WireGuard at Modal: Static IPs for serverless containers
At Modal, we built a high-availability, Go-based VPN proxy called vprox.
This is a deployment of WireGuard, so it operates on Layer 3 (IP) of the network stack and allows us to funnel outbound traffic from containers around the world through static IPv4 addresses. In the event of a single-node failure, its static IPs are associated with other proxy nodes, and containers reconnect within seconds.

This blog post is about the guts of our network infrastructure, which powers Static IP Proxies.
Scenario
The year is 2024, and you are deciding on a serverless cloud platform. You
stumble upon Modal. Run pip install modal, write a short Python function, and modal deploy it. Amazing, now you’ve got a cron job and API endpoint in the
cloud, within seconds.
import modal
app = modal.App()
@app.function(gpu="A100", schedule=modal.Period(days=1))
def my_modal_function():
print("Hello world!")
@app.function()
@modal.web_endpoint()
def my_web_endpoint():
return {"some": "json data"}Modal functions run on hardware around the world, in dozens of regions across multiple cloud providers. This is how we optimize the prices on your compute and scale dynamically to meet demand. It’s all to make developers happy, since now you don’t have to think about this stuff. (We get it, we’re infrastructure engineers.)
But now let’s say you want to connect your serverless function to your MongoDB cloud database, and it requires a specific IP access list. Uh oh…
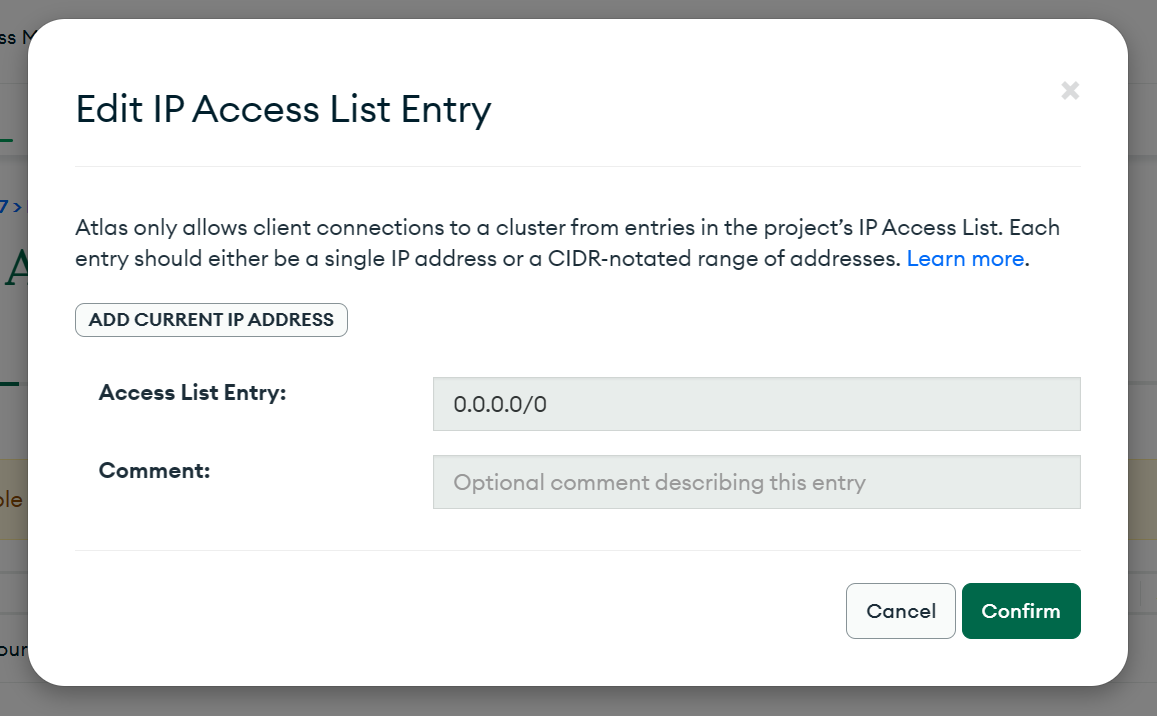
Usually, with a traditional provider you’d deploy some VMs and assign them a
static IP address or two, then distribute them across your machines and add
those to your access list. So now your application runs on cloud hosts at some
particular IPs, like 20.21.20.21. Only these machines can access your MongoDB
database, and no one else can around the world.
But if you’re running a serverless computing workload, which can not only run in any data center around the world, but also scale up and down… you won’t know what IP address your code is running on! So that access list would have thousands of entries and will be constantly changing, which really isn’t going to cut it.
Plus, Modal has an isolated container runtime that lets us share each host’s CPU and memory between workloads. If a host has one IP, your container and another customer’s container on that host would have the same IP, so that bypasses the security of your access list.
Okay but I want to access my database from Modal
So you need a static outbound IP address. Is that possible? Let’s break it down. IP addresses act as identifiers for sending and receiving internet data. When two different containers communicate with a web service like Google, each has a unique source IP. This allows Google’s server to reply directly to the correct container.

In this standard setup, the outbound IP address is tightly coupled to the container. How can you decouple static IP addresses from the actual compute resources? There’s a solution for this: You use a proxy.
We started by adding SOCKS5 proxies to
Modal. SOCKS5 is an unsung hero of the Internet proxy world; it’s a technology
from 1996 (RFC 1928) that lets
you send a request through another computer. SOCKS5 is secretly built into a
lot of software like OpenSSH, if you pass in the obscure -D flag that enables
the feature. But SOCKS5 doesn’t work out-of-the-box. You need to edit your
application to use an esoteric network shim.
If you wanted containers running your function to use a SOCKS5-based Modal Proxy, we would define one for your workspace. Once the Proxy object is created, you can use it like so:
import socket
import psycopg2
import socks
@app.function(
proxy=modal.Proxy.from_name("postgres-prod"),
secret=modal.Secret.from_name("postgres-prod-credentials"),
)
def get_user_count() -> int:
# SOCKS5 Proxy object is configured to listen on localhost:13432.
socks.set_default_proxy(socks.SOCKS5, "localhost", 13432)
# Patch the standard library socket class with the SOCKS proxy socket.
socket.socket = socks.socksocket
connection = psycopg2.connect(
dbname=os.getenv("DB_NAME"),
user=os.getenv("DB_USER"),
password=os.getenv("DB_PASSWORD"),
host=os.getenv("DB_HOST"),
port=os.getenv("DB_PORT"),
)
cursor = connection.cursor()
cursor.execute("SELECT COUNT(*) FROM users;")
user_count: int = cursor.fetchone()[0]
return user_countNow other functions can call get_user_count() remotely as a serverless
invocation. The proxy is only spun up within the get_user_count() function.
@app.function(schedule=modal.Cron("2 0 * * *")) # runs at 2 AM
def daily_schedule() -> None:
num_users = get_user_count.remote()
print(f"you currently have {num_users} users, posting to Slack...")
# ...Slick! But this is brittle. Replacing the standard library’s socket.socket object doesn’t work for libraries that don’t use socket directly. And many
common libraries don’t, such as asyncpg, datadog, aiohttp, httpx, or grpcio.
The broader issue is that the API is not obvious. It passes on the complexity to the user, who needs to figure out how to wire up the SOCKS5 proxy to their libraries. Modal is a cloud provider, and our philosophy on developer experience is that things “just work” — we should implement features that are correct and efficient by design.
So we stepped down a layer. Since we own the entire runtime, how can we configure networking so that all outbound Internet access goes through that IP? You should be able to just send a simple request to ifconfig.me and get back your proxy’s IP, for instance.
Enter WireGuard
At Layer 3, the Internet Protocol, all traffic looks the same—whether it’s Wikipedia, YouTube, or MongoDB. It’s just MTU-sized packets, usually a few kilobytes each, traveling through routers to their destinations. To ensure a consistent source IP address for outbound internet traffic across multiple containers, we can route all container traffic through a VPN. A VPN not only encrypts traffic but also can mask its source IP address, achieving the desired consistency.
WireGuard is a really simple VPN, and it’s included in the mainline Linux kernel. So we just have to bootstrap a WireGuard network between the proxy server and Modal workers (machines that run containers), configure traffic routing, and we’re all set!

To set up the actual WireGuard network, we start an HTTPS listener on port 443 of the WireGuard server. This binds to the public IP of the proxy node, and it takes “connect” POST requests to set up connections to the WireGuard network. We can rely on the security of TLS to handle VPN key distribution.
When a POST request is received with the client’s public key, the server
validates the credentials of the client, then allocates an IP in the subnet and
adds it as a peer at that IP. The server also has a loop that removes idle peers
after a few minutes of not receiving WireGuard handshakes. We use the wgctrl library for this, which
provides Go bindings for the WireGuard API, including access to the LastHandshakeTime property of each peer.
var removePeers []wgtypes.PeerConfig
var removeIps []netip.Addr
for _, peer := range device.Peers {
var idle bool
if peer.LastHandshakeTime.IsZero() {
_, isNew := srv.newPeers[peer.PublicKey]
idle = !isNew
} else {
idle = time.Since(peer.LastHandshakeTime) > PeerIdleTimeout
}
if idle {
if len(peer.AllowedIPs) > 0 {
ipv4 := peer.AllowedIPs[0].IP.To4()
if ipv4 != nil {
log.Printf("[%v] removing idle peer at %v: %v",
srv.BindAddr, ipv4, peer.PublicKey)
removeIps = append(removeIps, netip.AddrFrom4([4]byte(ipv4)))
}
}
removePeers = append(removePeers, wgtypes.PeerConfig{
PublicKey: peer.PublicKey,
Remove: true,
})
}
}
if len(removePeers) > 0 {
err := srv.WgClient.ConfigureDevice(srv.Ifname(), wgtypes.Config{Peers: removePeers})
if err != nil {
return err
}
for _, ip := range removeIps {
srv.ipAllocator.Free(ip)
}
}On the client side, we periodically probe the WireGuard VPN connection every few
seconds. This is implemented by the CheckConnection function below. If the
pings fail, the client assumes that the connection is dead, and it then begins
trying to reconnect to the server and recover by sending a new “connect” POST
request.
func (c *Client) CheckConnection(timeout time.Duration, cancelCtx context.Context) bool {
pinger, err := probing.NewPinger(c.wgCidr.Masked().Addr().Next().String())
if err != nil {
log.Printf("error creating pinger: %v", err)
return false
}
pinger.Timeout = timeout
pinger.Count = 3
pinger.Interval = 10 * time.Millisecond // Send approximately all at once
err = pinger.RunWithContext(cancelCtx) // Blocks until finished.
if err != nil {
log.Printf("error running pinger: %v", err)
return false
}
stats := pinger.Statistics()
if stats.PacketsRecv > 0 && stats.PacketsRecv < stats.PacketsSent {
log.Printf("warning: %v of %v packets in ping were dropped", stats.PacketsSent-stats.PacketsRecv, stats.PacketsSent)
}
return stats.PacketsRecv > 0
}This behavior is implemented in our open-source Go package vprox, which we’ll talk about more at the end of this blog post.
Policy-based routing on container traffic
There’s still a missing piece to the puzzle: Modal workers are multi-tenant. We run gVisor sandboxes from multiple functions on the same host, which is what lets us provide a serverless compute product with flexible pricing.
How does container networking work? Well, very briefly:
- Each worker machine runs multiple containers, and each container gets its own network namespace.
- Inside the network namespace, the container has a veth (virtual Ethernet) interface. This acts as a virtual network card, similar to the WiFi card on your laptop.
- Veth’s come in pairs. The other half of the veth lives on a bridge device (like a switch).
- When containers send outbound packets to the Internet, they pass through the veth and arrive at the bridge, where the host Linux kernel is configured to masquerade each packet’s source IP address before exiting the machine.
If you didn’t get all that, it’s fine! The important part is the last step, IP masquerade. This is a form of network address translation, or SNAT. It’s just like how your home router uses SNAT to make all devices in your house have the same public IP address. Each cloud host at Modal uses SNAT so containers running on that host appear to the outside world to have the host’s public IP.

This is the classic container networking setup. To introduce WireGuard, we need to tell traffic from one container to go to a designated WireGuard interface without affecting its neighbors. This requires an update to the kernel’s routing table. When a container sends a packet to the outside world, we should inspect the packet’s source IP and redirect it to the proper VPN interface based on the container’s metadata.
But people familiar with Linux might see a problem here: the iproute2 system in Linux doesn’t
actually let you put down routing table entries by source IP! In Linux, routing
tables are based on CIDR blocks of
destination IPs. So you can route packets to 142.251.40.174 (google.com)
from all containers, but you can’t tell packets from a specific container to
go through a VPN.
There’s a solution, but it means we need to sin a bit. We’re going to write some policy-based routing rules. 🫢
# Update routing policy to match packets from 10.11.12.13 to "table 101"
ip rule add from 10.11.12.13 lookup 101
# Add a default route for "table 101"
ip route add default dev wg1 table 101Policy-based routing works by switching between multiple routing tables. The routing tables in Linux are numbered from 1 to 2^31. So we can assign a routing table to each container that requests a proxy, allocating indices to avoid repeats, then edit the policy database so that traffic from that container goes through the routing table.

We really didn’t want to do this, it’s tricky! For example, what happens if two containers start up at the same time? They need to synchronize and decide which one gets the next numbered routing table. And if a container crashes early, it adds another kernel resource to clean up. Dynamically configuring the policy database was not our first choice of solution.
(Technical detail: As an alternative approach, we tried doing it in eBPF first
with xdp_redirect() in our packet
filter attached to the container bridge device. But this didn’t work. It was
incompatible with SNAT because eBPF skips the Linux netfilter stack.)
Luckily, our runtime is pretty resilient to unexpected crashes (it’s written in safe Rust, with testing, monitoring and conscious async-oriented design), and overall we haven’t run into any reliability issues with our implementation so far.
That concludes our worker-side implementation of the proxy! Now, back to the server…
So you have a proxy server running for every IP?
We did initially! But starting one cloud VM for every proxy server is pretty expensive, and it’s not very efficient on resource utilization. The entire point of serverless is shared tenancy, after all. To make this faster and more reliable, we started assigning multiple IPs to each proxy server, so that one unit of shared hardware could manage all of these associations.
Each vprox server node has one or more IPs living on one or more network
interfaces. For example, on AWS, the latest c7gn.8xlarge instance type ($2.00
/ hr) with 100 Gigabit networking can have up to 8 network interfaces, with 30
IPv4 addresses per interface. This is a pretty good deal — at full packing of
240 IPs, each costs less than $0.01 / hr while also allowing for individual
proxies to burst up to 100 Gbps of shared bandwidth.
To avoid contention and control the bandwidth used by different IP proxies on the same server, we can use the tc traffic shaping system in Linux.
Juggling IPs between servers
We didn’t just stop there though. We wrote some code that hits the cloud
instance metadata endpoint and detects within a couple seconds if you made any
changes to the IP addresses associated with the instance. If you did, vprox automatically reconfigures itself to reallocate blocks of WireGuard IPs, move
around connections, bootstrap WireGuard interfaces, and start accepting
connections from clients to the new IP address.
This may seem like overengineering, but it reduces the amount of configuration
for vprox and makes the server significantly more flexible. Plus, it’s
fault-tolerant by design! Reconciliation loops are the
hidden heroes of distributed systems, as we all know.
When enabled, the network proxy is on the hot path of every request from a serverless function, so high availability is crucial. You wouldn’t want your API to start failing because you can’t connect to MongoDB anymore due to the one proxy instance going down! So we implemented another reconciliation loop, globally, that creates many servers and juggles the IPs around in event of a termination.

This can happen if the compute instance becomes unhealthy or needs to be taken
down for maintenance for any reason. The vprox client is also designed to
detect network partitions by periodically sending pings, and when it detects
that it has disconnected, we can automatically recover the connection to the new
server in under 10 seconds.
Since IP is an inherently unreliable and unordered protocol, you’ll probably never even notice if your proxy goes down! Even if you’re running an HTTP request at that exact moment, it will just result in a few dropped packets, which are automatically retried at the TCP layer. No database errors for you — a perfect recovery.
What is rp_filter anyway?
(We’re going to get into sysctl here. Sysctl is a way to configure attributes of the Linux kernel. Think of it like an OS-wide configuration file.)
When testing vprox on different distributions of Linux, we ran into a problem
that we had to debug. Specifically, it was tested to be working on Ubuntu 24.04,
but it didn’t seem to be working on Oracle Linux 9. What happened? WireGuard is
part of the kernel, and iptables / iproute2 are supported by both distributions,
so this should be cross-platform.
The issue turned out to be caused by a feature called reverse path filtering.
Basically, the sysctl net.ipv4.conf.all.rp_filter controls whether IP packets received on an interface are dropped. If strict
filtering is set, Linux will drop packets whose source address doesn’t appear to
match the path in the routing table that would otherwise be used to send packets
to that destination.
Since we’re sending packets to all kinds of public Internet sources through these WireGuard interfaces, when they return on the interface, the kernel isn’t happy about their source IP and drops them. It detects that a more “direct” path would be to go through the default interface on the host instead. We need to relax rp_filter.
Curiously, when we disabled the rp_filter setting by setting it to 0, vprox didn’t work. We had to explicitly set it to 2, which is “loose mode” that checks the incoming packet against the kernel’s FIB (forwarding information bus).
sysctl -w net.ipv4.conf.all.rp_filter=2Honestly, I don’t know why vprox only works when reverse path filtering is in loose mode and not when it is disabled. But we switched the value of the sysctl, and now it works reliably across Linux distributions.
Using vprox
If you’re a developer on Modal, you can get access to our static IP proxies feature on the Team plan. Just create a proxy and voilà, you’ve got an outbound IP. No SOCKS5 required!
import modal
import subprocess
app = modal.App()
@app.function(proxy=modal.Proxy.from_name("my-static-ip-proxy"))
def my_proxy_function():
subprocess.run("curl ifconfig.me", shell=True) # => "20.21.20.21"Right now each Proxy corresponds to a single static IP address, but we’re planning to extend this to region-specific proxies where your container may automatically select an IP from the nearest geographic location to minimize latency.
But this blog post is about the internals, and as mentioned before, we open-sourced our control plane — how we run WireGuard in production and integrate it into the Modal serverless function runtime. You can find this in the modal-labs/vprox repository on GitHub. With just a couple commands, you can run a VPN server and any number of clients. All aspects of the networking are configurable.
A nice thing about this implementation is IP discovery. On AWS, we periodically
poll the instance metadata endpoint to find the IPs attached, so you don’t have
to update this manually. Just run vprox server --cloud aws and watch the magic
happen. (It should be easy to port this code to other cloud providers, but we’ve
only tried deploying on AWS ourselves.)
We’re excited to see how you use static IPs at Modal! This project has been fun for many of us. I’m grateful to my coworker Luis Capelo for deploying vprox in production, and to our intern Jeffrey Meng for implementing IP discovery and client reconnection.
If you’re interested in crafting reliable, secure systems at scale for the next generation of cloud infrastructure, we’re hiring at Modal.