NVIDIA Showdown: H100s and H200s vs B100s and B200s
Introduction
AI has sharply accelerated GPU development. Notably, it’s a hardware arms race that’s dominated by a single manufacturer: NVIDIA. NVIDIA’s AI-optimized GPUs are designed for training and deploying the largest, most cutting-edge AI models on the market today.
Today, we will explore the differences between NVIDIA’s most recent two classes of GPUs: H100s and H200s, against B100s and B200s. This guide will discuss key metrics, architecture decisions, how to choose the right GPU for your use case, and more.
Overview
The H100 chip, sporting a new Hopper architecture, was a breakthrough by NVIDIA to strongly tailor GPU performance to deep learning (DL) models. The H100 chip drastically improved on the popular A100 chip, which was originally the default choice for compute-intensive tasks and propelled NVIDIA into US Stock Market stardom.
Soon after, NVIDIA launched the H200 chip, which had the same architecture as the H100 but with a bigger memory bank and higher memory bandwidth, making it faster for memory-bound workloads.
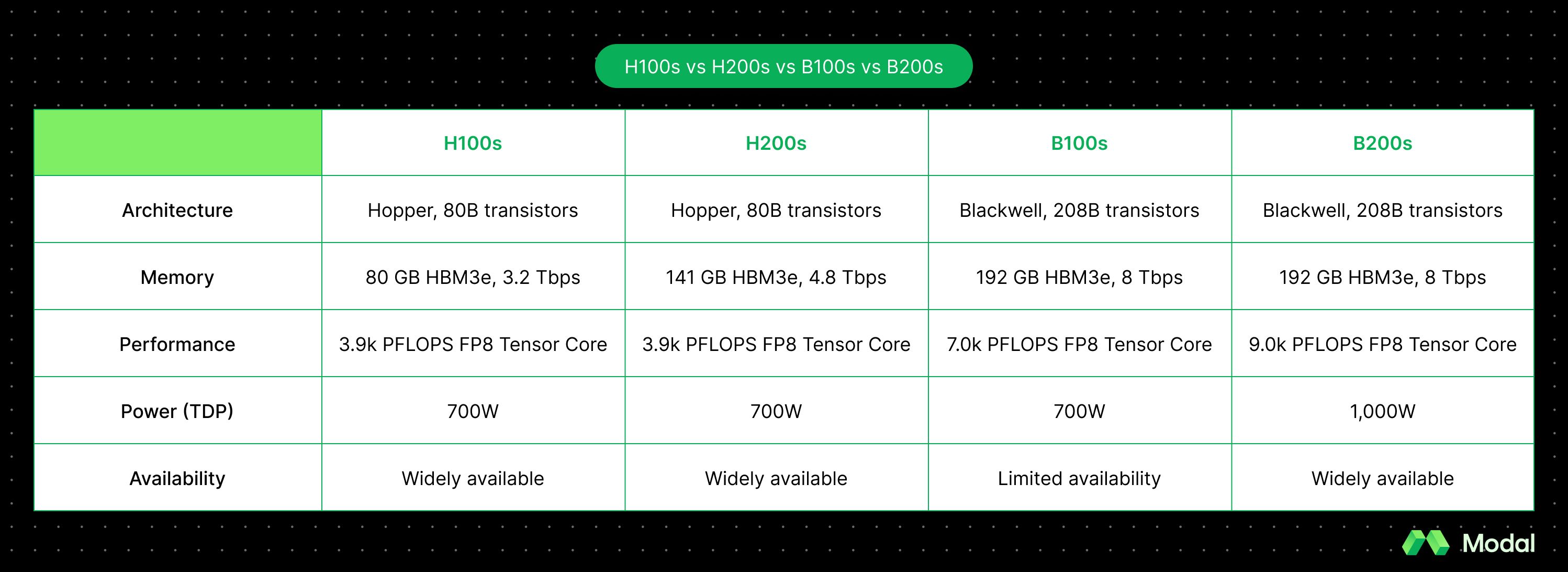
Recently, NVIDIA launched another major upgrade to GPU architecture with the release of Blackwell. B100 and B200 chips are the successor to H100s and H200s. While the corresponding leap in performance was not as drastic as the H100’s jump over A100s, Blackwell chips still significantly outperform Hopper chips.
Architecture: H100s and H200s vs B100s and B200s
What are the highlights of the H100s’ architecture?
Debuted in 2022, the NVIDIA H100’s Hopper Architecture was named after Grace Hopper, the famous American computing pioneer. H100s are massive chips, with over 80B transistors. They are also incredibly specialized, with a dedicated transformer engine designed for language models up to 1 trillion parameters.
Hopper Architecture’s tensor cores improved on predecessors by focusing on common calculation types needed for AI training. For instance, they could mix floating point precision types (FP8 and FP16 specifically), dramatically accelerating AI calculations.
Hopper Architecture is fast across numerical formats (relative to the format’s difficulty), with 3958 teraFLOPS for Int8 calculations and 34 teraFLOPS for FP64 calculations.
However, beyond teraFLOPS, a primary goal of H100s was to alleviate the data transfer bottleneck, as that was a limiting factor in many A100-powered supercomputers. H100s supported a new generation of NVLink, a transfer utility with over 900 Gbps bi-directional data support when using NVIDIA HGX servers. This was a 50% improvement over the previous-generation NVLink in A100s, bringing massive gains to multi-GPU workloads.
What are the highlights of the H200s’ architecture?
Debuted in 2023, H200s have a nearly identical architecture to H100s. However, due to its larger memory and higher memory bandwidth, they can both accomodate larger models as well as accelerate the performance of memory-bound workloads like LLM inference. NVIDIA claims that users can see up to 2x faster LLM inference performance on H200s.
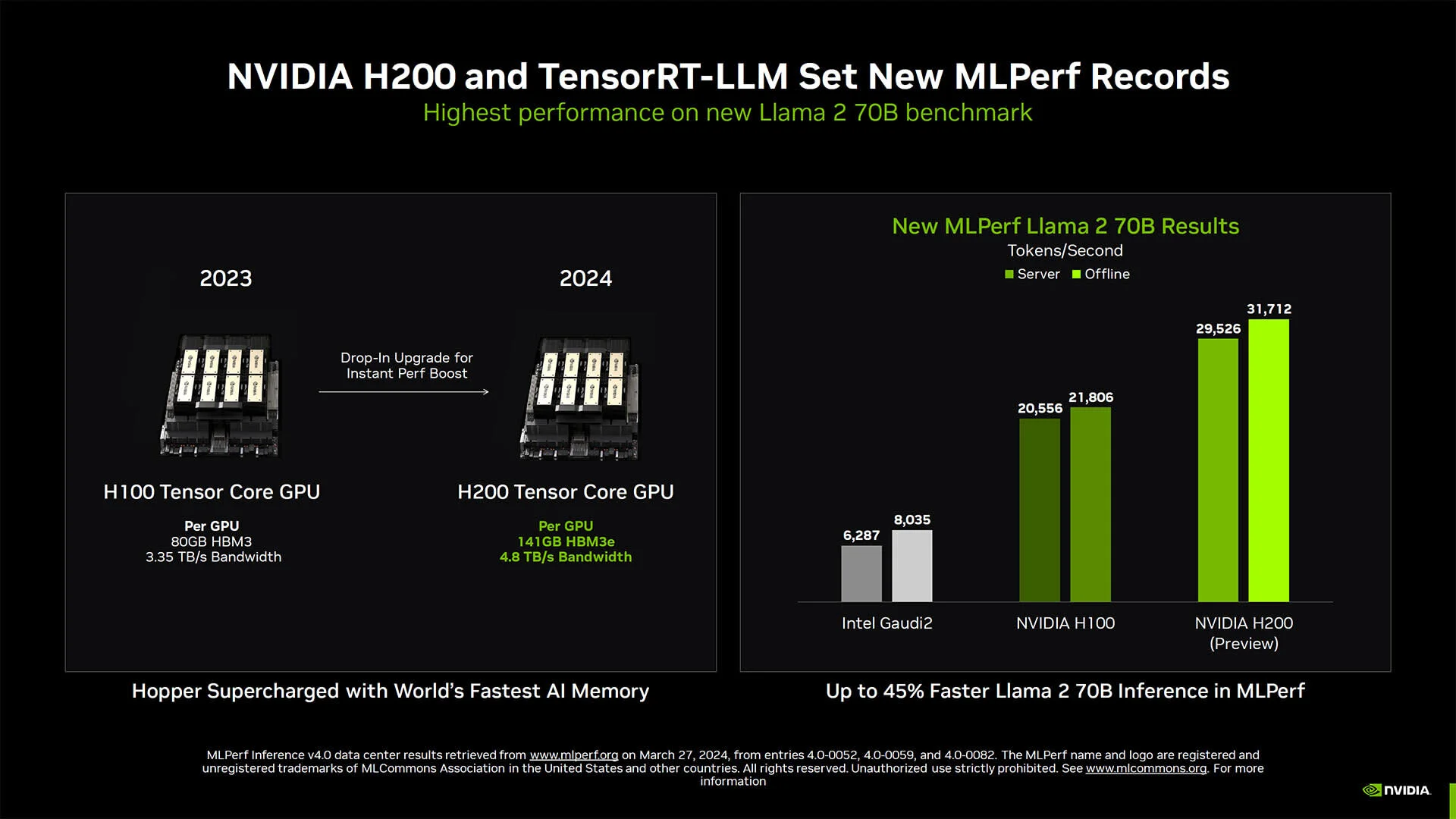
Why does memory bandwidth matter? Higher bandwidth means faster data transfers between different parts of the GPU’s memory. This is necessary for efficiently sending data to the parts of the GPU that actually do computations. For workloads bottlenecked on memory bandwidth, the computational cores don’t get saturated—so a bandwidth upgrade results in performance gains.
Naturally, H200s are more expensive than H100s and might be overkill for certain jobs, depending on how you want to balance price vs performance. However, they pale in comparison to NVIDIA’s latest innovation: the Blackwell series of GPUs.
What are the highlights of the B100s’ architecture?
B100s sport NVIDIA’s latest Blackwell architecture, with over 208B transistors. Named after American mathematician David Blackwell, B100s are also designed for AI use cases, and their launch was highly anticipated.
B100s improve multiple aspects of AI training. They’re designed for LLMs as well as Mixture-of-Experts (MoE) models, which are models that use multiple sub-models trained on different subsets of data. Blackwell’s updated transformer engine supports new quantization formats (where numbers are “snapped” to a grid of values to make the model smaller and faster) and community-defined microscaling formats.
B100s were designed to work together, with a blazing fast 10 Terabytes per second (Tbps) interconnect, allowing multiple chips on the same node to form a superchip GPU. They’re incredibly fast at smaller-order math, supporting petaFLOPs of speed for INT8 calculations, with comparable performance to H100s for F32 and F64 performance.
What are the highlights of the B200s’ architecture?
Similar to the difference between the H100s and H200s, B200s are effectively souped up B100s. However, while the difference between H100s and H200s was due to improved memory and memory bandwidth, B100s and B200s have identical memory specs but different compute performance and power draw specs. B200s report higher TFLOPS across all numerical formats (e.g. 18k vs 14k for FP4, 9k vs 7k for FP8), which means they offer a performance boost vs B100s for compute-bound workloads like the batch prefill / prompt processing stage of LLM inference. B200s, however, also have a higher power draw (1000W vs 700W), meaning they’re more expensive to operate.
Interestingly, B200s are much easier to find in the wild than B100s. Many cloud providers, including Modal, only offer B200s, and it appears that the industry as a whole skipped over B100s to go straight to their more powerful siblings.
Memory: H100s and H200s versus B100s and B200s
Memory is essential to AI training and inference, as GPUs need to store and process large quantities of data at once. With more memory bandwidth, GPUs can better saturate their computational cores.
HMB3e Memory
H100s, H200s, B100s, and B200s all offer HMB3e (High Bandwidth Memory 3e) memory, though some H100s models come with the less enhanced version (HMB3). HMB3e is developed by Micron; it’s a memory powerhouse with a core voltage of 0.1 volts, exceptionally tall stack heights, and dense DRAM chips. Each pin on an HMB3e offers 6.4 Gbps.
Memory Size
B100s and B200s have bigger internal memory, with 192 GB each of HMB3e. H200s and H100s, meanwhile, have 141 GB and 80 GB, respectively. This is important when serving large models, as you need to ensure the GPU (or multiple GPUs) have enough VRAM to actually hold the model weights.
B200s and B100s also have a higher memory bandwidth of 8 Tbps (compared to 4.8 for H200s and 3.2 for H100s). This means you should see performance boosts for memory-bound workloads.
Power Efficiency: H100s, H200s, B100s, and B200s
Thermal Design Power (TDP) refers to the maximum amount of heat that the GPU can generate. A higher TDP means that more power can be pushed through a GPU’s transistors, improving processing speed.
H100s, H200s, and B100s have a TDP of 700 Watts. Meanwhile, the B200 increases its TDP to 1,000 Watts, which is needed to support its higher compute performance but also drives up operational costs.
Availability and cost
You can find H100s, H200s, and B200s across hyperscalers like AWS and major alt-clouds. B100s are difficult to find.
Cost is naturally a key consideration for purchasing GPUs. These chips are quite pricy to buy outright—not to mention that availability is incredibly constrained, so individual buyers will have a difficult time accessing supply. The H100 ranges from $25,000 to $30,000, with the price being affected by form factor (PCIe vs. SXM5) and potential multi-GPU configurations. The H200 ranges from $30,000 to $40,000, with similar form factor considerations impacting the price. B200s cost $40,000+ from our research.
Unless you are a behemoth AI company, you’re going to be using these chips via a cloud provider. We compiled pricing and availability information across many cloud providers to help you quickly see and compare the options out there. See H100 pricing, H200 pricing, B200 pricing.
How do I choose between H100s, H200s, B100s, and B200s?
Your GPU choice will largely be determined by the size and complexity of the model you’re training or deploying, what minimum performance numbers you need to hit, and what price you’re willing to pay.
- H100s remain the high-performance option for deploying the latest image generation models and large (e.g. 70B parameter) but not-the-largest open-source LLMs.
- H200s provide an upgrade for memory-bound workloads like LLM inference if you need to increase performance further, such as for interactive customer-facing workloads.
- B100s are hard to find, so you likely won’t be considering this option.
- B200s are the most performant GPU available at the time of writing; use them to run models like DeepSeek-R1 which otherwise would not fit on a single node of 8xH100s. Many workloads will see an immediate 2-4x speedup when migrated to B200s. For those who are price-insensitive, B200s are the way to go for squeezing every last bit of performance you want out of your models.
Modal is one of the fastest ways to get started with these powerful GPUs. With one line of code you can attach these GPUs to your Python function; Modal spins up and down compute for you based on request volume, and you only ever pay for what you use.
import modal
app = modal.App()
@app.function(gpu="B200") # or "H200" or "H100"
def run_big_model():
# This will run on a Modal B200