Modal + Datalab: Deploy high-throughput document intelligence in <5 minutes
We’re excited to collaborate with Datalab, creators of Marker and Surya, to make it faster than ever for developers and teams to deploy best-in-class document intelligence models.
Marker is a purpose-built, sub-billion-parameter model trained specifically for document structure. It delivers deterministic, high-fidelity parsing without the hallucination or instability of larger LLMs, and does so at a fraction of the cost. Marker, along with Datalab’s other open-source tools, have earned 48k+ stars on GitHub and are trusted by researchers, startups, and enterprise teams alike.
Modal already powers Datalab’s hosted platform, enabling them to deliver reliable, scalable model serving and roll out new releases quickly:
Now, any builder or team can use Modal to instantly deploy Datalab’s state-of-the-art Marker pipeline and Surya OCR toolkit. Datalab’s tools remain free for research, personal use, and startups under $2M funding/revenue, with licensing options for commercial customers.
Quickstart
Marker is easy to clone and run locally, but you can deploy it on Modal to maximize scalability and throughput. Clone the Marker repository and deploy the Modal example here, which will provision a GPU container in Modal, install marker, and expose its functionality behind a FastAPI endpoint.
pip install modal
modal setup
git clone git@github.com:datalab-to/marker.git
cd marker/examples/
modal deploy marker_modal_deployment.pyThat’s it! For a more detailed full-stack example, check out this Modal example of building a quick document OCR web app.
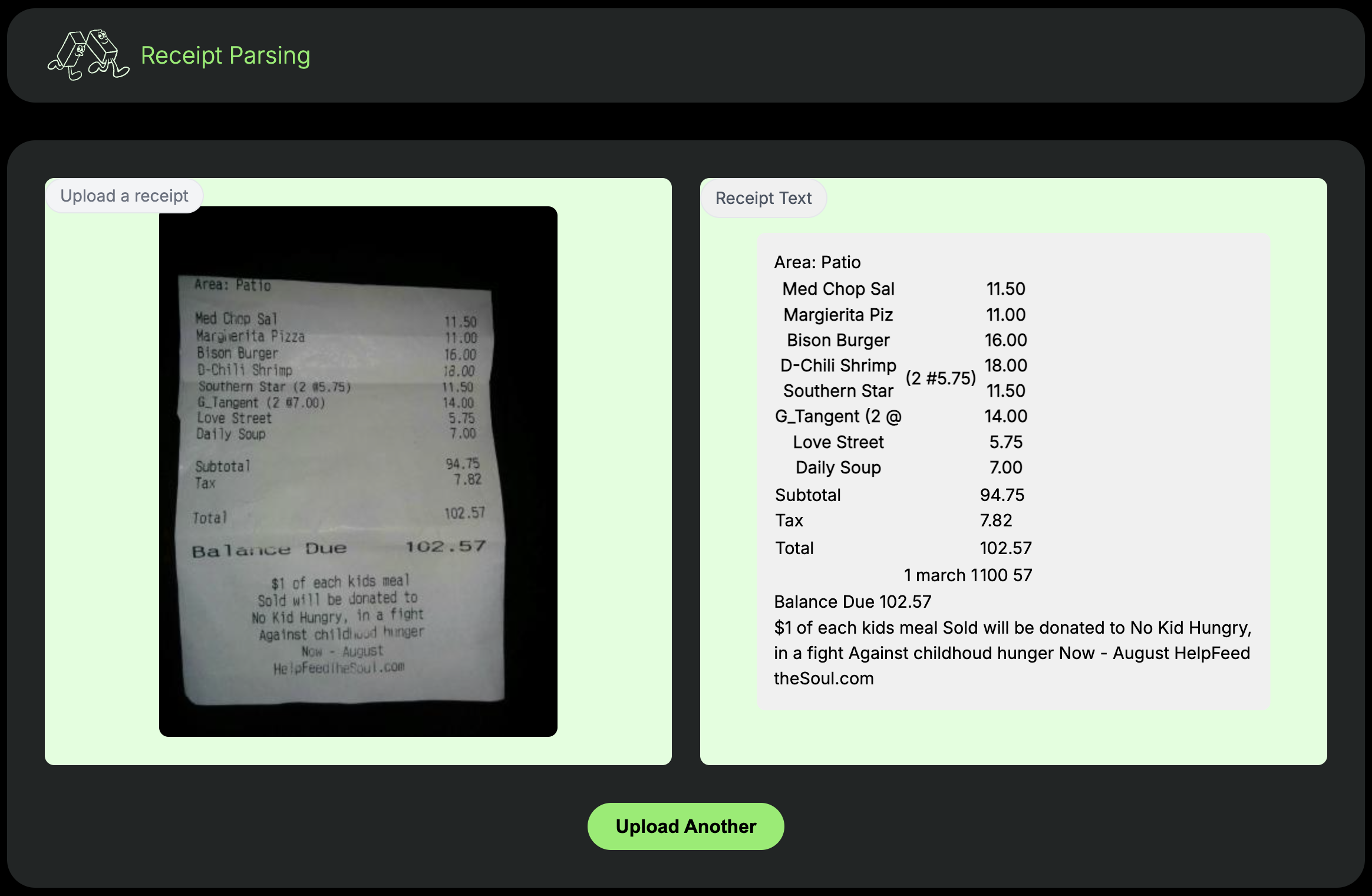
Modal comes with $30/mo in free compute credits, which is plenty to get started with your OCR tasks.
How it works
Modal allows you to deploy Marker on GPUs in seconds. Modal also autoscales GPUs for your deployment so you get max throughput on batch jobs with no additional effort.
Here’s what happens behind the scenes:
First, Marker model weights get cached in a Modal Volume, which cuts cold start times. No need to redownload models every time, and Volumes guarantee fast reads no matter where your inference function is running.
marker_cache_path = "/root/.cache/datalab/"
marker_cache_volume = modal.Volume.from_name(
"marker-models-modal-demo", create_if_missing=True
)
marker_cache = {marker_cache_path: marker_cache_volume}Then, when the inference function is called, Modal spins up a container using the environment and hardware requirements specified in the function decorator. You don’t need to use config files, as everything is defined in-line with application code.
inference_image = modal.Image.debian_slim(python_version="3.12").uv_pip_install(
"marker-pdf[full]==1.9.3", "torch==2.8.0"
)
@app.function(gpu="l40s", volumes=marker_cache, image=inference_image)
def parse_document(document: bytes, ...) -> str | dict:
# Load Marker model from Volume and run
...Need to process thousands of PDFs at once? Modal autoscales instantly—up to thousands of GPUs—based on request volume. Our global capacity pools guarantee that you never wait on quota.
Why Marker?
Marker supports over 90 languages, handles incredibly complex and dense tables, and is state-of-the-art in extracting math from PDFs. Marker can be used for a wide range of tasks like:
- Indexing PDF knowledge bases for RAG
- Parsing multilingual PDF content for training
- Extracting key information from unstructured documents
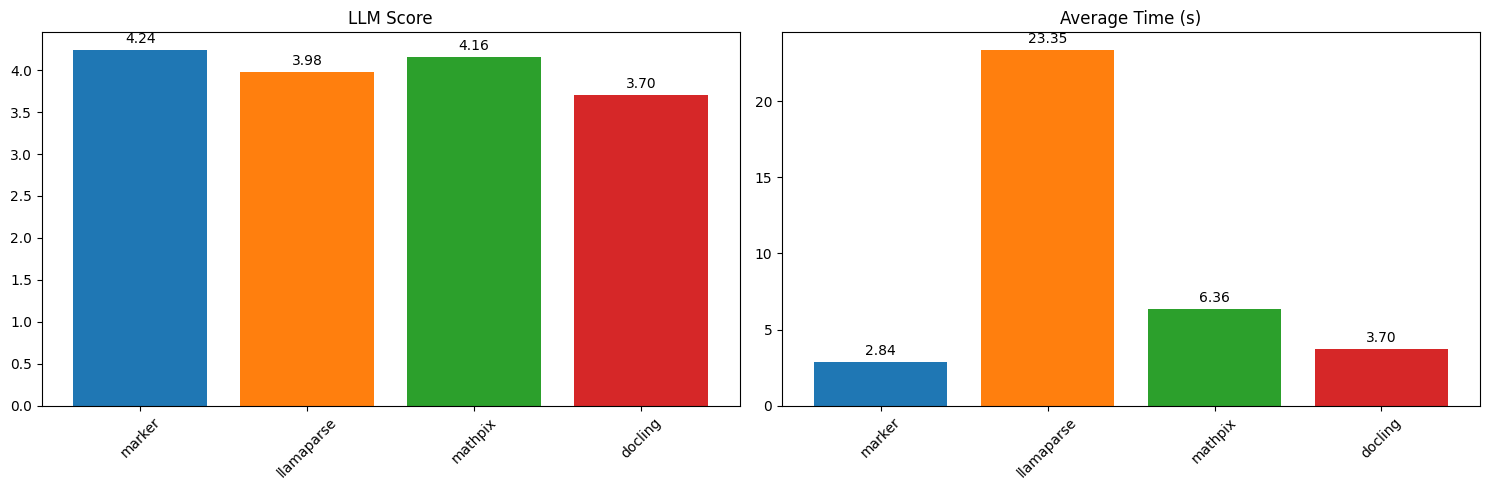
Marker benchmarks favorably for both accuracy and throughput compared to cloud services like Llamaparse and Mathpix, as well as other open source tools. Accuracy benchmarks above were performed on single PDF pages from Common Crawl and scored using LLM-as-a-judge.
10x Marker throughput on Modal
Accuracy alone isn’t enough. Real-world systems demand high throughput and reliability to process millions of documents quickly, consistently, and cost-effectively. Marker was designed with that in mind, and Modal is the fastest way to achieve scale for self-deployments.
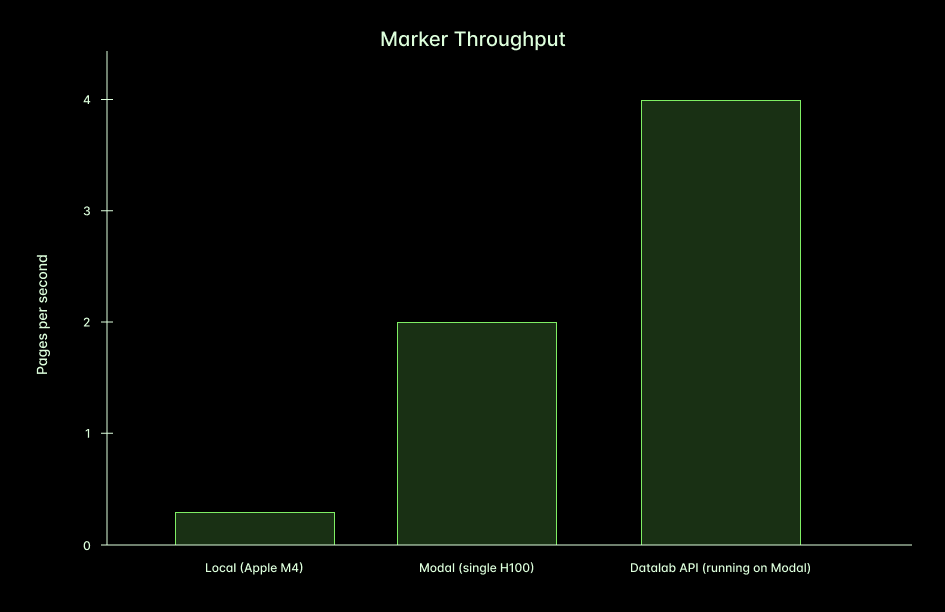
On an M4 Mac using Apple MPS (no GPU), you can process around 0.22 pages per second. On Modal, you can increase this to around 2.2 pages per second per container. This 10x gain comes from using more powerful hardware (e.g. H100 GPU), Flash Attention optimizations, and environment tuning (for settings like OMP_NUM_THREADS). Note that in practice, you should experiment with various configurations to find your ideal balance of accuracy, cost, and throughput
If you’re batch processing multiple PDFs, Modal can easily autoscale to hundreds of GPUs, further improving overall throughput.
Need a managed solution for a commercial use case? Datalab’s API platform uses additional inference optimizations to enable a page throughput of around 3-4 pages per second. This is deployed on Modal behind the scenes!
Deploy best-in-class document intelligence
We’re excited to be deepening our collaboration with Datalab. Many of our users have already been turning to Modal for best practices on deploying Marker and Surya, and this collaboration now makes that seamless.
Get started today with this example.
'/%3e%3cpath%20d='M109.623%2064L73.2925%201.07001C72.0925%201.76001%2071.0825%202.76%2070.3625%204L1.0725%20124C-0.3575%20126.48%20-0.3575%20129.52%201.0725%20132L33.4026%20188C34.1126%20189.24%2035.1325%20190.24%2036.3325%20190.93L109.613%2064H109.623Z'%20fill='url(%23paint1_linear_342_139)'/%3e%3cpath%20d='M183.513%2064H109.613L36.3325%20190.93C37.5325%20191.62%2038.9025%20192%2040.3325%20192H104.993C107.853%20192%20110.492%20190.47%20111.922%20188L183.513%2064Z'%20fill='%2309AF58'/%3e%3cpath%20d='M365.963%20132C366.673%20130.76%20367.033%20129.38%20367.033%20128H294.372L258.042%20190.93C259.242%20191.62%20260.612%20192%20262.042%20192H326.703C329.563%20192%20332.202%20190.47%20333.632%20188L365.963%20132Z'%20fill='%2309AF58'/%3e%3cpath%20d='M225.083%200C223.653%200%20222.283%200.380007%20221.083%201.07001L294.362%20128H367.023C367.023%20126.62%20366.663%20125.24%20365.953%20124L296.672%204C295.242%201.53%20292.603%200%20289.743%200H225.073H225.083Z'%20fill='url(%23paint2_linear_342_139)'/%3e%3cpath%20d='M258.033%20190.93L294.362%20128L221.083%201.07001C219.883%201.76001%20218.873%202.76%20218.153%204L183.513%2064L255.103%20188C255.813%20189.24%20256.833%20190.24%20258.033%20190.93Z'%20fill='url(%23paint3_linear_342_139)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_342_139'%20x1='155.803'%20y1='80'%20x2='101.003'%20y2='-14.93'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23BFF9B4'/%3e%3cstop%20offset='1'%20stop-color='%2380EE64'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_342_139'%20x1='8.62251'%20y1='174.93'%20x2='100.072'%20y2='16.54'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2380EE64'/%3e%3cstop%20offset='0.18'%20stop-color='%237BEB63'/%3e%3cstop%20offset='0.36'%20stop-color='%236FE562'/%3e%3cstop%20offset='0.55'%20stop-color='%235ADA60'/%3e%3cstop%20offset='0.74'%20stop-color='%233DCA5D'/%3e%3cstop%20offset='0.93'%20stop-color='%2318B759'/%3e%3cstop%20offset='1'%20stop-color='%2309AF58'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint2_linear_342_139'%20x1='340.243'%20y1='143.46'%20x2='248.793'%20y2='-14.93'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23BFF9B4'/%3e%3cstop%20offset='1'%20stop-color='%2380EE64'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint3_linear_342_139'%20x1='284.822'%20y1='175.47'%20x2='193.372'%20y2='17.0701'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2380EE64'/%3e%3cstop%20offset='0.18'%20stop-color='%237BEB63'/%3e%3cstop%20offset='0.36'%20stop-color='%236FE562'/%3e%3cstop%20offset='0.55'%20stop-color='%235ADA60'/%3e%3cstop%20offset='0.74'%20stop-color='%233DCA5D'/%3e%3cstop%20offset='0.93'%20stop-color='%2318B759'/%3e%3cstop%20offset='1'%20stop-color='%2309AF58'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)