification stage (which requires CPU-only). Modal’s elasticity meant we only paid for GPUs when they were actively being used, reducing wasted GPU time by approximately 3.7x compared to less elastic platforms.
Based on these timings, we estimate the full run cost at $122 on Modal. Equivalent runs on less elastic alternatives using the same hardware would have cost $180 to $480. Even without significant optimization, this out-of-the-box setup proved to be the fastest and most cost-effective path to results.
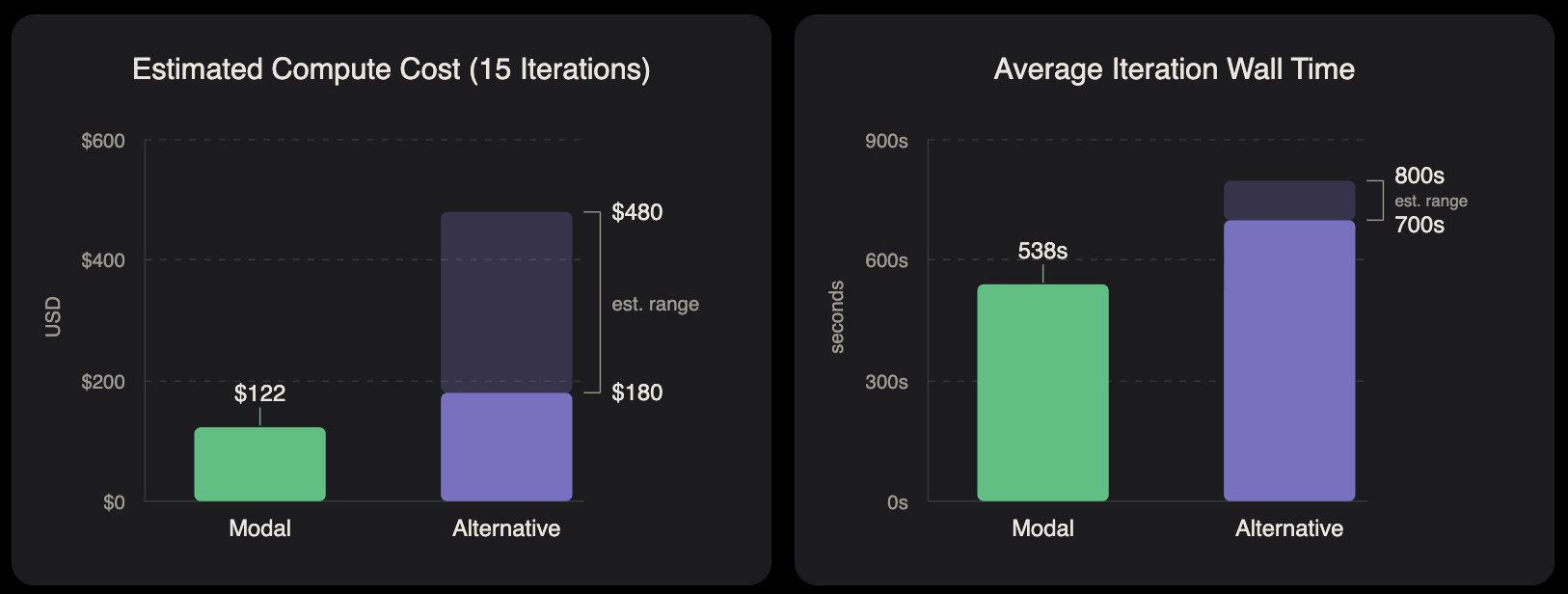
Note: These numbers are estimates based on our codebase, public pricing, and data collected from our measured ES timings.
Results & What’s Next
Our early results were encouraging. In several theorem-proving runs, ES matched or outperformed the GRPO baseline in verified proofs per iteration, and it often appeared especially sample efficient when training data was limited. In other settings the gains were smaller, and we have not yet isolated how much of the variation comes from factors like hyperparameter choices, dataset nuances, or population size. The scaling behavior of ES in this regime is still not well understood, so more experimentation is needed to see where it consistently shines and whether it can compete with or surpass GRPO in larger-scale training setups.
So the research question is still open, but our infrastructure setup with Modal is something that we will continue to use to let us run, inspect, and iterate on this verifier-backed training loop without needing to invest time building our own bespoke infrastructure.
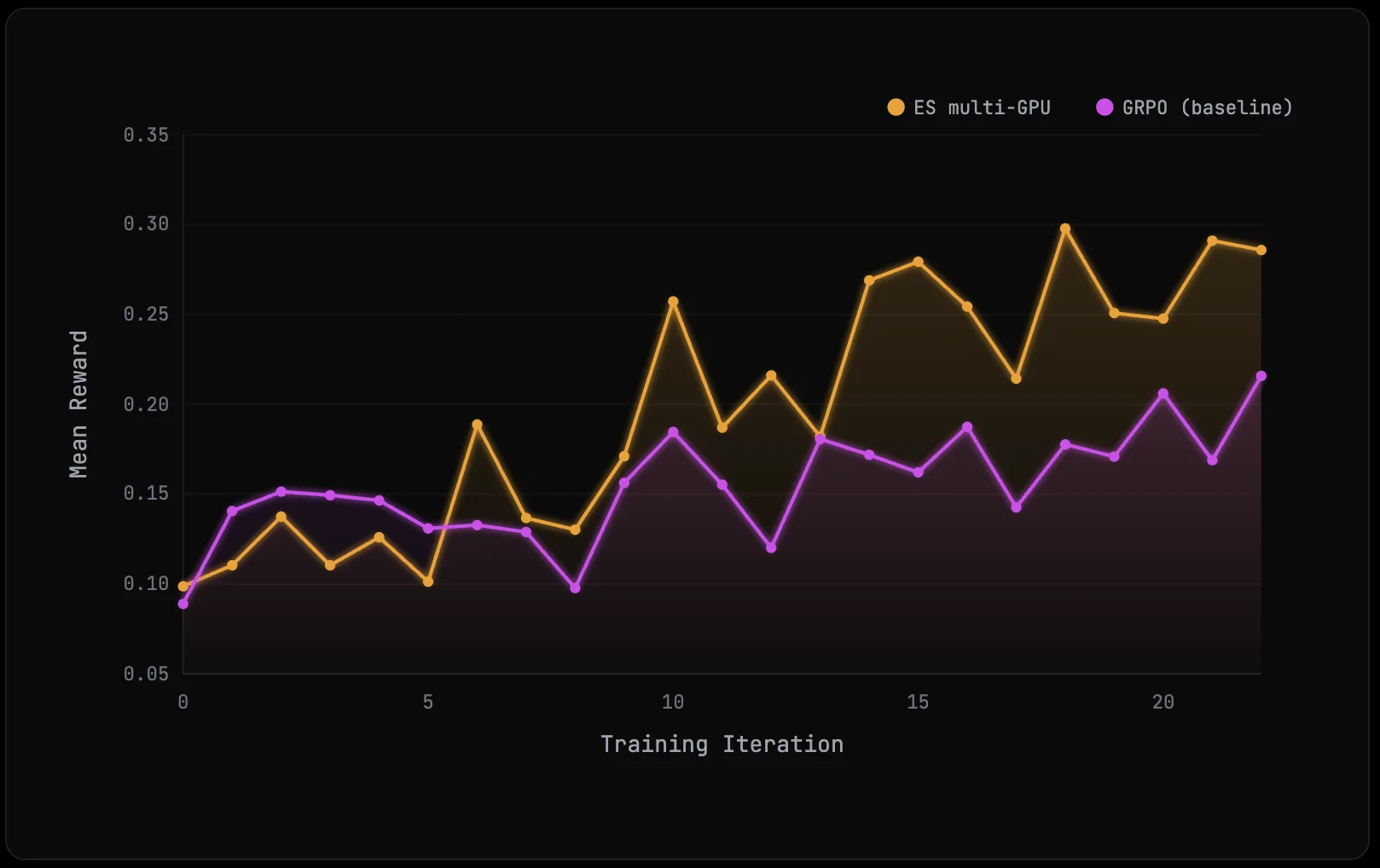
The next experiments are more straightforward now that the training loop, verification path, and checkpoint handoff are working:
- Variance analysis: We want to run more systematic sweeps over sigma, population size, and theorem selection to understand when ES improves and when it stalls.
- Larger models: The open 7B distilled Kimina model is a natural next step if we want to test whether the tradeoff changes as the base model gets stronger.
At this point, the open questions are mostly about experiment design rather than getting the system to run reliably.
What you can learn from this
This infrastructure setup is not specific to theorem proving. You see the same shape in many ML systems: generate outputs on GPUs, run an external verifier or compiler or test harness against them, turn those outcomes into a training signal, and repeat across many independent candidates.
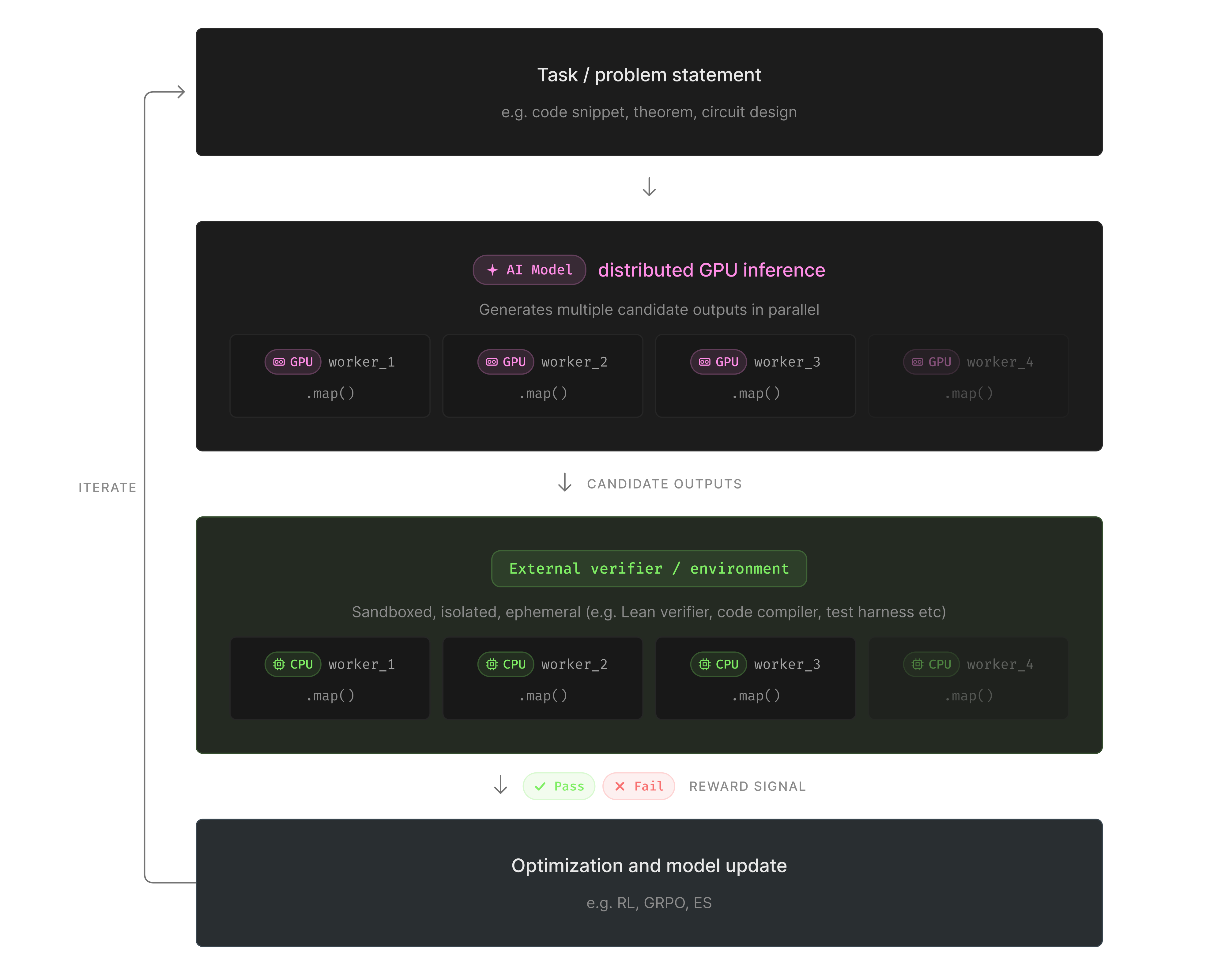
One of the key technical aspects of our experiment was the ability to parallelize GPU inference, isolate verification, and keep the training state portable, all in one workflow. .map() distributed proof generation, Sandboxes contained verifier failures, and Volumes kept checkpoints available between iterations without moving them back to a local machine.
Using Modal, we were able to run the same sparse-reward RL workflow across three very different runtimes without rebuilding the setup each time. We launched runs from our local machine, kept the base model remote, logged to MLflow, and changed population size, theorem batch size, and verification parallelism as the experiments evolved.
We were able to start seeing experimental results within days of starting the project because of the features and usability of the Modal platform. Other infrastructure platforms would have required weeks of testing and iteration before we could get any signal, and once set up our team could fully focus on experimental design without worrying about system reliability.
If you want to dig into the details of our experiment or adapt the setup for your own workflow, the full experiment code is available at github.com/agencyenterprise/modal-rl-theorem-case-study.
References
- Qiu, X., Gan, Y., Hayes, C. F., Liang, Q., Meyerson, E., Hodjat, B., & Miikkulainen, R. (2025). Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning. arXiv:2509.24372. https://arxiv.org/abs/2509.24372
- Numina & Kimi Team. (2025). Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning. arXiv:2504.11354. https://arxiv.org/abs/2504.11354
- Raschka, S. Build a Reasoning Model from Scratch. Manning. https://www.manning.com/books/build-a-reasoning-model-from-scratch
- The base model was
Kimina-Prover-Preview-Distill-1.5B, distilled from the72B Kimina-Prover. We used the project’skimina-lean-server imagefor verification and trained on thelean_workbooksubset ofkfdong/STP_Lean_SFT. ↩