Top embedding models for RAG
If you’re building a Retrieval-Augmented Generation (RAG) system, choosing the right embedding model is crucial for good performance.
This is because the embedding model directly affects the quality and relevance of retrieved information. Different models excel at capturing semantic relationships and contextual nuances.
For example, an embedding model trained on medical data will interpret the phrase “she scrubbed” differently than a general-purpose model.
Top embedding models for RAG
Some top embedding models to consider when you are evaluating for RAG are:
intfloat/e5-large-v2: This model is designed for efficient embedding generation and is suitable for various NLP tasks.
Salesforce/SFR-Embedding-2_R: Developed by Salesforce, this model enhances text retrieval and semantic search capabilities.
Alibaba-NLP/gte-Qwen2-7B-instruct: A high-performance model with 7 billion parameters, ideal for complex embedding tasks.
Alibaba-NLP/gte-Qwen2-1.5B-instruct: This 1.5 billion parameter model offers a balance between performance and resource requirements.
intfloat/multilingual-e5-large-instruct: A 0.5 billion parameter multilingual model that supports various languages.
jinaai/jina-embeddings-v2-base-en: A 0.1 billion parameter model designed for English text embeddings.
jinaai/jina-embeddings-v2-base-code: This model, also with 0.1 billion parameters, is optimized for code embeddings.
BAAI/bge-base-en-v1.5: This model is specifically designed for English embedding tasks and is part of the BGE family.
The MTEB leaderboard: A benchmark for embedding models
The Massive Text Embedding Benchmark (MTEB) leaderboard on Hugging Face evaluates embedding models across various tasks, providing a standardized comparison of performance in classification, clustering, retrieval, and semantic textual similarity.
While the MTEB leaderboard is a valuable resource, it’s important to remember that a high ranking does not necessarily mean a model is the best fit for every specific use case.
The only definitive way to determine whether an embedding model will perform well for your needs is to experiment with it and optimize it alongside various other parameters in a RAG system. Here are some general tips to using the MTEB leaderboard:
- Retrieval score: Make sure to click into the “retrieval” task tab, and select the language that your use case is in.
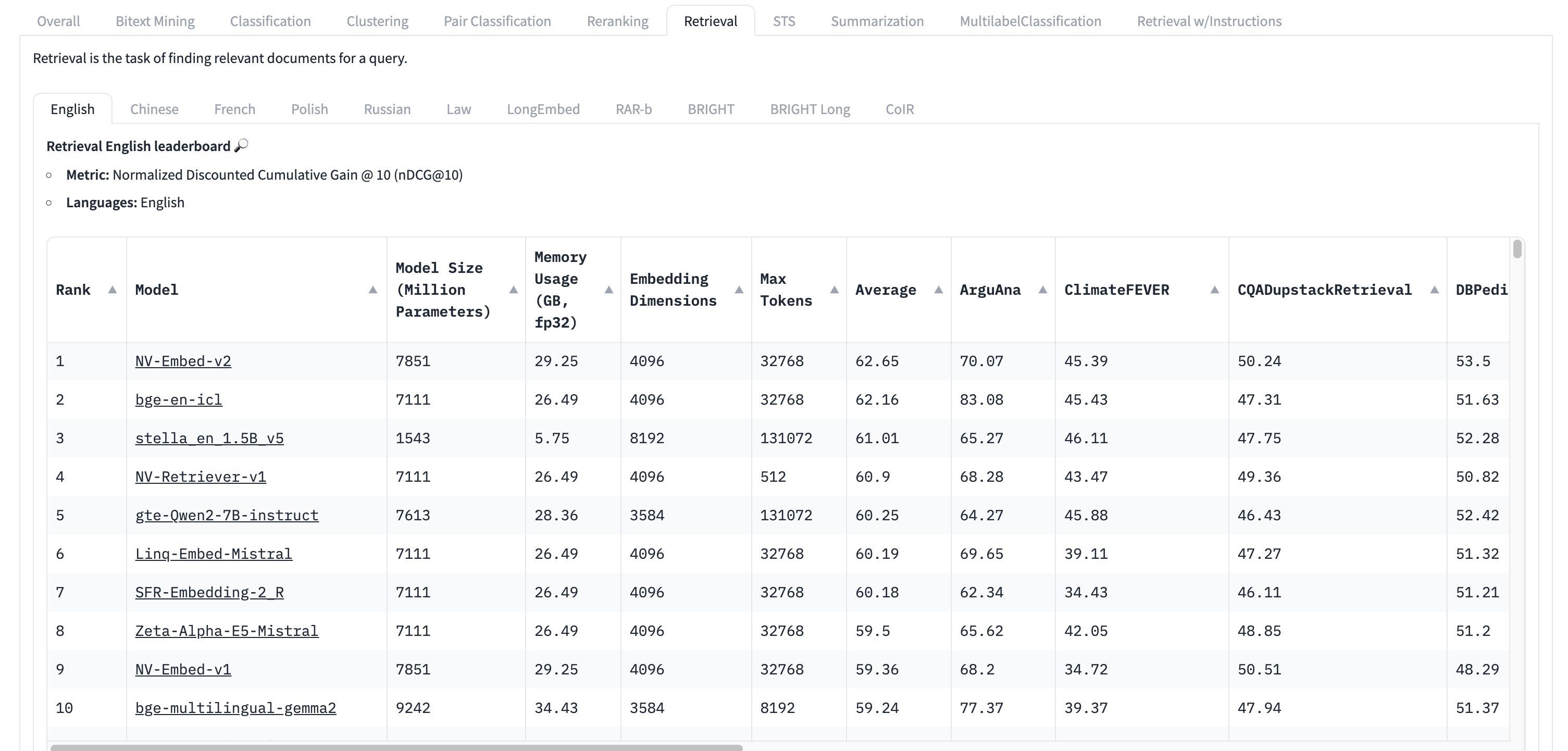
- Sequence Length: This indicates how many tokens a model can process into a single embedding. It’s best to limit input to a paragraph of text, with models supporting up to 512 tokens being sufficient for most cases.
- Model Size: The model’s size impacts usability. The larger the model, the more expensive it is to run and the higher the latency. As a rule of thumb, start with a small model (~500 million parameters) and work up from there.
How to serve embedding models fast
To use embedding models effectively in production environments, it’s essential to employ efficient serving frameworks. The text-embeddings-inference library from Hugging Face is an excellent choice for fast and scalable embedding model deployment.
To run a text embedding model with text-embeddings-inference on Modal’s serverless computing platform, follow this example.
Fine-tuning embedding models
Fine-tuning embedding models can significantly enhance their performance for specific use cases. By taking a pre-trained model and training it further on your own dataset, you can tailor the embeddings to better capture the nuances and characteristics relevant to your application. For a writeup for how you can fine-tune an embedding model on Modal, and get better performance than proprietary models, read our blog post here.