Top image segmentation models
Image segmentation is a fundamental task in computer vision that involves partitioning an image into multiple segments or objects. This process allows machines to understand and analyze the content of images at a pixel level, enabling a wide range of applications from medical imaging to autonomous driving.
What is image segmentation?

Image segmentation is the process of dividing an image into multiple parts or regions, each of which corresponds to a different object or area of interest. The goal is to simplify the representation of an image into something more meaningful and easier to analyze.
For example, in a photo of a street scene, image segmentation might identify and separate areas corresponding to buildings, cars, pedestrians, and the road itself. Each of these segments can then be analyzed independently, allowing for more detailed and accurate image understanding.
What is mask generation?
Mask generation is a specific output of image segmentation where the result is a binary mask for each identified object or region. A mask is essentially a black and white image where white pixels correspond to the object of interest, and black pixels represent the background or other objects.
These masks provide a precise outline of each segmented object, allowing for detailed analysis of shape, size, and position within the image.
How do image segmentation and mask generation differ?
While closely related, image segmentation and mask generation have some key differences:
Output format: Image segmentation typically produces a labeled image where each pixel is assigned to a specific class or object. Mask generation, on the other hand, creates binary masks for each identified object.
Granularity: Image segmentation can be semantic (identifying broad categories) or instance-based (distinguishing individual objects within categories). Mask generation is usually associated with instance segmentation, providing a unique mask for each object instance.
Application: Image segmentation is often used for understanding the overall composition of an image, while mask generation is particularly useful for tasks that require precise object boundaries, such as image editing or medical image analysis.
Use cases for image segmentation and mask generation
Image segmentation and mask generation have numerous applications across various industries:
- Medical imaging: Identifying tumors, measuring organ volumes, or planning radiation therapy.
- Autonomous vehicles: Detecting road boundaries, other vehicles, pedestrians, and obstacles.
- Satellite imagery: Land use classification, urban planning, and environmental monitoring.
- Augmented reality: Separating foreground objects from backgrounds for realistic object placement.
- Industrial inspection: Detecting defects or anomalies in manufacturing processes.
- Face recognition: Isolating facial features for more accurate identification.
- Content-based image retrieval: Improving search accuracy by understanding image content.
Top image segmentation models
The top image segmentation/mask generation model that has emerged in the transformers era is Meta’s Segment Anything model:
SAM2 (Segment Anything Model 2)
SAM2, developed by Meta, is an evolution of the original SAM model. Key features include:
- Ability to segment both images and videos
- Requires input in the form of bounding boxes or points to guide segmentation
- Improved efficiency and accuracy over the original SAM
SAM2 excels in tasks requiring flexible, user-guided segmentation. Its ability to work with minimal input makes it versatile for a wide range of applications.
You can try out SAM2 using Modal’s SAM2 example, which provides a simple interface to experiment with the model.
Language Segment-Anything
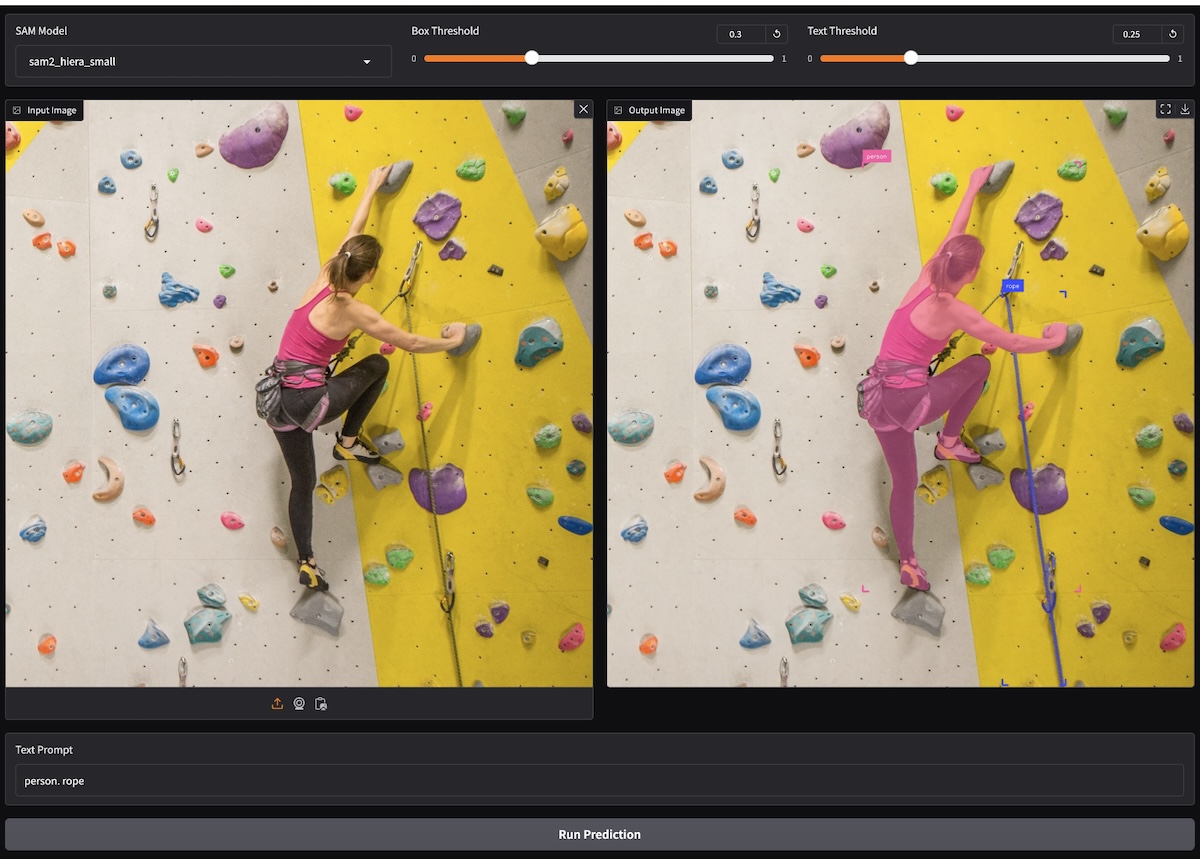
Language Segment-Anything is a modification of SAM2 that allows the use of language prompts for segmentation instead of bounding boxes.
This tool, built on Meta’s Segment Anything Model 2 and the GroundingDINO detection model, simplifies object detection and image segmentation. Key features include:
- Text prompts for segment description
- Integration of language models with image segmentation
- Intuitive and flexible segmentation capabilities
LangSAM is especially beneficial in contexts where users describe objects in natural language, such as image editing or content moderation systems.