
Screenshot with Chromium
In this example, we use Modal functions and the playwright package to take screenshots
of websites from a list of URLs in parallel.
You can run this example on the command line with
modal run 02_building_containers/screenshot.py --url 'https://www.youtube.com/watch?v=dQw4w9WgXcQ'This should take a few seconds then create a /tmp/screenshots/screenshot.png file, shown below.
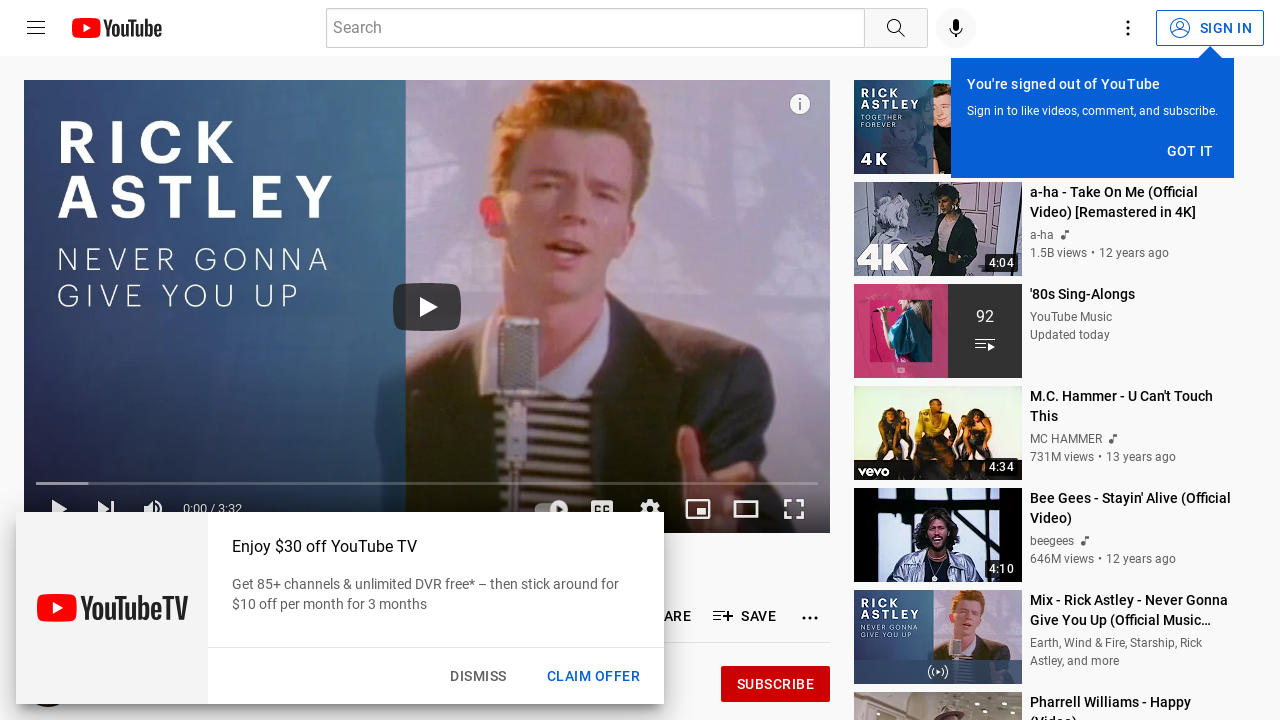
Setup
First we import the Modal client library.
import pathlib
import modal
app = modal.App("example-screenshot")Define a custom image
We need an image with the playwright Python package as well as its chromium plugin pre-installed.
This requires intalling a few Debian packages, as well as setting up a new Debian repository.
Modal lets you run arbitrary commands, just like in Docker:
image = modal.Image.debian_slim(python_version="3.12").run_commands(
"apt-get update",
"apt-get install -y software-properties-common",
"apt-add-repository non-free",
"apt-add-repository contrib",
"pip install playwright==1.42.0",
"playwright install-deps chromium",
"playwright install chromium",
)The screenshot function
Next, the scraping function which runs headless Chromium, goes to a website, and takes a screenshot. This is a Modal function which runs inside the remote container.
@app.function(image=image)
async def screenshot(url):
from playwright.async_api import async_playwright
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
await page.screenshot(path="screenshot.png")
await browser.close()
data = open("screenshot.png", "rb").read()
print("Screenshot of size %d bytes" % len(data))
return dataEntrypoint code
Let’s kick it off by reading a bunch of URLs from a txt file and scrape some of those.
@app.local_entrypoint()
def main(url: str = "https://modal.com"):
filename = pathlib.Path("/tmp/screenshots/screenshot.png")
data = screenshot.remote(url)
filename.parent.mkdir(exist_ok=True)
with open(filename, "wb") as f:
f.write(data)
print(f"wrote {len(data)} bytes to {filename}")And we’re done! Please also see our introductory guide for another example of a web scraper, with more in-depth logic.