Modal + Mistral 3: 10x faster cold starts with GPU snapshotting
Today, Mistral launched Mistral 3, a family of open models with frontier-class performance, customization capabilities, and trusted transparency. We’re proud to offer Day 0 support for running these models on Modal.
Modal enables developers to instantly deploy and scale Mistral 3 models without orchestrating compute infrastructure. Beyond a great DevEx and abundant GPU capacity, Modal also offers cutting-edge features like GPU memory snapshotting that can reduce median cold start time for some of these models by almost 10x, from almost two minutes to just ten seconds.
About Mistral 3
Mistral 3 is the newest frontier open model family from Mistral. It is a suite of multimodal models with strong multilingual support, and it is available in multiple sizes and capabilities for max flexibility.
This blog post focuses on Ministral 3, whose size is well-suited for Modal’s serverless infrastructure. Ministral 3 is the small version of the Mistral 3 family of models and is available in 3B, 8B, and 14B sizes. It performs competitively with the Qwen 3-VL model series on benchmarks. This makes Ministral 3 well-suited for companies that are seeking a balance of intelligence and compute efficiency.
Quickstart
Follow this sample code in our docs, which uses vLLM to serve Ministral 3.
Install Modal, clone our examples repo, and then run the example:
pip install modal
modal setup
git clone https://github.com/modal-labs/modal-examples
cd modal-examples
modal run 06_gpu_and_ml/llm-serving/ministral3_inference.pySee the example text for details on deployment with modal deploy.
How it works
The basic example above takes advantage of several key Modal features:
- Serverless GPUs that automatically scale up and down from 0 based on request volume to the vLLM server.
- Volumes, Modal’s native, distributed file system, to cache model weights and compilation artifacts from vLLM.
- Python-defined infrastructure to keep environment and hardware requirements cleanly in sync with application code.
Together, these features allow developers to deploy Mistral 3 without being blocked on acquiring GPU quota or managing complex configuration surface areas.
Now, speed up cold starts by almost 10x
Modal recently launched a new GPU snapshotting feature in alpha. This can drastically reduce cold starts for workloads that require heavy initialization work—like spinning up a vLLM server.
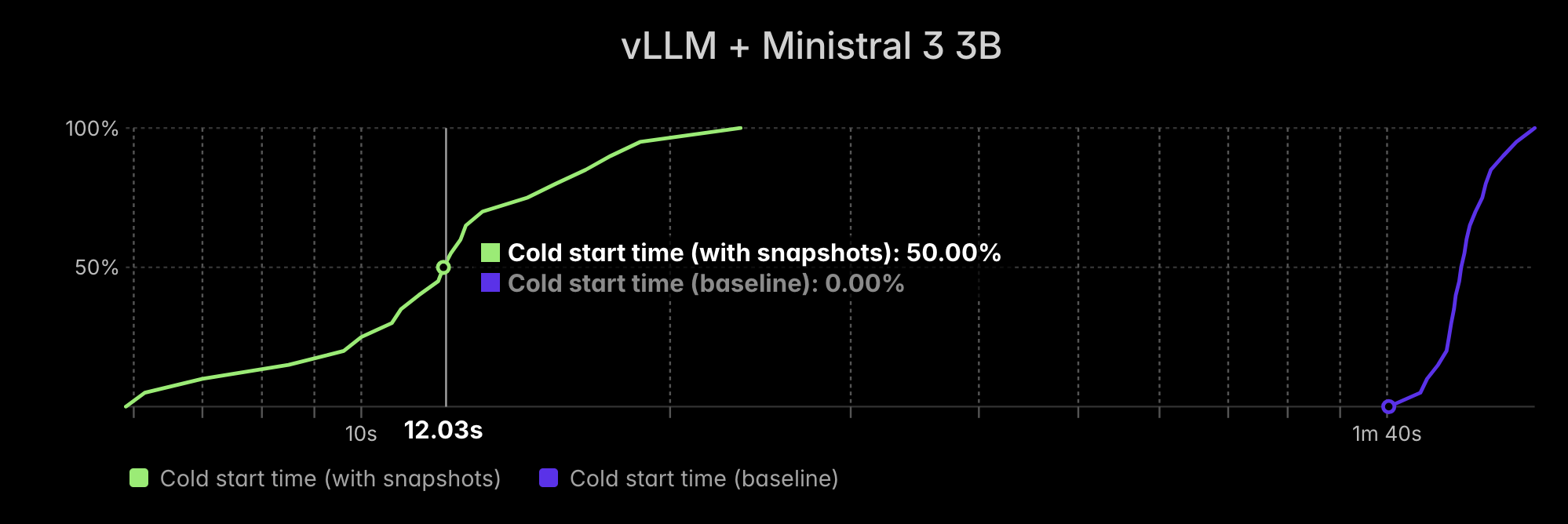
We tested this on the 3B version of Ministral 3 and saw an almost 10x reduction in median cold start time, from ~118s to ~12s. Drastically shorter cold starts means you can deploy Ministral 3 in a way that is both cost-efficient and responsive to user demand.
vLLM + Ministral 3 3B
To use this feature, you must enable Sleep Mode for your vLLM server and set experimental_options={"enable_gpu_snapshot": True} in your Modal App. The first time the vLLM server finishes initializing, it will be put to sleep. This shifts most of the contents of GPU memory to CPU memory, which facilitates the snapshotting process. Upon subsequent starts, the vLLM server is restored from this snapshot.
Try it out for yourself by deploying the code sample here.