Best open-source LLMs in 2025
These days, it seems like hardly a week goes by without a tech giant or AI startup announcing a new open-source large language model and claiming that it’s best in class.
With so many options available, it can be overwhelming to navigate the landscape and find the best open-source LLM for your specific use case.
In this blog post, we’ll explore some of the best open-source LLMs, evaluating them based on factors such as performance, size, ease of use, and suitability for various tasks like writing, coding, and fine-tuning. We’ll also discuss where to find and run these models, including how to serve them efficiently using Modal.
Table of contents
- What is an open-source LLM and why would you use one?
- How to evaluate open-source LLMs
- Best overall open-source LLM: DeepSeek-V3
- Best open-source LLM for chat: Meta-LLama-3.1-8B-Instruct
- Best open-source LLM for coding: Qwen2.5-Coder-32B-Instruct
- Best open-source LLM for fine-tuning: Mixtral-8x7B-Instruct
- Where to find open-source LLMs
- Where to run open-source LLMs
- How to serve open-source LLMs blazingly fast
- Run open-source LLMs on Modal
What is an open-source LLM and why would you use one?
An open-source language model (LLM) is a model that is made available to the public for free, with its weights and architecture openly accessible.
Versus closed-source and proprietary LLMs like OpenAI’s GPT and Anthropic’s Claude, open-source LLMs offer several advantages:
Open licenses:
Open-source LLMs are released under permissive licenses like Apache 2.0 and MIT, allowing developers to use, modify, and distribute the models freely.
Publicly available weights:
The pre-trained weights of open-source LLMs are readily available, enabling developers to fine-tune the models for specific tasks without starting from scratch.
Cheaper:
There are a lot of caveats here (OpenAI GPT-3.5 is the most cost-effective option for many, many use cases), but if you have high-volume use cases with consistent load, you can save money by running open-source LLMs on your own infrastructure or through cost-effective cloud providers.
For example, Ramp recently cut their infrastructure costs for automated receipt processing by 79% by switching from OpenAI to running an open-source LLM on Modal.
Fast inference speeds and no rate-limiting:
Open-source LLMs also offer the potential for faster inference speeds, as you have control over the hardware and optimization techniques employed. Additionally, you are not subject to the rate limits and usage restrictions often imposed by commercial LLM providers.
With the plethora of open-source LLMs now coming out, there’s a lot of noise, and not every new model warrants your attention. You should consider a new open-source LLM when:
- It achieves state-of-the-art performance in specific dimensions, such as accuracy, efficiency, or model size, compared to existing open-source models.
- It surpasses the performance of cutting-edge proprietary models, such as GPT-4/5.
- It offers performance comparable to cutting-edge proprietary models while being significantly more cost-effective (e.g., 10x cheaper).
How to evaluate open-source LLMs
When evaluating open-source LLMs, consider the following factors:
- Quality: How accurate and coherent are the model’s outputs?
While a lot of open-source LLMs claim that they are the leader on various benchmarks, we recommend just trying out the models on prompts that resemble your specific use case.
- Speed: How quickly can the model generate outputs?
Models of comparable size should have similar inference speeds, but this can still vary based on optimization techniques and inference providers.
In general, you should be looking at something like 30-50 tokens/second for a 70B model, and 100-200 tokens/second for a 7B model.
- Cost: What are the costs associated with running the model?
While open-source LLMs are ostensibly “free” to use, you still need to consider the cost of running the model on your own infrastructure or through a cloud provider.
Here, you should consider not only the server time - whether that’s spinning up your own servers or using one of the newer serverless providers like Modal - but also the cost of maintenance, migration, and developer training.
There are a number of sites that aggregate the metrics mentioned above for the various open-source LLMs and cloud providers.
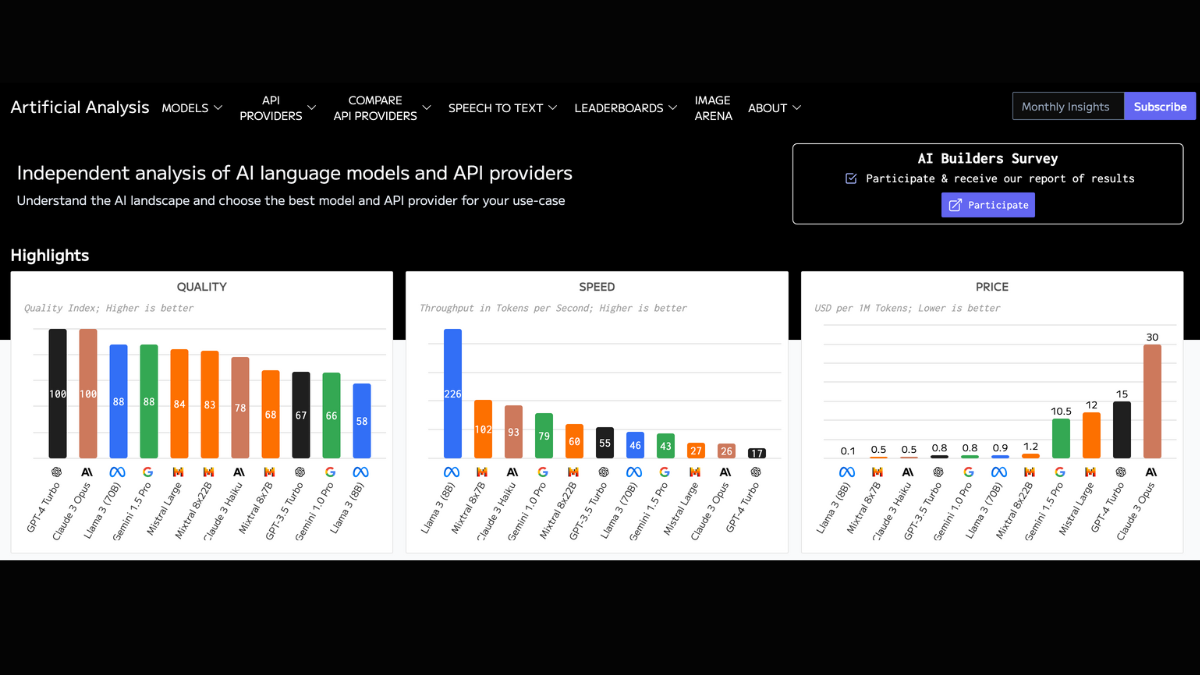
What’s the difference between the 7B and the 70B versions?
When considering open-source LLMs, you’ll often come across models with the same name but different parameter counts, such as Llama3-8B and Llama3-70B. These numbers refer to the number of relationships the AI can build internally with the training data.
A 70B model has 10 times the number of internal inter-token relationships compared to a 7B model, allowing it to capture more subtle patterns and nuances in the data. While larger models often exhibit better performance, they also come with higher computational costs and longer inference times.
We recommend that you start out by trying the 7B models, which can generally run on consumer hardware, even mobile phones, and if the models prove insufficient for your use case, then move on to the larger models.
What’s the difference between Instruct vs. non-Instruct versions?
Open-source LLMs can come in both instruct and non-instruct versions. Instruct models are fine-tuned to follow instructions and are generally more suitable for task-oriented applications, while non-instruct models are more open-ended and can be used for creative generation tasks.
Best overall open-source LLM
DeepSeek-V3 is roughly comparable to GPT-4o in terms of quality, and excels at general writing, coding, and reasoning tasks.
Users report that it is not as good for coding as Claude-3.5-Sonnet, but it is significantly cheaper to run.
You can try a hosted version of DeepSeek-V3 on DeepSeek’s website.
Best open-source LLM for chat
Meta-LLama-3.1-8B-Instruct is designed for conversational applications, making it a strong choice for chatbots and other AI assistants.
It excels at general task following and content generation.
Best open-source LLM for math
DeepSeek-R1-Distill-Qwen-32B is a 32B parameter distilled version of the DeepSeek-R1 model, with very good performance on general math.
DeepSeek-R1-Distill-Qwen-32B is a smaller version of the full DeepSeek-R1 model that is more efficient and cheaper to run (Qwen-32B fine-tuned on hundreds of thousands of samples of DeepSeek-R1 outputs).
Best open-source LLM for coding
Qwen2.5-Coder-32B-Instruct is a 32B parameter Qwen model that is fine-tuned for coding tasks.
It has competitive performance with GPT-4o on code generation and code repair, and is familiar with 40+ programming languages.
Best open-source LLM for fine-tuning
If you plan to fine-tune your LLM, we recommend:
A larger model with a mixture-of-experts architecture that allows for efficient fine-tuning.
You can fine-tune Mixtral on Modal Labs using our fine-tuning template.
Where to find open-source LLMs
One of the best places to find open-source LLMs is Hugging Face. Hugging Face is a community-driven platform that hosts a wide variety of open-source models, including LLMs, and provides tools for easy integration and fine-tuning.
Where to run open-source LLMs
There are several options for running open-source LLMs, including:
- Cloud platforms like AWS, Google Cloud, and Azure
- On-premise hardware
- Specialized AI platforms like Modal, Together.ai, and Fireworks.ai
How to serve open-source LLMs blazingly fast
To serve your open-source LLM fast, you will likely need to use one of the below LLM inference engines. The two best engines in 2025 are:
- TensorRT-LLM: A platform for optimizing and accelerating AI models on NVIDIA GPUs. Best performance but annoying to set up. To run an open-source LLM with TensorRT-LLM on Modal, check out our TensorRT-LLM example.
- vLLM: UC Berkeley’s open-source option, relatively easy to use. To run an open-source LLM with vLLM on Modal, check out our example.
Run open-source LLMs on Modal
Modal is a serverless cloud computing platform that makes it easy to run open-source LLMs in the cloud. With Modal, you can:
- Easily deploy and scale open-source LLMs, with less waste. Modal automatically spins up new containers when you have more demand and scales down when you have less.
- Access powerful GPU resources on-demand.
To get started with running open-source LLMs on Modal, check out our documentation and examples.