How we used evals and inference-time compute scaling to generate beautiful QR codes that actually work
Two techniques dominate discussion of the engineering of language model applications and artificial intelligence: evals and inference-time compute scaling. These techniques are general, far beyond topics du jour like RAG chatbots and code completion and AI boyfriends. In fact, they are fundamental to any application of foundation generative models.
In this blog post, we’ll walk through how we used evals and inference-time scaling to improve the quality for our implementation of one of the first viral applications of image generation models: encoding QR data inside a generated image (aka QArt codes).
Here are some samples from our system, without any per-prompt cherry-picking:




We were able to
- boost QR code scan rate to our service-level objective of ninety-five percent
- while improving aesthetic quality
- and returning codes to users in under 20s, p95.
We use codes like these in all the places we might use QR codes — like guerrilla marketing and credit giveaways.
You can try the system for yourself at https://qart.codes, check out the code here, or read on for more about how we did it — and learn some ideas for engineering your own generative model applications.
Generative models always start with a cool demo, like QR codes that look beautiful.
The same basic story has played itself out over and over again in this early era of “generative AI”. A new foundation model or technique for some domain trends on social media and there’s a gold rush as a million hackers simultaneously build zero-to-one proofs of concept in a day. Whether it’s making pictures of cats or booking a flight, it works well enough to cut a demo video and maybe snag some of the least intelligent VC money.
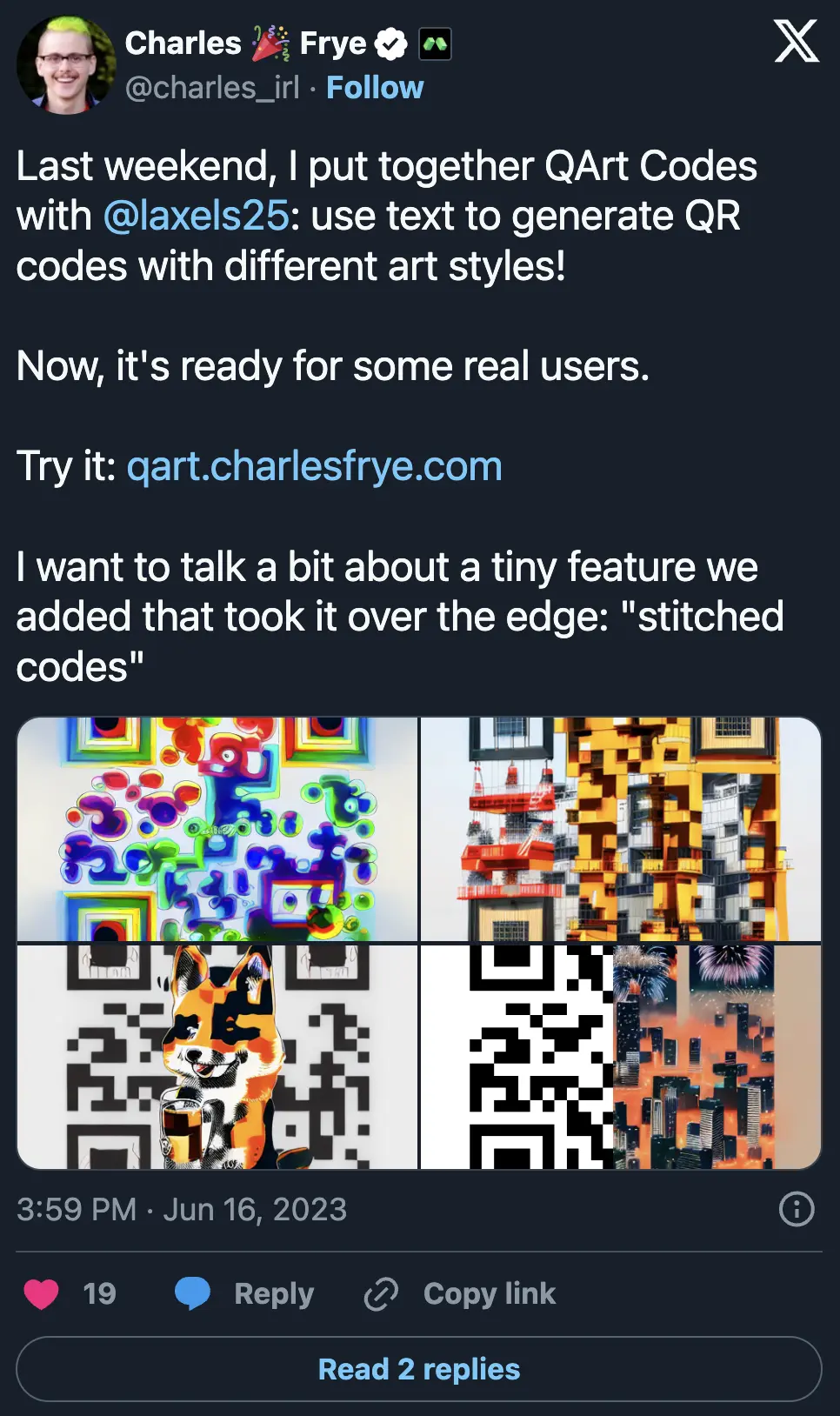
One of the first instances of this pattern kicked off on June 5, 2023, when Reddit user nhciao posted “ControlNet for QR Code” on the Stable Diffusion subreddit, demonstrating that diffusion models with ControlNet steering could create images that were also QR codes.

ControlNets add the ability to “control” the images made by diffusion models like Stable Diffusion or Flux using some other image. You might, for instance, use this simple line drawing of a turtle to control pose and position and size — all generations match the line drawing on those factors. This can be much more expressive than prompting! “The turtle is looking up and to the left with a look of resignation on its face, taking up the bottom two-thirds of the image…”
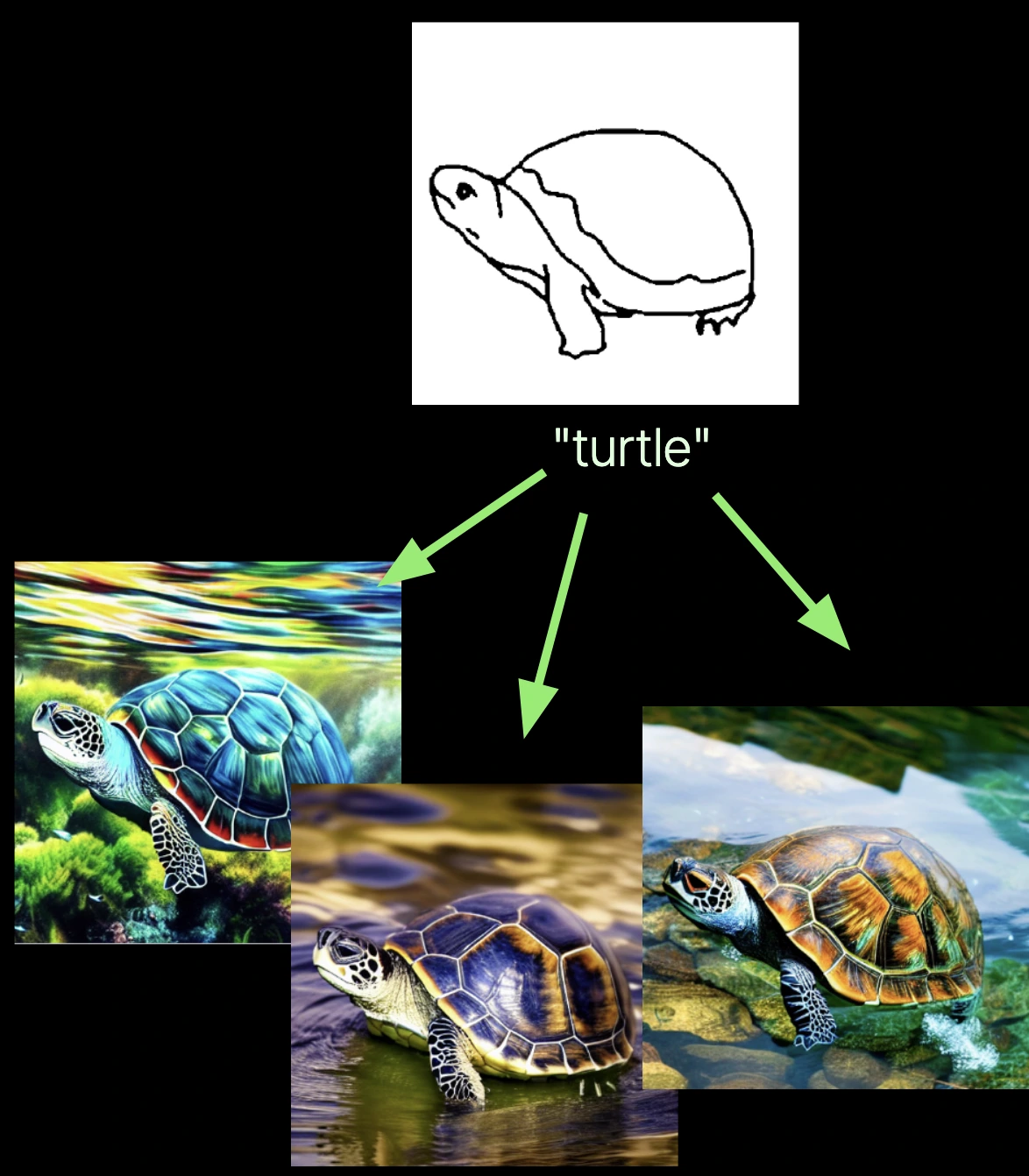
Separately, QR (Quick Response) codes are designed to transmit short snippets of information between machines, just like other protocols you may be more familiar with (HTTP/IP/Ethernet). But they transmit via a chaotic and unpredictable medium: bright and dark patches of color that modulate light in open air, at human scales, and without the protective shielding of a fiber optic cable. And because QR code readers have to be robust to interference in that medium, like the piece of paper they are printed on being torn, the QR code protocol comes with sophisticated error correction.
{kind=link}
The insight from nhciao was that ControlNets based on brightness patterns or edges, like the one demonstrated above, could be used to produce images with the brightness and darkness patterns of a QR code. And thanks to the error correction, the model can exercise a bit of creative license and “corrupt” the pattern to better match the prompt while still communicating the encoded message.
Like many others, some of us jumped on these “QArt codes” immediately — all the way back in the summer of 2023.
Then comes the disappointment, like QR codes that don’t scan.
So much for the party, now for the hangover. The problem that came next, and the reason you haven’t seen gorgeous QR codes replace the standard black-and-white squares, was the same problem that bedevils demos of coding agents and artificial lawyers and self-driving cars — “it worked on my machine prompt”. It’s hard to consistently create QR codes that are both gorgeous and scannable!
Consider, for instance, the image below, which we generated using a web app created by nhciao. This image may look a bit like a QR code, especially if you squint, but we haven’t been able to get it to scan. The model’s attempt to build the required Finder Pattern (concentric squares of alternating black and white) in the bottom-left out of a dark skyscraper and some reflections appears to have failed.
 Not quite a QR code!
Not quite a QR code!This is a show-stopping bug. A putative QR code that readers can’t scan isn’t a QR code, it’s just a picture with a weird aesthetic. Similarly, failures for coding agents that neglect to implement features or chatbots that offer off-policy refunds limit their applicability.
So in building the initial version of qart.codes, we focused first and foremost on this problem — “scannability”.
The result was a system that produced scannable QR codes with a reasonable probability (as in, it didn’t make us want to tear our hair out), so long as we only prompted with textures or styles, like “computer circuitry, splashes of color in gunmetal gray”, and not with complex scenes, like “a patient orangutan explains string theory to an anime waifu”.
We started using it in a few places where we were previously using QR codes — and even in places where we weren’t using QR codes previously because they’d ruin the vibe.
 A QArt code in the slides for a talk by one of the authors.
A QArt code in the slides for a talk by one of the authors.With some creativity and effort on post-processing, you could even achieve some pretty cool effects!
 A QArt code created by superimposing an image (the logo for Lovers in a Dangerous Spacetime) over a generated QArt code.
A QArt code created by superimposing an image (the logo for Lovers in a Dangerous Spacetime) over a generated QArt code.But it was far from the promise of the original demo.
We solved this quality gap by developing good evals, following the standard ML engineering playbook: collect human judgments, align to them, then scale.
The problem here is the problem of evaluation — determining the value or quality of the system. In traditional software, most evaluation can be done objectively. It can even be done “rationally” (as opposed to empirically). That is, you only need a single demonstration or logical argument for correctness or incorrectness. Think of simple repros and compiler guarantees.
But neural networks are less like the digital computers we are used to programming and more like analog computers. They are a sloppy heap of floating point numbers, not an elegant stack of integers. Correctness and quality are measured and defined for a specific use case and up to a tolerance — if they are measured and defined at all!
The tools we use to assess quality for these systems are called evals. They combine a procedure for producing inputs (which might just be a database or files!) with a procedure for evaluating outputs (which might be human labelers or might be a computer program). To engineer these procedures, you need to understand the goals of your system.
Our system has two core goals:
- produce an image that a QR reader can scan
- produce an aesthetically appealing image.
One servant cannot serve two masters, so we needed to determine how to trade off between these goals.
Aesthetic quality is
- primarily the domain of the underlying foundation models,
- highly subjective and so variable across users, and
- difficult to measure well.
Scanning, on the other hand, is
- firmly in our application domain and maps onto correctness,
- has minimal variability across users, and
- easy to measure objectively.
So we decided to make scan rate the key target for eval development.
Next, the goals need to be operationalized, mapped onto concrete processes and measurements.
We first operationalized our two goals as “can be scanned by a human wielding an iPhone pointed at a screen in our office” and “gets a thumbs up from the prompter”.
These both involve a lot of human labor, so we next came up with automated processes to replace them. We found the QReader library for QR code scanning, which uses a YOLO model to detect QR codes and then applies a number of transformations, like blurring and thresholding, before attempting to interpret the image as a code. We also found a simple aesthetic rating predictor from the Stable Diffusion community — a quick-and-dirty machine learning model that could predict human aesthetic ratings.
But those systems are also heuristic and might themselves make mistakes we can’t predict. So we needed to be sure they were aligned with our trusted human process, and we couldn’t just rely on tests and logic. We needed to run experiments to know that they were good.
We needed evals for our evals.
We built our evals iteratively. We vibe-checked them manually at first and then with results on 100 prompt-URL pairs (first image below). Finally, we scaled up our alignment check for our evals to results on about two thousand prompt-URL pairs.
That meant we needed to attempt to scan thousands of QR codes by hand while writing down the results and our aesthetic judgment. Sometimes, as an engineer, you’ve just go to roll your sleeves up and do some manual labor. Major props to Will Shainin on the team for taking the plunge (it’s always the mechanical/electrical engineers, not the PhDs).

As you can see, the “apparatus” here can be pretty low-tech and low-effort. Tools of the trade include post-it notes, whiteboards, spreadsheets, and Jupyter notebooks — in roughly that order! Sticking to simple techniques keeps the focus where it belongs: on the data and the problem.
One piece where we did find it helpful to use an external tool was experiment management and data visualization, which crosses from ML software to data visualization to team coordination.
We used Weights & Biases’ Weave for this, since one of our team members had some experience with it (conflict of interest note: he is now fully divested). We were able to log raw data from our experiments to wandb and then construct structured charts and analyses on the fly, all shareable across the team.
FYI: while the details of the approach for this project are idiosyncratic, the approach itself is not at all! See, for instance, Hamel Husain’s blog post “Creating a LLM-as-a-Judge That Drives Business Results”.
The final piece (not the first) is scaling up offline compute to select system parameters.
Putting it all together, our final engineering goal was to
- achieve a ninety-five percent scan rate, as measured by QReader, and
- not regress on aesthetic quality, as measured by the aesthetic rating predictor
on a set of prompts and URLs.
We manually iterated on code, checking evals ad hoc as we went, until we’d narrowed down the outlines of our system. We developed new prompting strategies, confirmed our model choice, and determined which parameters we needed to vary and over which ranges (tl;dr - long prompts, stick with SD1.5 for now, and focus on ControlNet start time).
This part is still pretty vibes-based, and it’s where the great ML engineers, the ones who can 10x a project and avoid a million dollar training run, are separated from the merely good.
 Yeah man, we need the guidance to come in on the track a bit earlier — and can somebody turn down the diffusion noise?
Yeah man, we need the guidance to come in on the track a bit earlier — and can somebody turn down the diffusion noise?Once we were ready to sweep over key configuration parameters, it was time to scale up. Thanks to our trusty evals, we didn’t need ten engineer-seconds per image anymore, just a computer-second or two. So we could scale this up into the tens of thousands of images and calculate our figures of merit in minutes. (BTW Modal’s serverless platform makes this trivial, just a few lines of code).
But even though we had built an eval system we trusted, we wanted to continue to look at the data to check whether our evals still aligned with our heuristic judgments.
For this, we developed a visualization we called the “toast plot”, after a famous bit of Internet culture.
 POV: you are an ML engineer making breakfast.
POV: you are an ML engineer making breakfast.Two parameters of interest vary along two axes — how long is the bread cooked for & at what temperature; how long is the ControlNet guidance in place & at what strength. The results for a single case are below.
 An instance of the “toast plot” for one prompt.
An instance of the “toast plot” for one prompt.We selected the configuration one row and one column from the top-left corner, which produced images that had much better aesthetics than the existing system.
But it didn’t hit our objective of ninety-five percent scan rate — in fact, it actually had a lower scan rate than our existing systems.
But we hadn’t given up on our goals. We just used another technique: inference-time compute scaling.
Our evals were good enough to move them to production — so we could solve all of our problems by scaling compute!
Let’s step back for a second. Our evals are how we measure our system’s performance offline. We automated them, so now they are fast. Why not run our evals in production so that we can improve our system’s performance online?
The easiest move is to create multiple outputs in parallel and then compute evaluation metrics on all of them. These can either be used on the backend (e.g. to retry) or delivered to the frontend. We chose the latter. Our frontend then ranks the QR codes — first by whether they scan, then by their aesthetic score — and selects the top four for display.
Scaling up parallel generations maps rather nicely onto the hardware used for inference: GPUs. The one thing every engineer needs to know about GPUs is that they are designed to achieve high throughput through massive concurrency and parallelism.
Producing multiple images for a single prompt exposes more parallelism for the GPU to exploit. In this case, we get exponential improvement in scan probability (p^n) for sublinear latency cost. That’s what engineers call “a big win”. For a walkthrough of this same basic idea applied to LLMs, see our blog post on the “Large Language Monkeys” paper.
The usual blocker is that even once automated, the evals are too slow to run in production. Even though our evals do require running neural networks, these networks are much lighter weight than the generator itself and so contribute far less to latency.
By creating eight generations per request, we were able to hit our ninety-five percent scan rate SLO (measured per batch) while staying within an acceptable latency (at time of writing, under 20s p95 end-to-end) while improving aesthetic quality (just look at them!).




You can try the service for yourself by clicking this link: https://qart.codes — or just scan one of the codes above.
If you’d like to go “beyond the demo” and build robust applications of generative models, try Modal.
The present of generative models and artificial intelligence is hype and vaporware that promises the stars but is at best just a start.
We expect this technology’s future, and perhaps a noticeable percentage of the future world economy, to look rather different: taking hard problems and constructing automated evaluations for them. Building hills for engineers and their machines to climb. For more on this vision, see the work of Andon Labs, who partnered with Anthropic on Claude Vend.
If you’re interested in building that future, we think Modal, the serverless platform we are building and which we used to do this work, is a great tool. It provides high-performance, flexible compute that can scale up your evals and your inference with a Python SDK loved by ML researchers and production engineers alike. Check out our marketing site for details.
The authors would like to thank u/nhciao for sharing the initial QArt codes work, Illyasviel and monster-labs for training useful ControlNets for QArt code generation, and Axel Setyanto & Teddy Frye for work on the frontend.
We’d also like to thank the following reviewers: Colin Weld & Peyton Walters of Modal and Hamel Husain (the evals guy).