How Doppel eliminated ML infrastructure tax with Modal
This is a guest post written by the team at Doppel.
Doppel is an AI-Native platform building machine learning systems to detect and disrupt social engineering attacks. The threat landscape changes constantly, which means our models need to evolve just as quickly.
That translates into two core requirements for our ML workloads:
- Fast experimentation
- Reliable and scalable inference
For a long time, infrastructure friction slowed us down in both places. Training experiments ran sequentially, inference deployments required heavy container pipelines, and small operational details accumulated across our stack.
We recently migrated a large portion of our ML workflows to Modal, and the result has been a significant shift in how quickly we can iterate.
Part 1: Training
As a cybersecurity company, Doppel needs to stay at the forefront of what threat actors are producing. This means that our ability to iterate on machine learning models is critical.
The biggest bottleneck in our training workflow used to be experimentation throughput, meaning how quickly we could test and evaluate new ideas.
Historically, our experimentation pipeline looked like this:
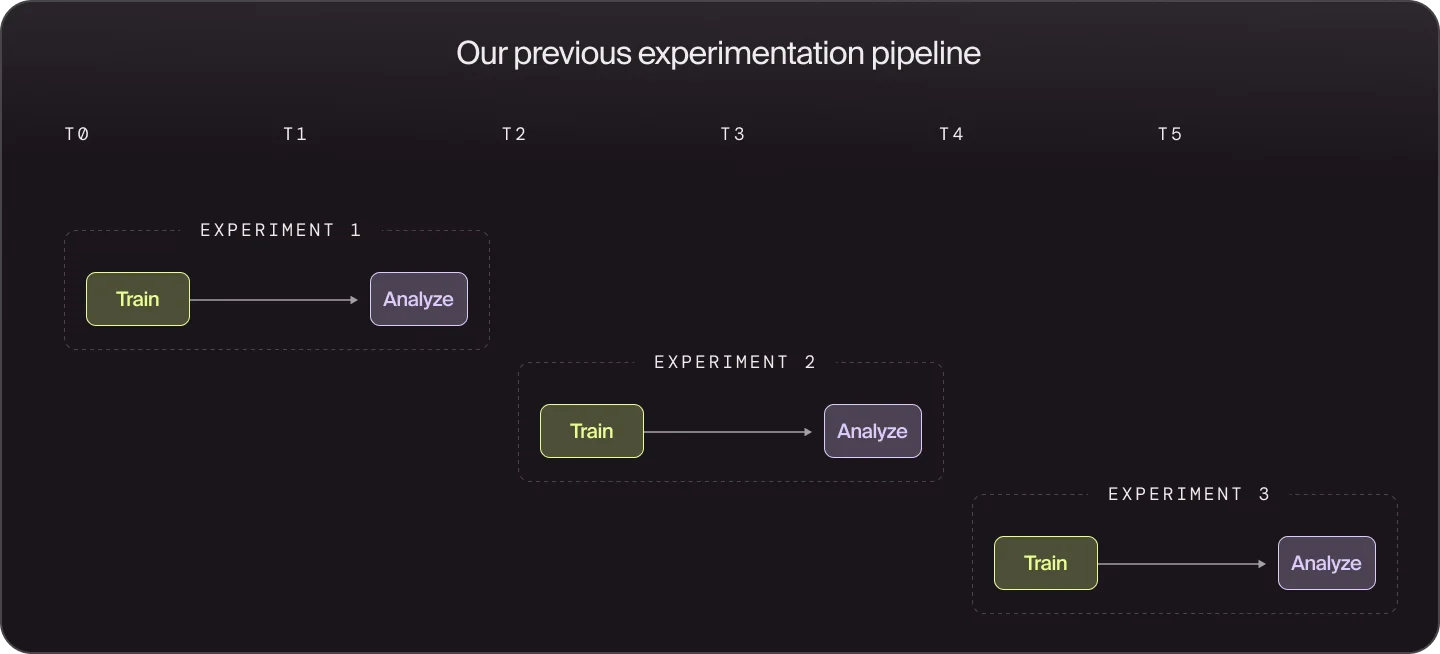
Experiments ran sequentially, which created several problems. Training jobs often ran for hours, so new hypotheses had to wait until the previous run finished. When something failed late in training or evaluation, the entire run was lost and the feedback loop restarted. Because each run was expensive, we frequently bundled multiple ideas into a single experiment to make it “worth it,” which made it harder to isolate which changes actually improved performance.
Parallelism with Modal
Modal makes it easy to run experiments in parallel without building additional orchestration infrastructure. Instead of managing job queues, worker pools, or distributed training pipelines, we can write normal Python code and parallelize work with simple constructs like map().
A good example is K-fold cross validation. Each fold is independent, so they can run concurrently rather than sequentially. In practice, parallel cross-validation looks like ordinary Python: define a fold-level training function, then map it across the folds.
@app.function()
def train_fold(fold):
train_idx, val_idx = fold
model.fit(X[train_idx], y[train_idx])
preds = model.predict_proba(X[val_idx])[:, 1]
return roc_auc_score(y[val_idx], preds)
folds = list(KFold(n_splits=5, shuffle=True, random_state=42).split(X))
results = list(train_fold.map(folds))
print("Mean AUC:", sum(results) / len(results))There’s no orchestration layer to manage. Whether we run one fold or ten, the code path stays the same. Modal handles the parallel execution behind the scenes.
This pattern shows up throughout our training workflows. Instead of waiting for experiments to run one at a time, we can evaluate many hypotheses simultaneously and shorten the feedback loop between ideas and results.
Coding agents improving the experimentation loop
Our training workflow follows a tight iteration cycle:
- Propose a change
- Run an experiment
- Summarize results
- Propose the next change based on evidence
This pattern has started to show up in several recent projects exploring autonomous ML experimentation. For example, Andrej Karpathy’s autoresearch project explores running a similar loop fully autonomously, where an agent modifies training code, runs short experiments, evaluates results, and proposes the next change.
Our approach is more human-directed. Agents handle the mechanical steps in the loop like launching experiments, collecting metrics, and summarizing outcomes. MLEs remain responsible for deciding what ideas are worth testing.
Modal fits naturally into this workflow because its CLI exposes everything agents need to interact with the training system. Agents can launch experiments, inspect logs, retrieve outputs, and trigger follow-up runs directly from the command line environment where they already operate.
Combined with Modal’s ability to parallelize workloads, this lets us evaluate far more ideas in the same amount of time. The bottleneck shifts away from infrastructure and toward what actually matters: deciding which experiments are worth running next.
Part 2: Inference
At Doppel, our models power real-time detection pipelines. Two properties are critical for this system to work effectively: low latency, so threats can be processed immediately, and elastic scalability, so infrastructure can absorb bursts during attack campaigns.
Attack traffic is inherently unpredictable. A model may sit idle for a period and then suddenly receive a surge of requests when a phishing campaign spins up. Our serving infrastructure needs to handle those spikes automatically.
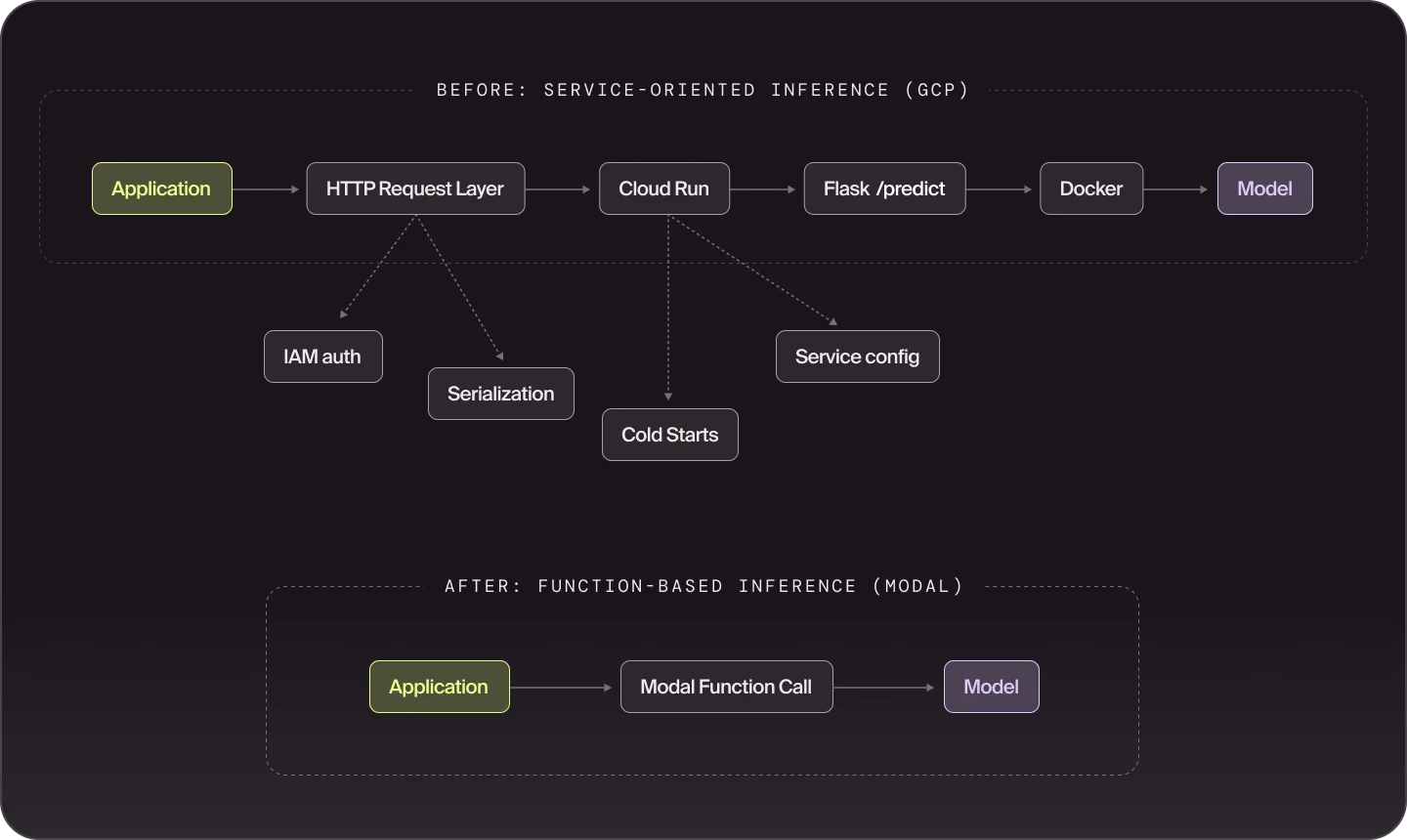
Our GCP inference stack
Like many teams already operating heavily in GCP, our first instinct was to deploy inference through their ecosystem.
When we were ready to deploy a new model, our workflow typically looked like this:
- Package the model inside a custom Docker container
- Deploy a Cloud Run service with a mounted GPU
- Expose a Flask /predict endpoint
- Integrate callers via HTTP requests
This setup integrated naturally with the rest of our platform, but it introduced several sources of operational friction.
Large model images often took 10–30 minutes to build, which meant even small configuration changes slowed down deployment and iteration. Cloud Run also imposed several constraints that became more noticeable as our workloads grew. Each Cloud Run instance can attach only a single GPU, which means scaling GPU inference typically requires horizontally scaling many single-GPU instances. Traffic spikes could also trigger cold starts or provisioning delays while new instances came online.
Finally, every model deployment required building an HTTP service layer around the Flask endpoint to handle authentication, serialization, and request routing. Individually, these pieces were small, but the repeated integration code added up and slowed down progress.
Where Modal jumped in
Modal simplified several parts of this workflow.
Build and deployment cycles became much faster. Image layer caching and persistent volumes for model weights dramatically reduced build times by up to 10x, with even our more complex model setups reaching sub-minute warm builds. This makes it far easier to iterate on deployment configurations.
Scaling behavior also became simpler. Modal automatically scales inference workloads via its serverless architecture in response to demand, allowing the system to absorb traffic spikes when new campaigns appear.
import modal
cls = modal.Cls.from_name("phishing-detection", "PhishingDetector")
detector = cls()
def detect_phishing(image_bytes: bytes) -> dict:
return detector.predict.remote(image_bytes)Modal also removes the HTTP service layer we previously built around each model. Instead of exposing a Flask endpoint and calling it through HTTP, inference functions can be invoked directly through Modal’s abstractions.
The result is a simpler deployment flow and significantly less integration code to maintain.
Conclusion
Across both training and inference, the biggest change Modal introduced for our ML workflows was reducing the operational costs around our models.
For training, that meant turning experiments that previously ran sequentially into workloads that can execute in parallel. For inference, it meant removing much of the manual overhead required to package, deploy, and scale model services.
None of these capabilities are impossible to build on traditional cloud infrastructure. But for a small ML team focused on shipping detection models quickly, Modal makes it easy and obvious to build scalable architectures.
As a result, the limiting factor in our workflow is no longer infrastructure. It is simply how quickly we can generate and evaluate the next idea.