GPU Memory Snapshots: Supercharging sub-second startup
At Modal, we’re obsessed with cold start latency. Earlier this year, we introduced memory snapshots to slash startup times by more than half. Today, we’re thrilled to announce the next evolution: GPU memory snapshots—bringing the same checkpoint/restore magic to GPU-accelerated workloads.
Eliminating cold boot bottlenecks
Since our inception, we have been attacking the cold boot problem from three angles:
- Custom file system optimized for cold boots
- CPU memory snapshots
- GPU memory snapshots
Our distributed file system uses a series of caches to store, directly in the worker memory, the most popular files used across Modal users. This is great because, for example, if torch is imported in one program, another program benefits because the torch files are now in the worker cache. This has a substantial impact in performance, usually 3-5x faster than when downloading files without a cache.
The lifecycle of a Modal Function involves a few stages: container cold boot and running inputs. Cold boot most commonly means two things: downloading your program files and reading your program into memory.
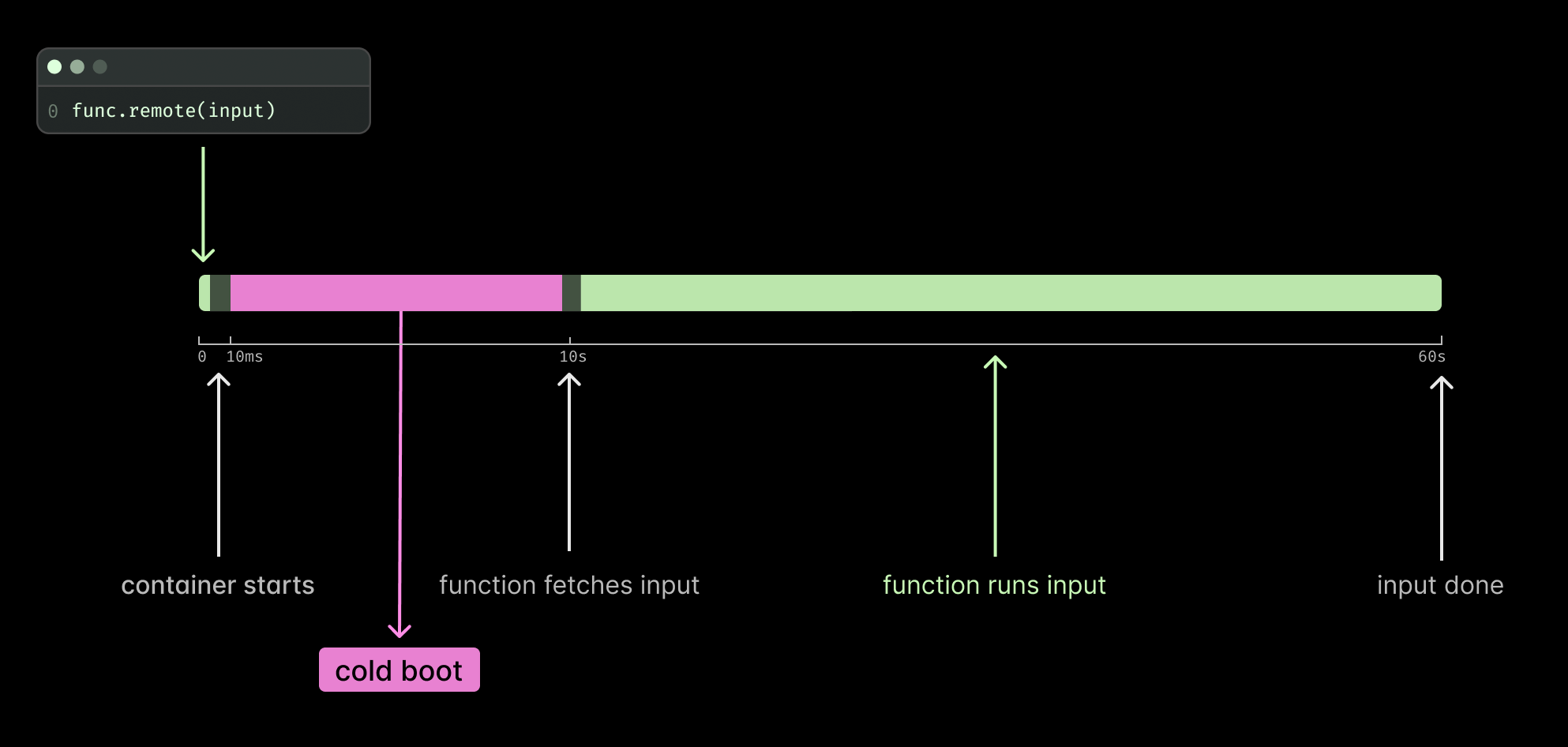
Reading a program into memory and starting up a Function takes time—sometimes a lot of time! What if we could take the memory representation of your program and save it into an image? That could save time by skipping reading files and re-creating your program in memory on every cold boot.
It turns out that re-creating your program from an image was indeed faster, hence, we introduced memory snapshots in January 2025. We create a memory snapshot from your Function just before it calls for inputs. Your Function is then “frozen”, saved as an optimized format, and cached in our distributed file system. Every time your program cold boots the program starts from this frozen state.
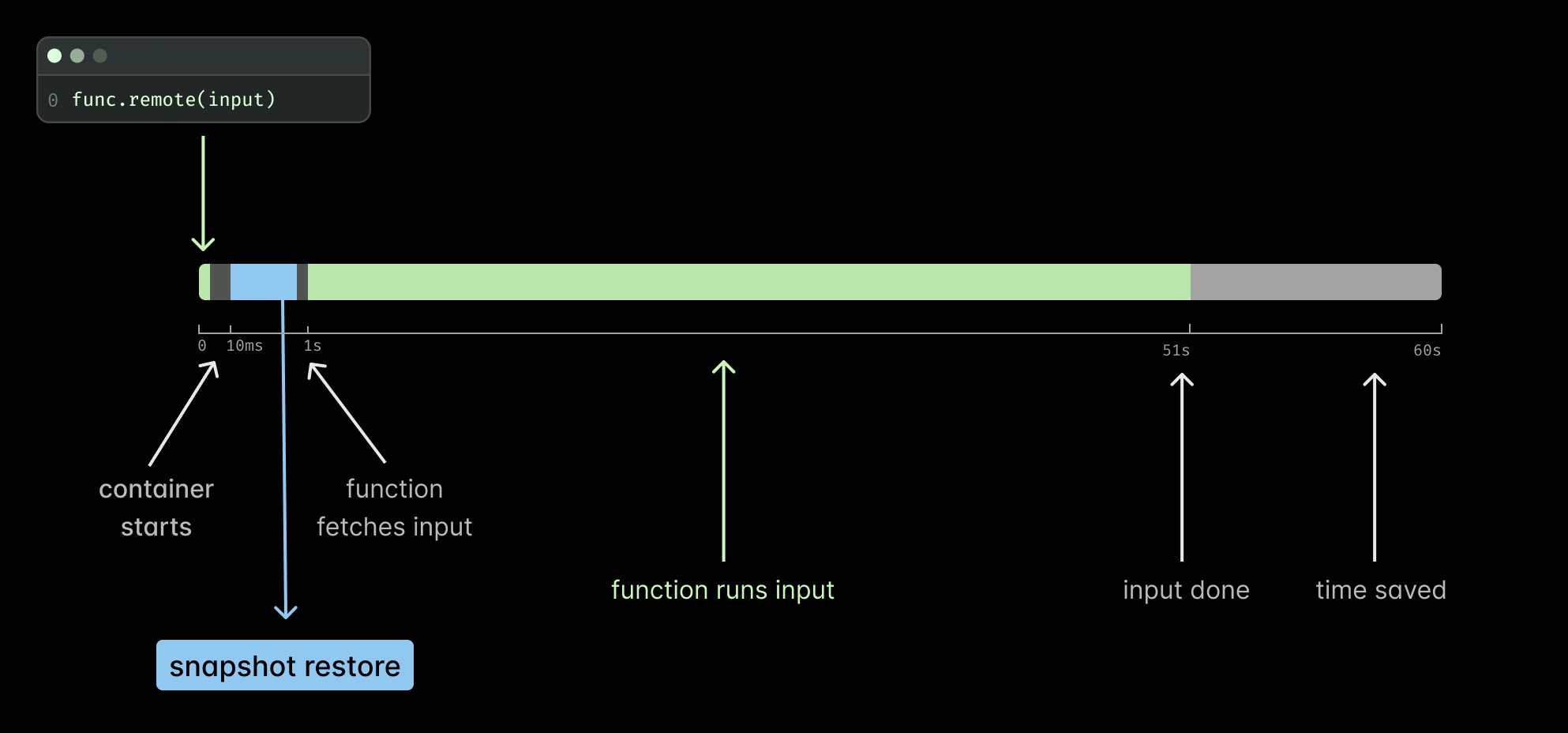
Read more details about this in our previous blog post, Memory Snapshots: Checkpoint/Restore for Sub-second Startup.
The GPU memory challenge
While memory snapshots significantly improved cold start times for many functions, they had an important limitation for GPU workloads—GPU state could not be included in the snapshot. Until now.
As we explained in our previous post, NVIDIA GPU state had to be created post-restore, requiring you to populate GPU memory, file descriptors, and CUDA sessions after restore had been completed. For example, this meant that you had to copy model weights from CPU to GPU after restore:
@app.cls(gpu="a10g", enable_memory_snapshot=True)
class GPT2:
@modal.enter(snap=True)
def load(self):
# Load model into CPU memory for snapshotting
self.model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
@modal.enter(snap=False)
def setup(self):
# Move to GPU after restore
self.model.to("cuda")This two-step approach worked—you could start containers up to 3x faster—but it wasn’t ideal. You needed to adopt a multi-stage approach: first copy data to CPU, then move to GPU. Otherwise, snapshots would break. You also had to ensure no program attempted to create CUDA sessions or check GPU availability (for example, by calling torch.cuda.is_available()), as this would also break snapshots.
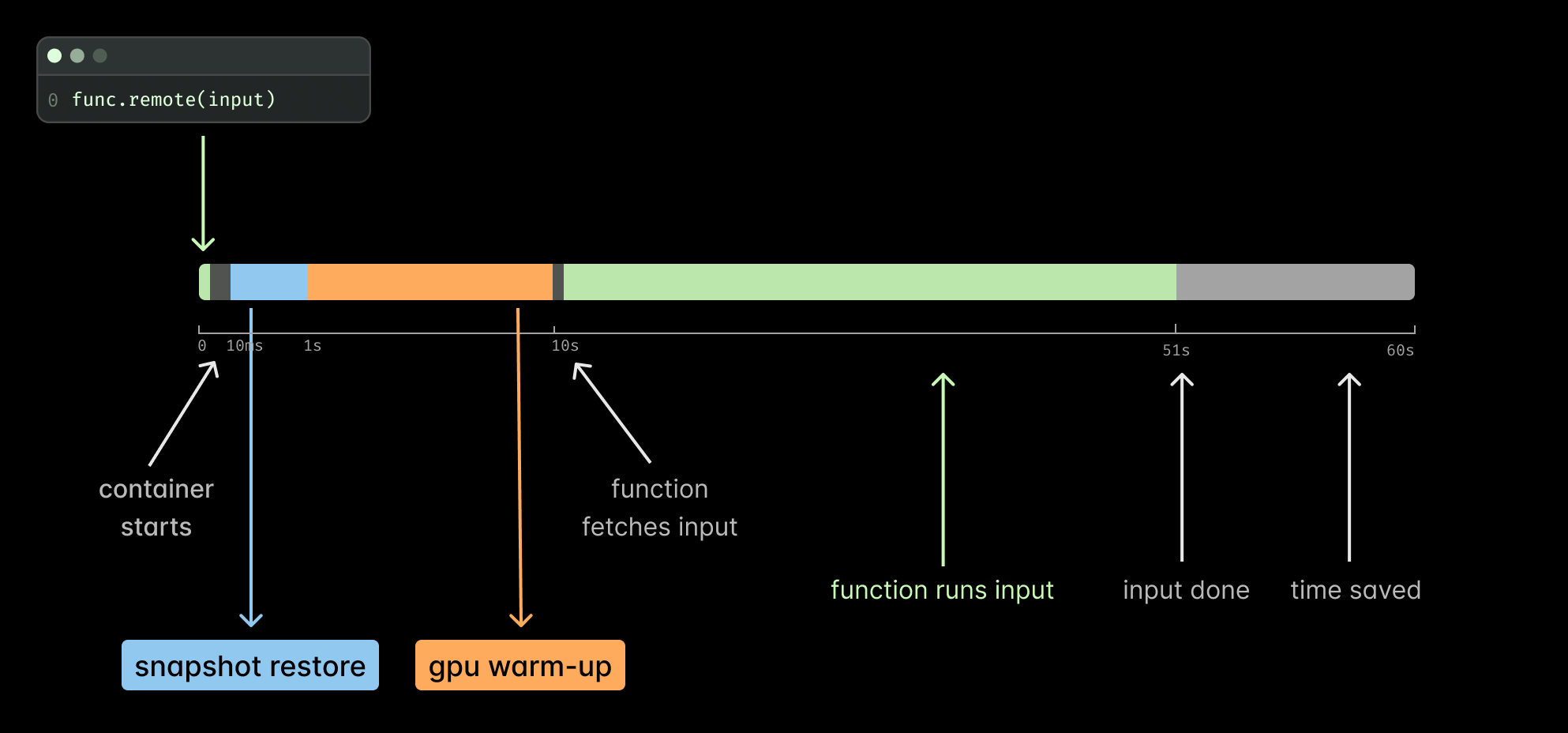
The approach was particularly ineffective for programs that warm up GPUs, such as those using torch.compile. In that case, you would still need to compile your model after loading it on the GPU because optimized code is hardware-dependent. Since torch.compile is an important optimization technique, we needed a better solution.
GPU memory snapshots address these limitations by copying GPU memory after operations have been performed. With this approach, torch.compile doesn’t need to run again because we restore the already-compiled model. The same applies to loaded CUDA kernels, captured CUDA graphs, and other expensive cold boot operations.
Enter CUDA checkpoint APIs: an interface for managing GPU memory
After the release of the CUDA checkpoint/restore API, now available on drivers in the 570 and 575 branches, we are now able to checkpoint and restore GPU memory transparently for many workloads. The API allows for us to checkpoint and restore CUDA state, including:
- Device memory contents (GPU vRAM), such as model weights
- CUDA kernels
- CUDA objects, like streams and contexts
- Memory mappings and their addresses
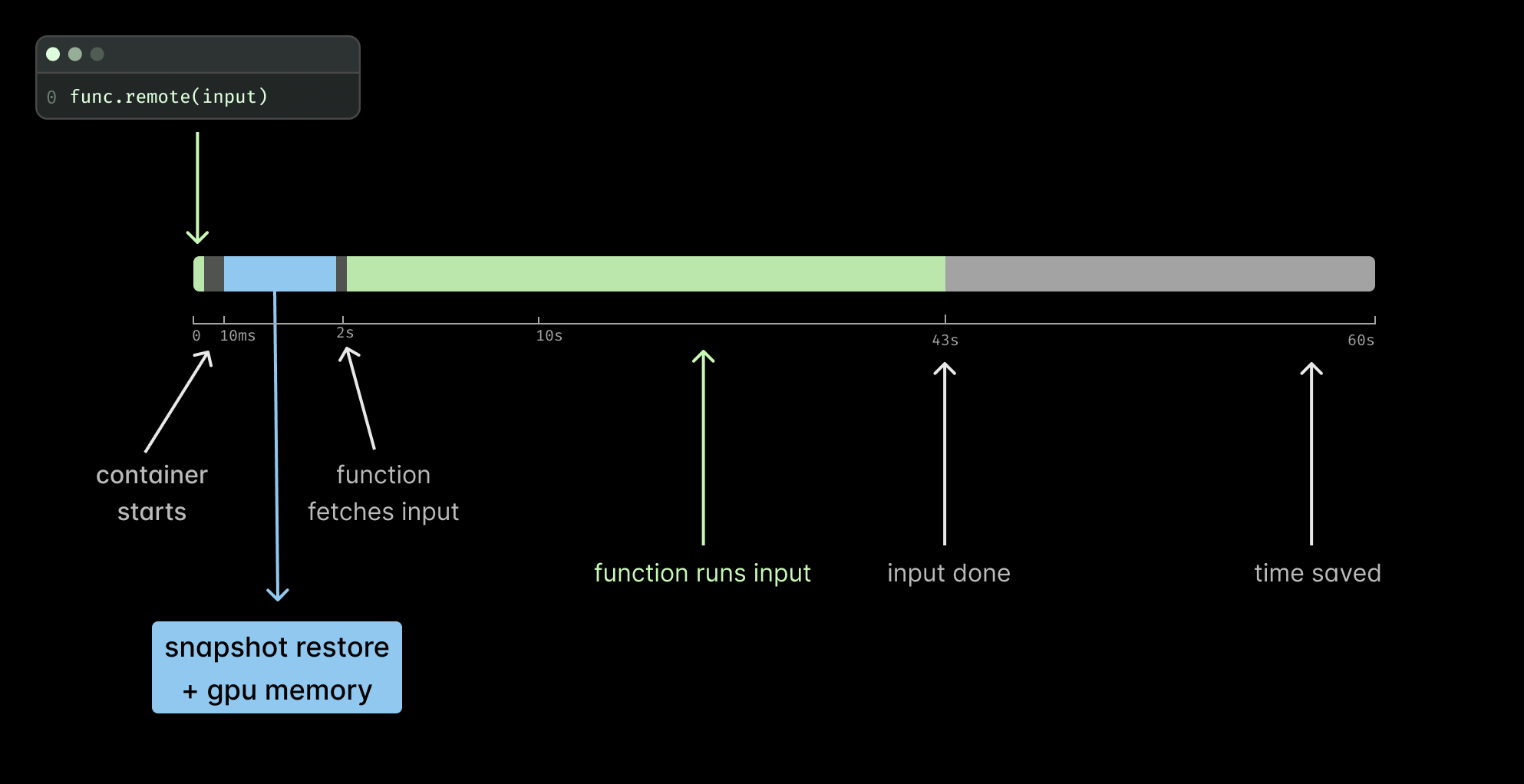
Similar to our CPU memory snapshots, GPU memory snapshots save the entire state of a container just before it’s about to accept a request. But now we’re also capturing the GPU state in the following steps:
- Lock CUDA processes (cuCheckpointProcessLock()): all new CUDA calls are locked and will never return and it will wait for all running calls (including CUDA Streams) to finish
- Checkpoint (cuCheckpointProcessCheckpoint()): We copy GPU memory and CUDA state to host memory, release GPU resources, and terminate CUDA sessions
To achieve reliable memory snapshotting, we must first enumerate all active CUDA sessions and their associated PIDs, then lock each session to prevent state changes during checkpointing. We continuously monitor process states via the CUDA API (see CUDA API documentation for state definitions) to detect errors, identify CUDA API deadlocks, and implement retry logic for failed checkpoint attempts. The system proceeds to full program memory snapshotting only after two conditions are satisfied: all processes have reached the CU_PROCESS_STATE_CHECKPOINTED state and no active CUDA sessions remain, ensuring memory consistency throughout the operation.
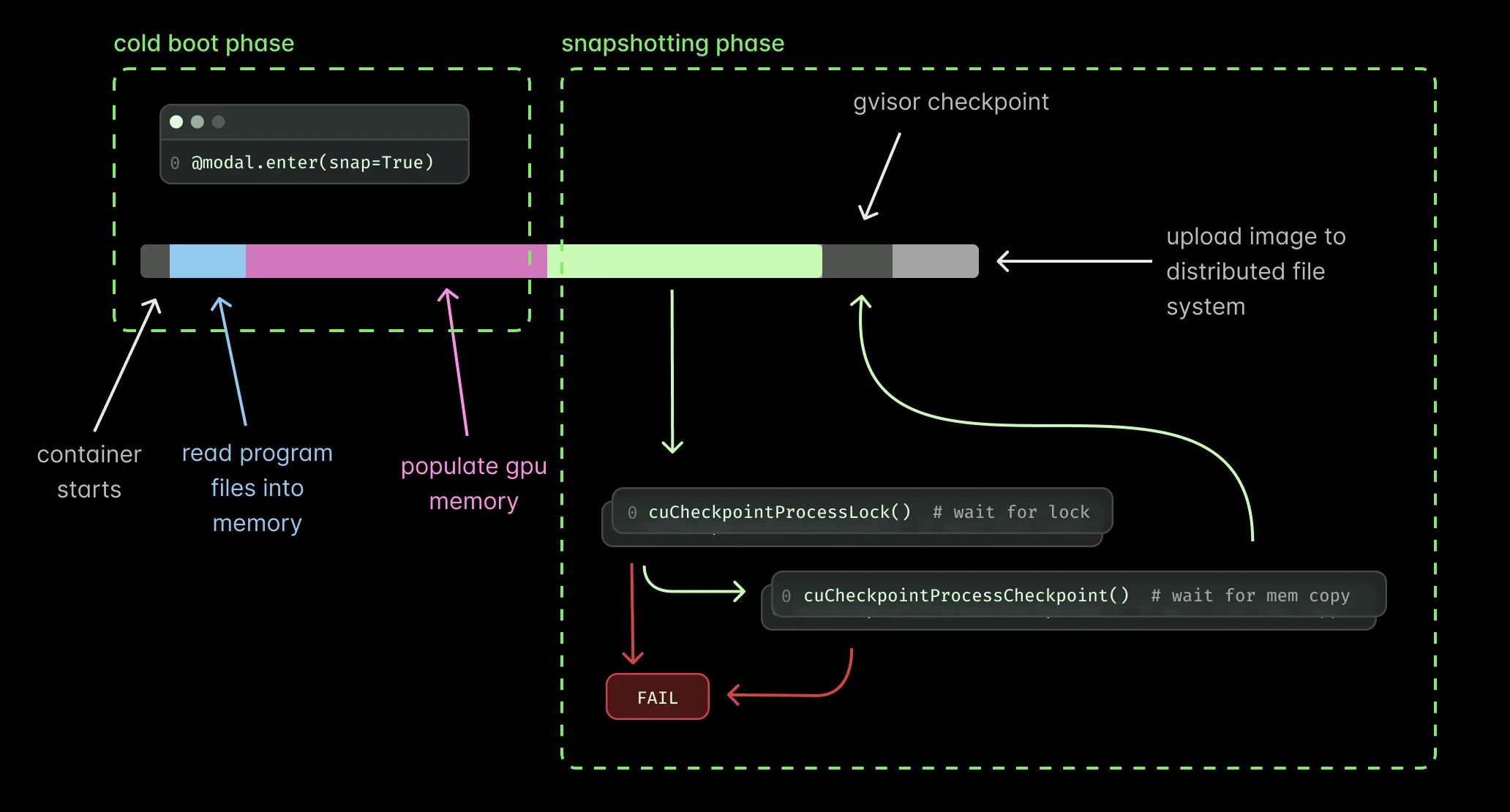
At this point we create a memory of the CPU memory—this time around including both CPU and GPU memory! During restore we do the process in reverse using cuCheckpointProcessRestore() and cuCheckpointProcessUnlock().
This process is fully integrated with our existing gVisor checkpoint/restore system. Just like with CPU snapshots, we handle compatibility concerns across different worker hosts, ensuring snapshots created on one machine can safely restore on another with compatible GPU hardware.
Performance: 10x faster cold boots
We have tested GPU memory snapshots in a variety of workloads showing great results across the board. We have observed Functions starting up to 10x times faster than baseline. This is really important because you can now really take advantage of serverless and scale down to zero while still maintaining great user experience. For example, imagine you are running the audio transcription model Parakeet using the NVIDIA NeMo framework. A Function would take about 20s (P0) to cold boot. Using GPU memory snapshots, the same Function can now take as low as 2s (P0).
A fully-loaded ViT inference function that previously took 8.5s (P0) seconds with CPU-only snapshots and torch.compile now takes 2.25s (P0). We entirely skip the torch.compile operation and use the compiled artifacts. Similarly, vLLM running Qwen2.5-0.5B-Instruct would previously take 45s (P0) to startup and now takes 5s (P0).
LTX
ViT torch.compile
Sentence Transformers
Qwen-VL 7b
WhisperX
Chatterbox
NVIDIA Parakeet
vLLM
Using GPU memory snapshots
Adding GPU memory snapshots to your Modal Apps is as simple as setting a new flag. If you’re already using memory snapshots, just add experimental_options={"enable_gpu_snapshot": True}.
@app.cls(
gpu="a10g",
enable_memory_snapshot=True,
experimental_options={"enable_gpu_snapshot": True}
)
class ImageClassifier:
@modal.enter(snap=True)
def load(self):
self.processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
self.model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
self.model = torch.compile(self.model)
@modal.method()
def run(self):
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processed_input = self.processor(image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = self.model(**processed_input)The most significant API change is that you no longer need separate snap=True and snap=False lifecycle methods. Your model can be loaded directly to the GPU, and the entire GPU state will be snapshotted.
Try it now
GPU memory snapshots are available in alpha at Modal. We are still exploring the limitations of this feature; try it for yourself and let us know how it goes.
Acknowledgements
Many thanks to the NVIDIA / CUDA for adding checkpoint / restore to the CUDA API and to the maintainers of the cuda-checkpoint project, which made it easy to test the new APIs in different workloads. Also, thanks to the amazing people at the Google gVisor team who continuously develop the runtime to be extensible, high-performance, and secure.