The future of AI needs more flexible GPU capacity
The last couple of years of Gen AI frenzy have brought us some undeniably cool new products, like Copilot and Suno. One thing they all have in common is they demand lots of compute – in particular GPUs. But the supply of GPUs is constrained. This supply-demand imbalance has caused the market for cloud GPUs to behave very differently than other cloud markets.
Why is that? What should we do? And what can we expect going forward? Should startups keep buying long-term GPU reservations from cloud vendors? Or will there be other options in the future?
How do you make money from AI models?
AI is powered by GPUs, and most of the GPU demand today goes towards training large generative models.
But training is a cost center and eventually you need to recoup that cost through real revenue. How do you do that? Enter inference – the less sexy but money-making sibling of training.
So why is most GPU demand driven by training even though inference is where you make the money? I think a lot of it reflects where we are in the cycle – there’s an expectation that the revenue potential for inference is big, but in order to get this, you have to spend a lot of money on training.
The economics of this – high upfront capital, but large potential – is something VCs understand quite well, so I think this explains why model builders have had no challenges raising lots of dollars. But for the economics of this to make sense eventually, we need to see a much larger % of GPU spend going towards inference.
So let’s talk about inference for a second – how is it different than training?
Inference workloads are volatile
Let’s say you expect a bunch of users to use your service for inference and you want to get a bunch of GPUs to handle that. Here’s an interesting problem though: inference is volatile.
Consider a service that gets 1 req/s on average. The number of requests each minute will be a Poisson process that looks something like this:

Let’s say every request takes 10 sec to handle. How many GPUs do you need? If you’re running at 100% utilization, then you need exactly 10. But the noise makes this impossible. In practice, something like 12-15 GPUs running at 60-75% utilization is the right range for this. We simply need a bit of padding in order to handle the noise.
It gets more complicated – the 24h cycle
Let’s make the model a bit more complex and assume you have a night-and-day cycle. Now the request rate looks more like this:
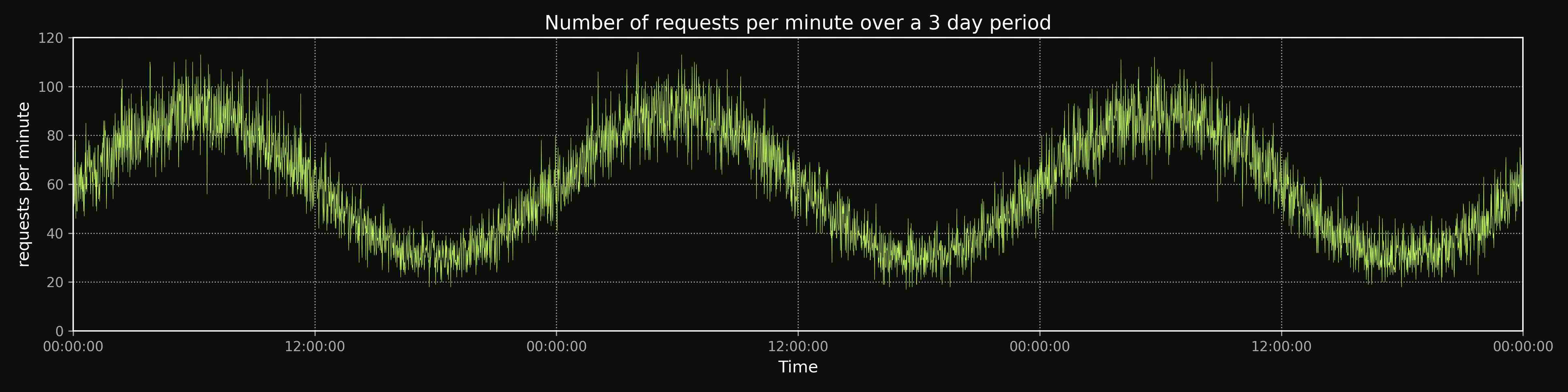
Using fixed capacity for this causes utilization to drop further, because we have to provision for the peak load. This will push the utilization below 50%.
It’s actually a lot worse than that!
Let’s add more sources of volatility you might encounter, like
- The 7 day week
- Events you can’t forecast – a tweet goes viral! someone posts a link to your service on Reddit!
- Trends in your usage (big growth, periods of decline, etc)
- Needs for internal bursty stuff (backfilling etc)
This means in reality your usage volume over a month will look like this:

This looking at it over a month. Seen over a day, it’s super noisy:

How do you pick a number of GPUs now that balance utilization and latency? How do you forecast usage 3 years out based on this? Do you want to tie up a lot of your venture capital dollars in these long-term commitments?
These are hard questions to answer, especially for startups that want to ship cool stuff and not worry so much. It’s not maybe surprising that this is one of the top AI infrastructure concerns among companies in a recent survey:

This is from The State of AI Infrastructure at Scale 2024 which features many other gems – go check it out.
Training is also volatile!
I just talked a lot about inference being volatile. But going back to training, training can be volatile too!
Of course, training tends to be much less latency sensitive. But training demand at a company probably varies quite a lot in reality. Sometimes you have lots of demand for very important jobs, sometimes it’s just long shot experimental R&D. Sometimes a developer is actively iterating and would really benefit from getting a 100 extra GPUs for a few hours.
There’s many other volatile workloads!
The same goes with many other types of things. Batch jobs (including batch inference) for instance. Small training jobs (including fine-tuning) is another example. While inference is inherently volatile and unpredictable, most other workloads also benefit from more flexible GPU consumption.
From our conversations and other people’s experience, the real world utilization of large GPU cluster is often sub 50%!
How can GPU providers provide on-demand GPUs?
So far, I’ve presented some arguments for why GPU demand is quite unpredictable and doesn’t fit the long-term-fixed-size-reservation model. But could GPU supply be flexible?
I think the answer is that it can be, to a much larger extent than today – much like the CPU market where flexible consumption is the default. Supporting this for GPUs is not an easy thing to build, but there’s a whole range of things we can bet on:
Demand pooling
Pooling lots of users into the same underlying pool of compute can improve utilization drastically. It reduces amount of capacity that has to be reserved in aggregate. Instead of provisioning for the sum of the peaks, you can provision for the peak of the sum. This is a much smaller number!

The chart above shows a simulation with 5 users. Because their peaks don’t coincide, we can get dramatically better utilization by pooling all their usage. This requires multi-tenancy, meaning we want to run many different users on the same underlying pool of GPUs.
Supply pooling
It’s also possible to pool the supply of GPUs to increase the capacity. There are a few different strategies:
- Use several regions. Many models (like Stable Diffusion) take a second or two to run. It’s often possible to send the request halfway across the world and back with minimal impact on latency. This is obviously less ideal for latency-sensitive tasks.
- Pool different GPU types together and fall over between them (and use previous-generation GPUs when possible – the ones often left behind by the training crowd)
- Aggregate several cloud vendors, in particular ones with on-demand GPU availability.
It should be mentioned that Modal uses all of these things and have invested a very substantial amount in resource pool scaling and the “bin packing” of jobs. We actually solve a mixed-integer programming problem every minute to maximize our cloud utilization.
Multi-tenancy requires fast scaling
With a multi-tenant pool of compute, and with large variance in demand, it’s critical that we can scale up and down very quickly. In particular, booting up instances and provisioning them is incredibly slow, especially for inference workloads. We want to start containers in seconds, not minutes. This also improves utilization drastically, since hardware is being spent actually crunching numbers, not starting or stopping.
Taking this to its most extreme form, you end up with “serverless” infrastructure. The idea is to let the users write application code, but let the infrastructure handle the container lifecycle management, request routing, and everything else. It’s no secret we are hardcore believers of this at Modal!
Fast initialization of models is a hard problem. A typical workload needs to fire up a Python interpreter with a lot of modules, and load gigabytes of model weights onto the GPU. Doing this fast (as in, seconds or less) takes a lot of low-level work. At Modal we built a file-system purpose made for this, and are spending a lot of time on ways to snapshot CPU and GPU memory for fast initialization.
Demand smoothing
Another option for reducing the variance and improving utilization over time is to shift latency-insensitive demand from periods of high demand to low demand. You could imagine giving discounts for jobs with high turnaround time, or scaling up training jobs overnight. We are thinking a lot about these types of features at Modal!
The future of GPU consumption
To summarize, some trends I expect to be true:
- Future GPU consumption will skew much heavier towards inference vs today
- There will be a much larger market for on-demand GPUs
- A substantial fraction of inference workloads will be powered by on-demand GPUs due to its unpredictable nature
- A meaningful fraction of small and medium size training workloads will shift to on-demand GPUs, because of the flexibility and faster feedback loops
- People will still make long-term GPU reservations to get the lowest possible price. But this will not be the default way to get capacity.
Modal is heavily investing in this. We’re big believers in a future of flexible GPU consumption and have been working on this for several years. We let you run big bursty jobs with hundreds of CPU, or deploy GPU-based cloud functions that can scale up and down instantaneously (including to zero). If you’re interested, please try it out!