Audio Inference
Build flexible pipelines to transcribe audio, generate voice or synthesize high-fidelity music
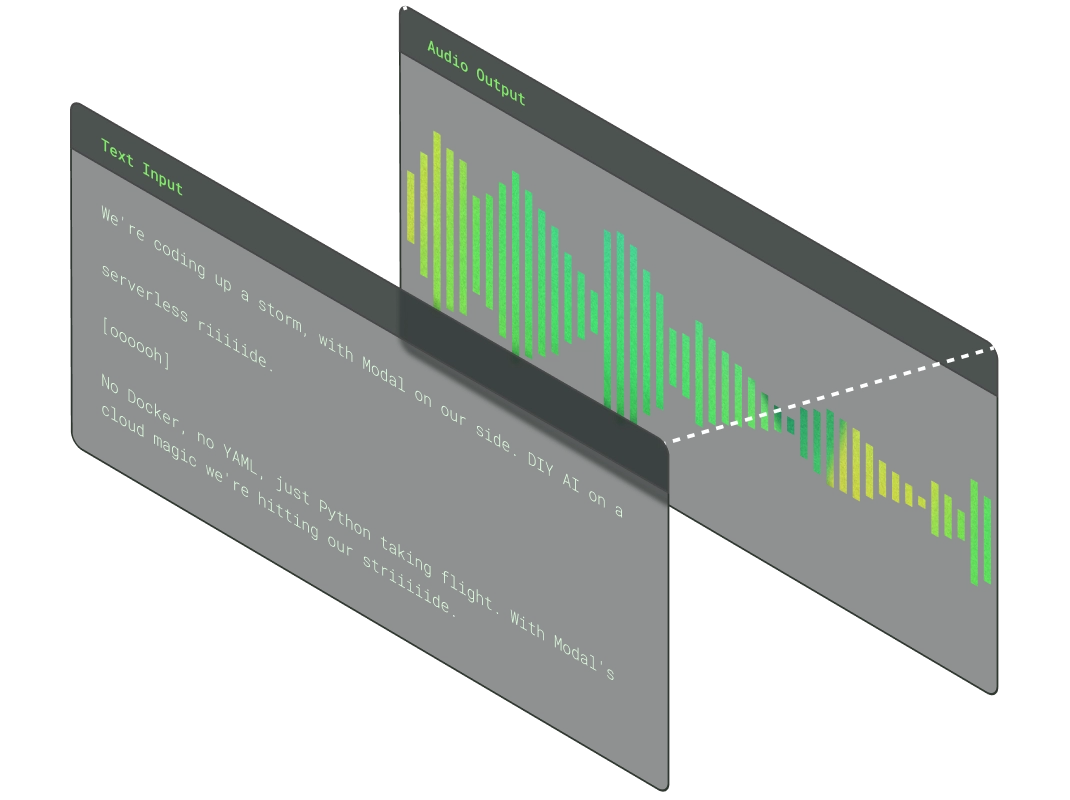
Build flexible pipelines to transcribe audio, generate voice or synthesize high-fidelity music
"Suno has developed proprietary state-of-the-art models that generate music and speech using AI. Modal's superb developer experience enables our team to ship new models to production quickly, and with and confidence we'll scale to thousands of simultaneous users."
"At Phonic, we train our own proprietary models for audio generation. We moved all our large-scale audio processing batch jobs to Modal. Our engineers are ecstatic with the result – we can run at a much larger scale than before, no longer have to babysit our batch jobs, and we can ship much faster."
"When Substack launched a feature for AI-powered audio transcriptions. The data team picked Modal because it makes it easy to write code that runs on 100s of GPUs in parallel, transcribing podcasts in a fraction of the time."
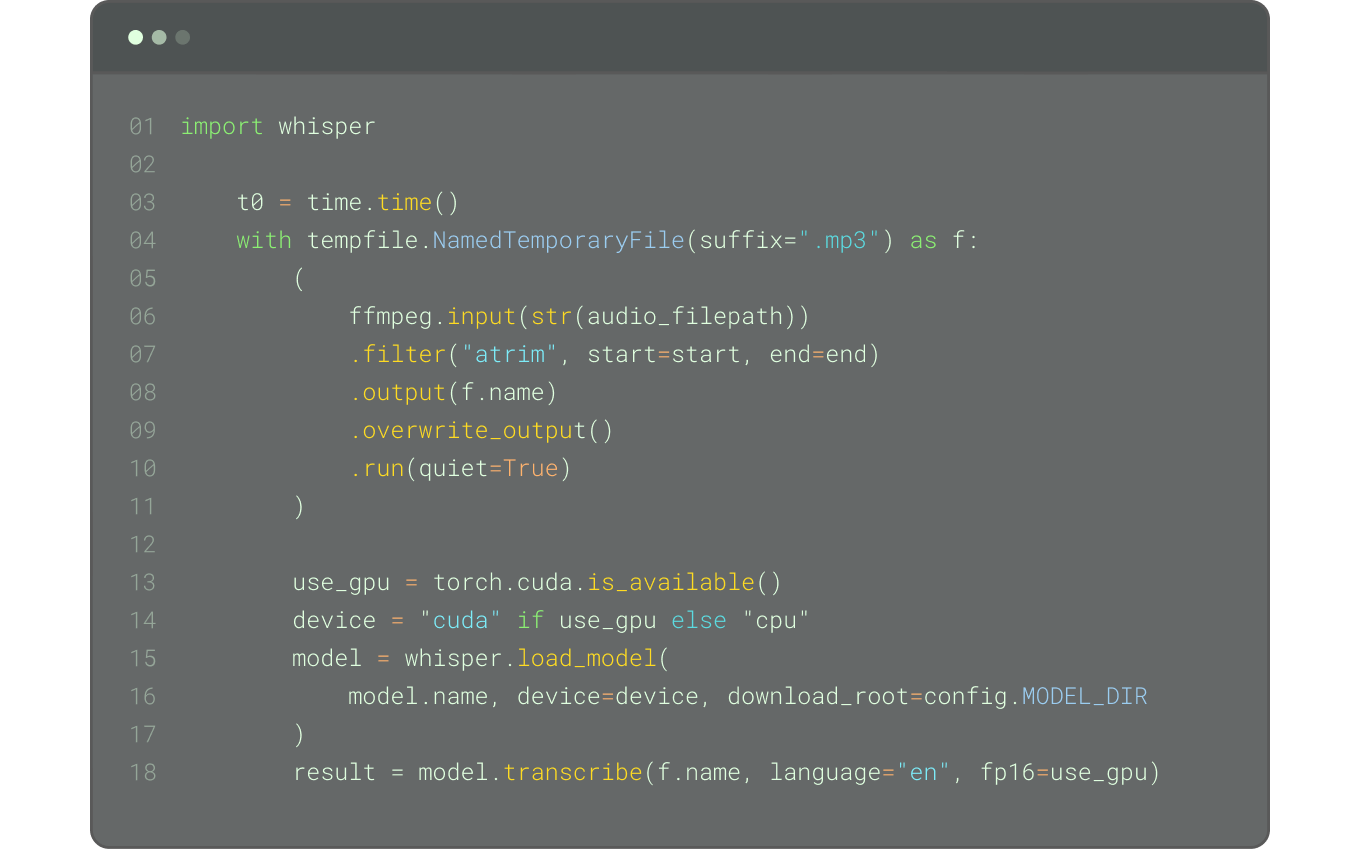
Get faster speeds at lower costs compared to popular transcription APIs like AssemblyAI and Deepgram by leveraging open-source models on Modal.
Distribute transcription tasks across hundreds of containers simultaneously.
Deploy text-to-speech models like XTTS directly on Modal's platform.
Tap into Modal's fleet of A100 and H100 GPUs for memory-intensive voice models.
Generate speech on-demand without lengthy startup times with our optimized container file system and engine.
Ship your first app in
minutes.
$30 / month free compute