NVIDIA Showdown: A100s vs H100s vs H200s
Introduction
Today, GPUs are just as critical to the industry as the AI models that run on them. This has created a hardware arms race that’s been dominated by NVIDIA GPUs. These AI-specific GPUs aren’t the same as your average graphics cards; they’re specialized (in varying degrees) to support AI workloads. Whether you’re running complex language models or processing massive multimodal datasets, the GPU you choose will heavily influence what models you can run and what performance you can squeeze out of them.
Today, our goal is to navigate the difference between three popular GPU models that belong to two sets of architectures: the H100s and H200s, alongside the previous-generation A100s. This guide should serve as a starting point to find the best GPU for your use case. We’ll compare key metrics, architecture decisions, compute performance, and more.
Snapshot
Before diving into the details, let’s tabulate the quick differences between the A100, H100, and H200.
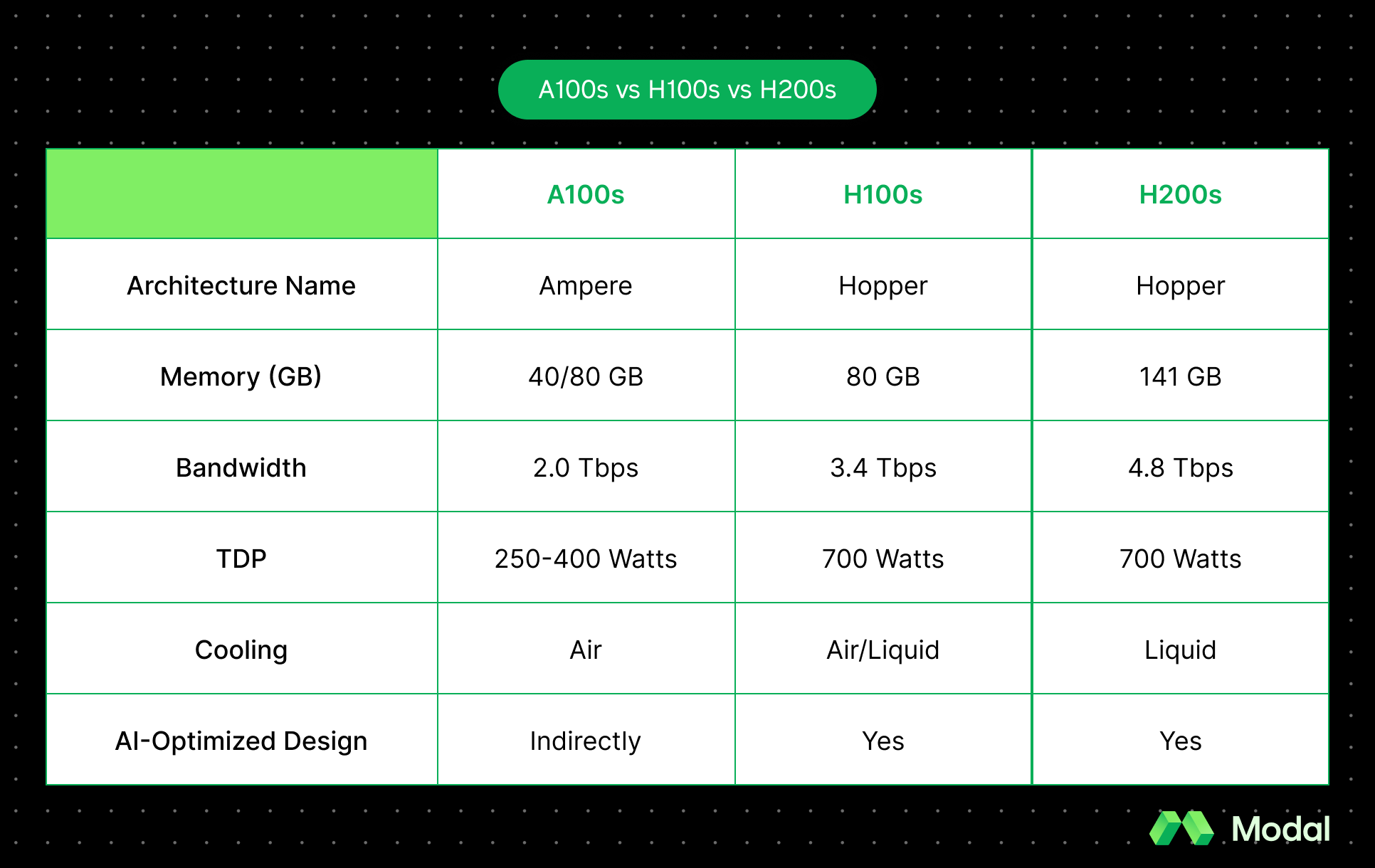
In a nutshell, H100s offer massive gains over A100s, with H200s making marginal gains over H100s. Let’s break down these numbers in detail.
Architecture: A100s vs H100s and H200s
What is the A100s’ architecture?
The NVIDIA A100 is what is often credited as NVIDIA’s breakthrough chip that accelerated their stock to the largest market capitalization in US Stock Market history.
Debuting in 2020, the NVIDIA A100 is based on the Ampere architecture, named after French physicist Andre-Marie Ampere. A100s are massive chips compared to their predecessors (e.g. Volta chips), sporting over 54B transistors. There were a few notable improvements that the A100 made.
The first was multi-instance GPU virtualization and GPU partitioning that made it easy to run independent jobs concurrently, something critical for cloud providers to partially lease GPU chips. For instance, a single A100 GPU chip can deliver seven virtual GPU instances at no additional cost, with safe partitions due to isolated faults. However, virtualization reduces the memory available to each virtual GPU, with a sevenfold partition reducing memory to 5 GB that otherwise would be 40 GB for a single GPU.
Additionally, the NVIDIA A100 dramatically increased support for deep learning (DL) and high-performance computing (HPC) data types. DL and HPC rely heavily on tensor float (TF) computing, where precision is variable depending on the operation. A100s specifically targeted TF compute. For instance, A100s have a TensorFloat-32 (TF32) data type that accelerates float operations over 10x faster than the preceding V100 Volta chip. Beyond TF32, A100s support multiple data types, including INT4 (integer), INT8, FP16 (floating point), FP32, FP64, and BF16 (brain floating point). This is particularly helpful to DL models that use brain floating point values, which offer wider ranges and reduced memory use, while still supporting other operations that might prefer floating point math for higher precision. Additionally, A100s support FP64, a preferred type of HPC that was first introduced by the IEEE Standard 754.
Finally, the Ampere architecture introduced the third generation of NVLink technology (available in the SXM version of A100s), which enabled faster GPU-to-GPU communication at a purported 600 GB/s.
What is the H100s’ architecture?
Debuted in 2022, the NVIDIA H100 is based on the Hopper Architecture, named after the famous American computing pioneer, Grace Hopper. H100s are even more massive chips, sporting over 80B transistors. But what makes the H100 so novel isn’t the size. Rather, it’s the specialization.
H100s have a dedicated transformer engine designed for language models up to 1 trillion parameters. Specifically, Hopper Architecture’s tensor cores could mix FP8 and FP16 precisions that dramatically accelerate AI calculations. Beyond that, Hopper Architecture is brutally fast, with a 3x improvement on FLOPs (floating-point operations per second) for previous A100s data types, including TF32, FP64, FP16, and INT8.
However, H100s’ improvement on A100s wasn’t limited to just FLOPs and bare metal calculations. H100s specifically targeted a common bottleneck: data transfer, where moving data into and out of GPUs served as the limiting factor. H100s introduced the fourth generation of NVLink. At 900 GB/s transfer between GPUs, it was a 50% improvement over A100s with the SXM form factor.
H100s also added support for the Scalable Hierarchical Aggregation and Reduction Protocol (SHARP). SHARP offloaded simple operations to the network instead of CPUs and GPUs so that CPUs and GPUs could focus on the hard compute tasks rather than lighter combinational work to achieve final results.
What is the H200s’ architecture?
Debuted in 2023, H200s have fundamentally the same architecture as H100s. However, they are able to deliver significantly better performance due to increased VRAM and memory bandwidth, which is covered in more detail in the next section. With 141GB of internal memory and 4.8 Tbps of bandwidth, H200s can outperform H100s by >45% for memory-bound workloads, according to NVIDIA.
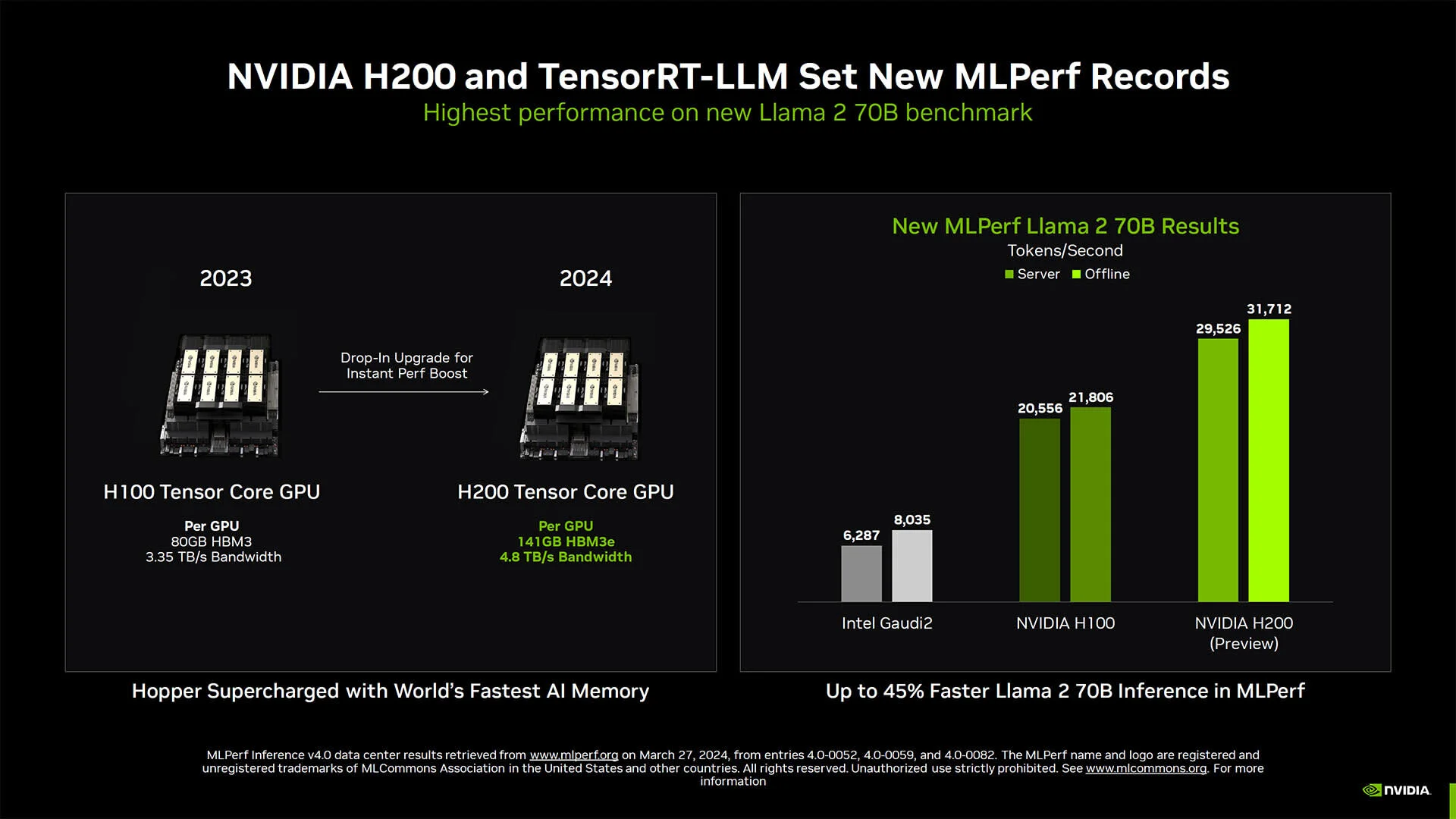
The memory improvements are critical because they allow H200s to make computations more efficiently, reducing energy cost levels by over 2x.
However, H200s have the same tensor architecture as H100s. Choosing between H100s and H200s is more a matter of job size and budget than it is about choosing the right architecture!
Memory: A100s vs H100s and H200s
GPU memory plays an important role in AI training because it is vital that the GPUs are capable of storing and processing large datasets. More memory means you can fit large models in your GPUs. More memory bandwidth means the GPU can crunch through computations faster due to a higher rate of data transfer between different levels of GPU memory hierarchy.
What are the memory specs of an A100?
The A100 offers either 40GB or 80GB of memory, with a net bandwidth of 2TB/s.
A100s use HBM2E (High Bandwidth Memory 2E) memory. HBM2E is a memory type by Micron with four to eight DRAM memory layers in a single device. This architecture has better power efficiency that can push over 3.2 Gbps per memory pin.
What are the memory specs of an H100?
H100s support 80 GB of memory with a bandwidth of 3.35TB/s.
The increased bandwidth of H100s is due to Micron’s advanced HBM3e (High Bandwidth Memory 3e) memory, which improved upon HBM2e by decreasing the core voltage by 0.1 volts, taller stack heights, and more dense DRAM chips. H100s doubled the throughput per pin of A100s, offering 6.4 Gbps per memory pin.
What are the memory specs of an H200?
H200s use the same memory stack but pushed the memory volume to 141 GB and pushed the net memory bandwidth to 4.8 TB/s.
Compute performance: A100s vs H100s and H200s
When planning for these GPUs, you also need to consider their compute performance, which is measured in terms of TFLOPS (Tera-Floating-Point Operations per Second). Compute power is another factor into how fast your workloads can run on these GPUs.
What is the A100s’ compute performance?
The maximum TFLOPS rating for the A100 is 624 TFLOPS at FP16 precision. FP8 is not supported. View the full spec sheet for performance at other precisions.
What is the H100s’ and H200s’ compute performance?
The max TFLOPS rating for H100 and H200 is the same, at 1,979 TFLOPS using FP16 precision and 3,958 TFLOPS using FP8. View the full spec sheet for performance at other precisions.
Compute Performance Summary
GPU compute performance is determined by all the criteria mentioned above. These factors directly impact training speed (how fast a model learns) and inference speed (how fast the model can make predictions). The A100 can handle medium-sized workloads effectively, and has become an industry standard. Using H100s will result in speed-ups for both compute-bound and memory-bound workloads, since H100s have both higher memory bandwidth and TFLOPS. For the largest language models H100s boast up to 4x training speedups and up to 30x inference speedups compared to A100s, according to benchmarks by NVIDIA. The H200 pushes this even further, with speed-ups over 40% compared to H100s for certain memory-bound workloads.
The best way to see whether upgrading your GPU will result in a performance boost is to try it out directly. Cloud platforms like Modal make it easy to swap GPUs in and out for your workloads.
Cost
When evaluating which GPU is right for your infrastructure, cost is naturally an important consideration. If you choose to buy the GPU outright, it would require a significant amount of capital.
The A100 ranges from $10,000-$15,000, depending on GB of storage and form factor (PCIe vs SXM5). The H100 ranges from $25,000 to $30,000, with the price being affected by form factor (PCIe vs SXM5) and potential multi-GPU configurations. The H200 ranges from $30,000 to $40,000, with similar form factor considerations impacting the price.
For production deployments, cloud platforms are a much more practical option than buying servers outright. With various purchase models for renting GPUs, from serverless to on-demand to reservations, you can significantly lower upfront cost and pick an approach that works for your business.
You can view comparisons of A100, H100, and H200 pricing by different providers. Unsurprisingly, cloud pricing for these options also increases in that order.
Conclusion
All three of these NVIDIA GPUs have their place in the industry. What is appropriate for your workload is dependent on your desired cost-to-performance ratio. There are no hard and fast rules here, except for selecting GPUs that have enough VRAM to fit your models!
The A100 is an inference powerhouse for large models (sub-70B parameters), especially those that are memory-bound. With both 40GB and 80GB options, you can pick the option that fits your model size. A100s are also frequently used for small fine-tuning jobs.
The H100 is ideal for running even larger models, or getting faster performance from what you’re running on A100s today.
The H200 is ideal for running the largest of models, some of which may not fit at all in a single node of H100s! You can also upgrade to H200s from H100s if you have a memory-bound workload (which is often the case for LLM inference). Both H100s and H200s are commonly used for speeding up fine-tuning or training models from scratch.
If these GPUs are still not enough, you can explore B200s, which are the most powerful and most expensive datacenter GPU offered by NVIDIA at the time of writing (September 2025).
Ultimately, selecting the right GPU will significantly impact the speed of your inference and training workloads. You should test your workloads across these GPUs to figure out what gets you your desired price and performance.
Ready to try out Nvidia A100s, H100s, or H200s? Sign up today for Modal! Running any function on GPUs is as easy as:
import modal
app = modal.App()
@app.function(gpu="H200") # or "H100" or "A100"
def run_big_model():
# This will run on a Modal H200